
模型砍掉一大半,准确率反升15%!华科&阿里安全新研究实现ViT近乎无损的类特定压缩|ICLR'26
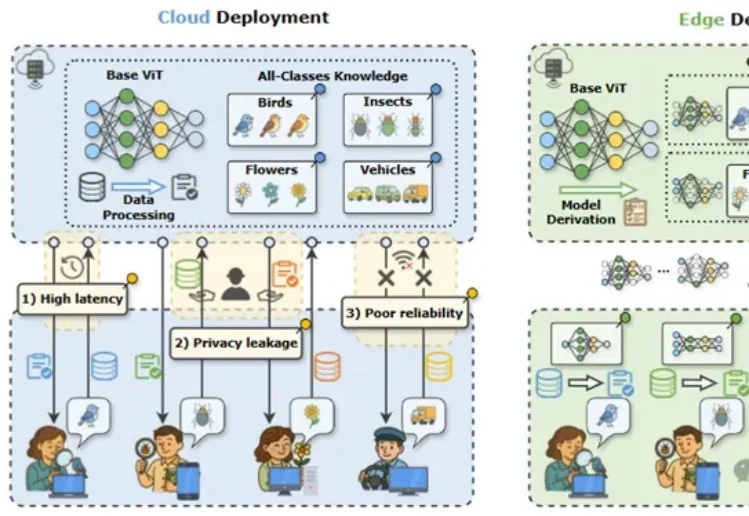
模型砍掉一大半,准确率反升15%!华科&阿里安全新研究实现ViT近乎无损的类特定压缩|ICLR'26近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
来自主题: AI技术研报
5781 点击 2026-03-06 09:32
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。
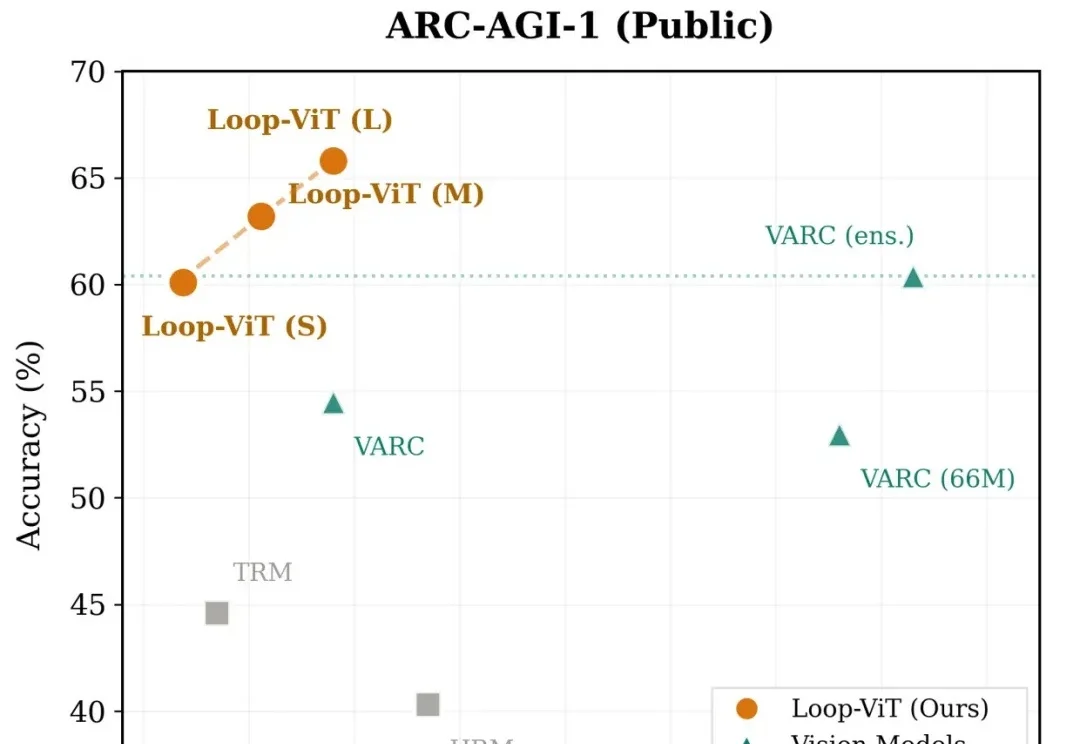
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。

