
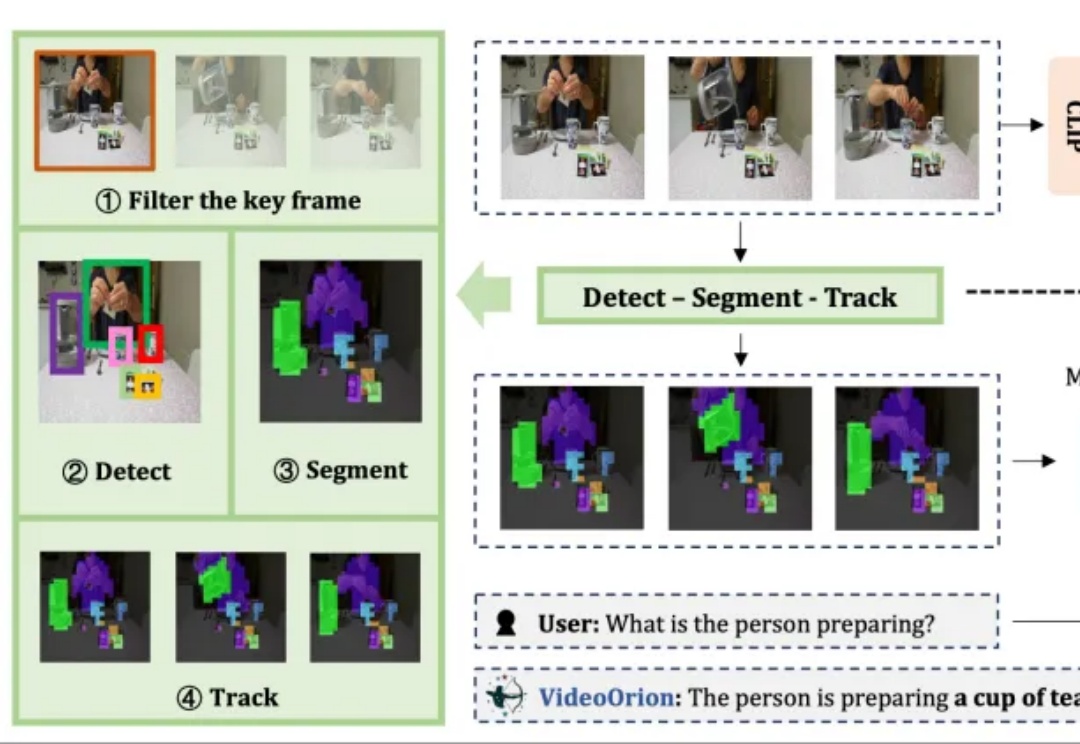
视频大模型新基元:用Object Tokens重塑细节感知与指代理解
视频大模型新基元:用Object Tokens重塑细节感知与指代理解被顶会ICCV 2025以554高分接收的视频理解框架来了!
来自主题: AI技术研报
7637 点击 2025-11-28 09:24
被顶会ICCV 2025以554高分接收的视频理解框架来了!
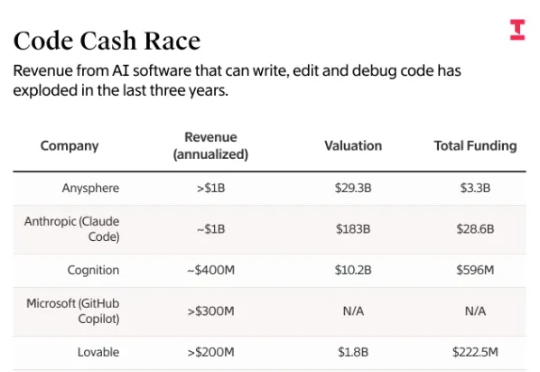
由Anysphere 的 Cursor 和 Anthropic 的 Claude Code 等 AI 编程工具共同创造的收入已突破 31 亿美元。据直接了解 Cognition 财务状况的人士透露,这其中包括 Cognition 的 Devin 编程代理产生的近 4 亿美元年化收入——这一数字此前未被报道过。

AI闹推出了新栏目 AI 实践派(AI Practitioners)

