

Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强
Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度
来自主题: AI产品测评
6556 点击 2025-04-20 20:47
Nemotron-H模型混合了Transformer和Mamba架构,使长文本推理速度提升3倍,同时还能保持高性能,开源版本包括8B和56B尺寸。训练过程采用FP8训练和压缩技术,进一步提高了20%推理速度

基于Transformer的自回归架构在语言建模上取得了显著成功,但在图像生成领域,扩散模型凭借强大的生成质量和可控性占据了主导地位。

4 月 14 日,谷歌首席科学家 Jeff Dean 在苏黎世联邦理工学院举办的信息学研讨会上发表了一场演讲,主题为「AI 的重要趋势:我们是如何走到今天的,我们现在能做什么,以及我们如何塑造 AI 的未来?」

Transformer架构主导着生成式AI浪潮的当下,但它并非十全十美,也并非没有改写者。

要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。

芯片架构设计的首要原则是明确取舍,决定哪些领域我们不追求卓越。

2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。
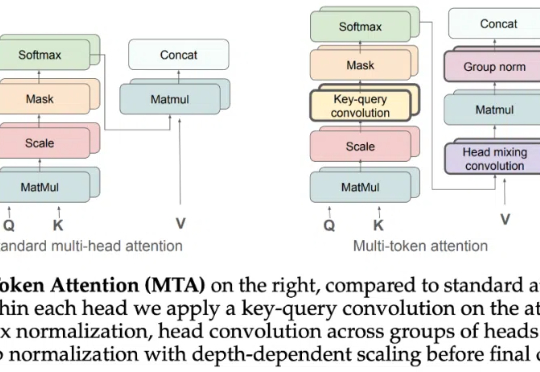
Attention 还在卷自己。

简单的任务,传统的Transformer却错误率极高。Meta FAIR团队重磅推出多token注意力机制(MTA),精准捕捉复杂信息,带来模型性能飞升!

DeepMind内部研究要「封箱」了!为保谷歌在AI竞赛领先优势,生成式AI相关论文设定6个月禁发期。不仅如此,创新成果不发,Gemini短板不提。