关注我比较久的朋友可能都知道,我用 AI 有个习惯。
大家好,我是鲁工。 上周发布了一篇关于如何在Antigravity中组合Claude Opus 4.5和Gemini 3 Pro进行交叉验证的文章,读者反馈不错。
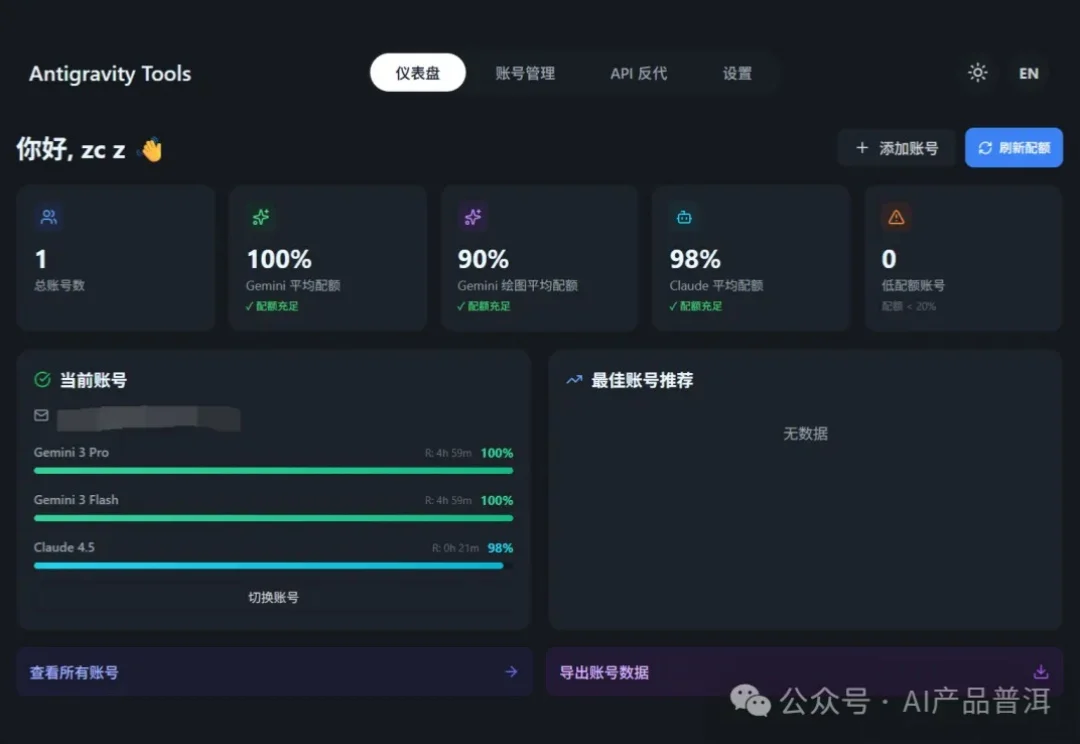
上上周跟大家盘了 Gemini 学生教育优惠。
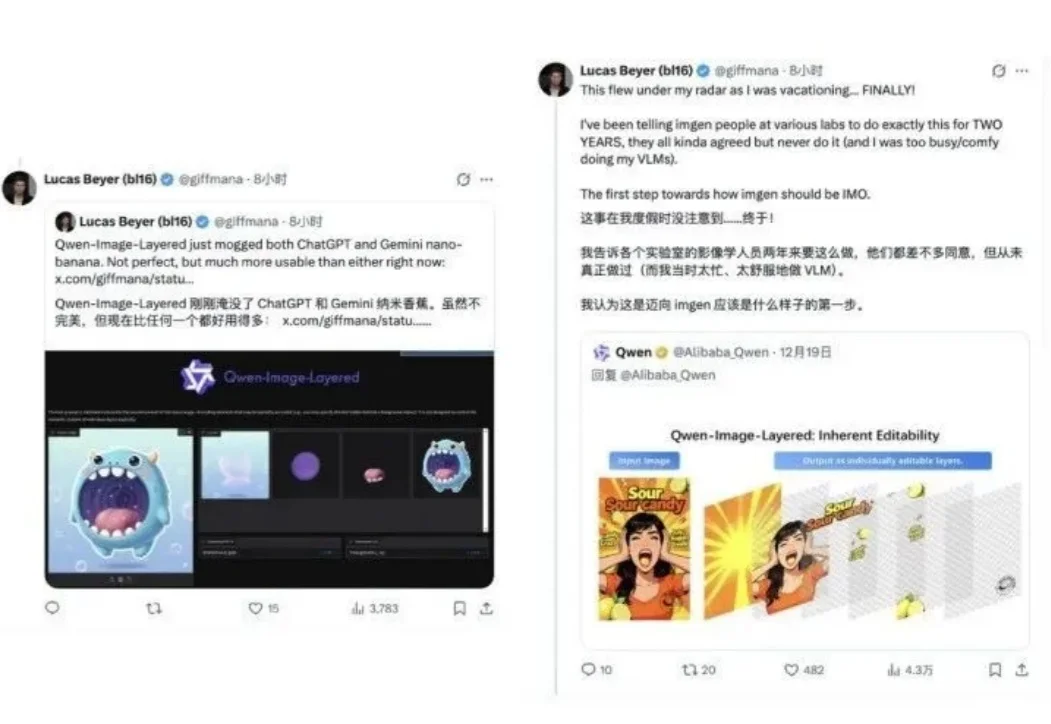
太香了太香了,妥妥完爆ChatGPT和Nano Banana!

最初只是我写了一个特别好玩的 prompt,那个 prompt 是一个代入修仙世界的文字游戏,没想到这个 prompt 会成为所有故事的起点。后来我们把 prompt 包了一下,上了个简单的网页,实际上开发1周,形态是chatbox,纯文本+流式输出,有选项、死亡状态,非常简单的一波流的小玩具,但是也收到了很多正向反馈。