Xsignal AI Holo(AI 全息)数据库显示,中国移动互联网的AI落地已彻底分化为两条路径:以微信、抖音的AI搜索为代表的“AI Overview (AIO)”旨在筑起认知的长城,将决策锁定在生态内部;而以QQ浏览器QBot为代表的“Agent in App (AIA)”则正演变为主动式的“数字员工”,重构服务分发的主权。
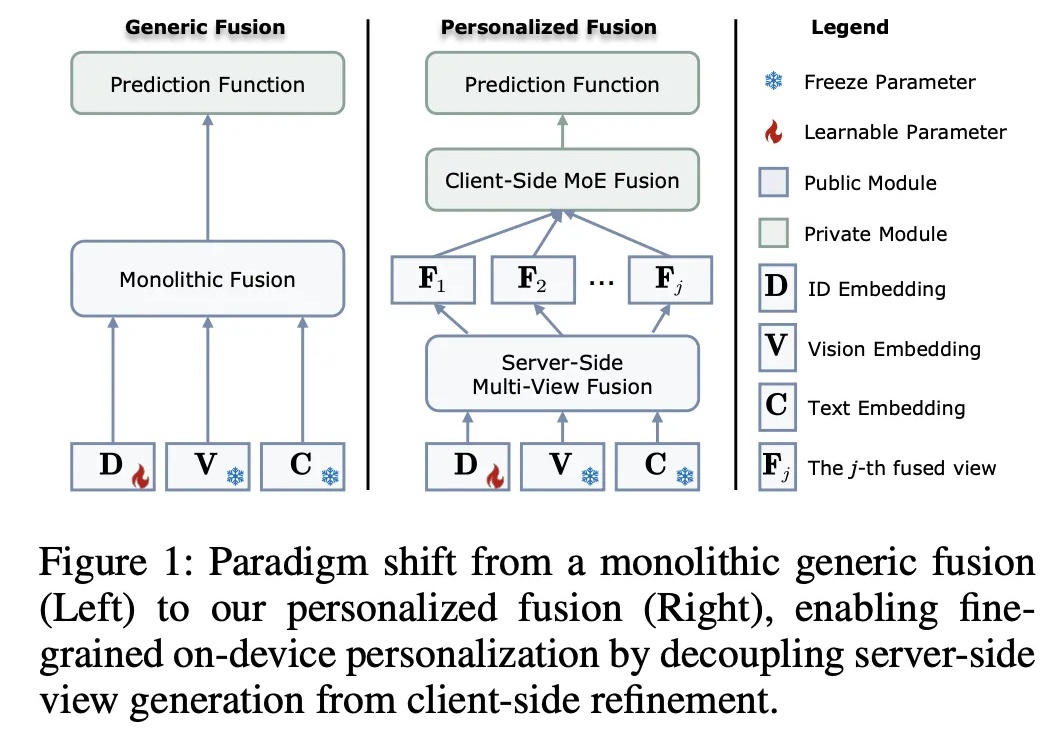
在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。

前两天,Google发了一个非常有趣的论文: 《Nested Learning: The Illusion of Deep Learning Architectures》

扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。
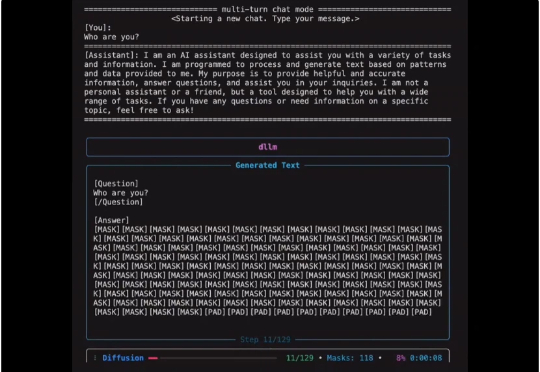
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。

2000 亿参数、3 万块人民币、128GB 内存,这台被称作「全球最小超算」的机器,真的能让我们在桌面上跑起大模型吗? 向左滑动查看更多内容,图片来自 x@nvidia 前段时间,黄仁勋正式把这台超

今天,来自快手可灵团队和香港城市大学的研究者们,正在尝试打破这一界限。他们提出了一个全新的任务范式——「视频作为答案」,并发布了相应模型VANS。而这项工作则开创性地提出了Video-Next Event Prediction任务,要求模型直接生成一段动态视频作为回答。