空间智能新高度:港科大谭平团队SAIL-Recon突破万帧级图像大规模3D场景重建Transformer
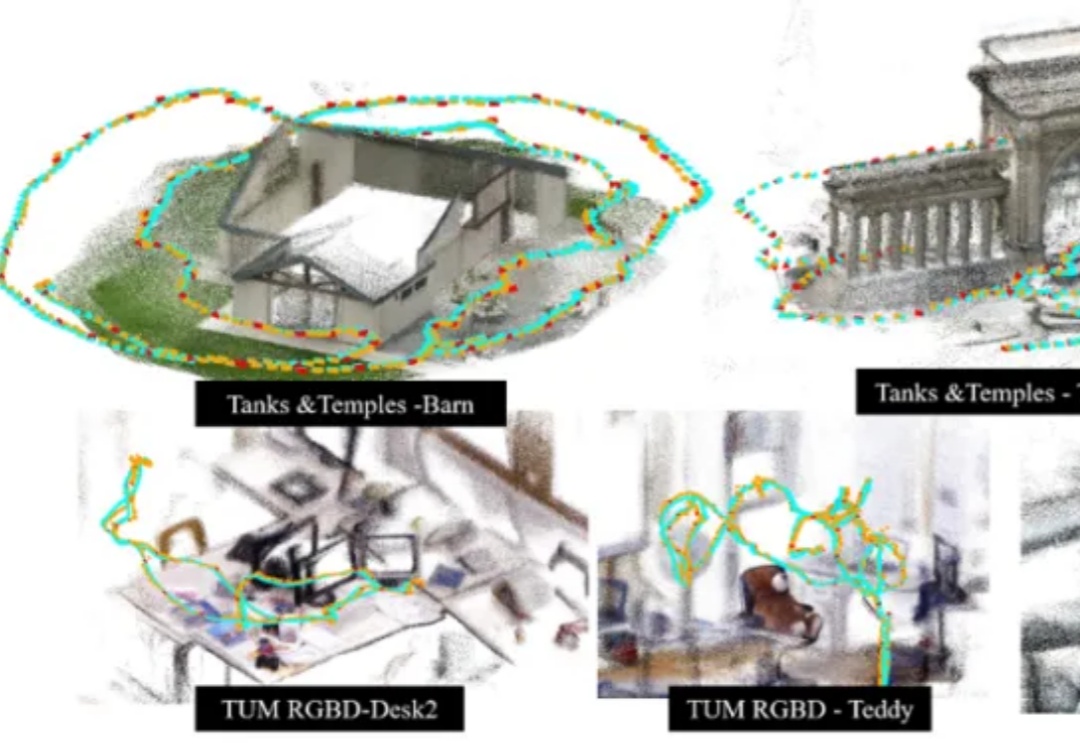
空间智能新高度:港科大谭平团队SAIL-Recon突破万帧级图像大规模3D场景重建Transformer香港科技大学谭平教授团队与地平线(Horizon Robotics)团队最新发布了一项 3D 场景表征与大规模重建新方法 SAIL-Recon,通过锚点图建立构建场景全局隐式表征,突破现有 VGGT 基础模型对于大规模视觉定位与 3D 重建的处理能力瓶颈,实现万帧级的场景表征抽取与定位重建,将空间智能「3D 表征与建模」前沿推向一个新的高度。
来自主题: AI技术研报
8848 点击 2025-09-08 10:19