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。
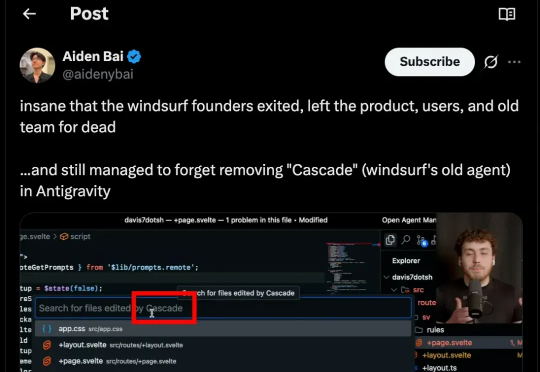
Google 前天发布了 Antigravity,一款号称“下一代 agentic 开发平台”的全新 IDE。官方宣传强调它能规划、执行、验证整个开发流程,似乎代表着 AI 编程进入了新的阶段。然而,最早一批上手使用的开发者却纷纷吐槽:任务跑着跑着就因“模型过载”中断,信用额度几十分钟内耗尽,连完整测试都难以完成,体验堪称“开局即崩”。

如果说过去一年里,AI 让开发者生产力翻倍,那么如今它也开始以同样的速度放大风险。 上周,Google 刚刚推出的基于 Gemini 的全新 AI 编码工具 Antigravity,上线不到 24 小时便被一名安全研究员攻破,指出它存在严重的安全Bug。