# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前两天,Google发了一个非常有趣的论文:
《Nested Learning: The Illusion of Deep Learning Architectures》

非常有意思,很多人戏称,这篇论文,是《Attention is all you need (V2)》。

《Attention is all you need》,神中神。
这篇论文提出的Transformer架构,现在是几乎所有大模型的底层,比如GPT、Gemini、Claude、Qwen、DeepSeek等等等等。
2017 年的论文,到了 2025 年,引用次数已经 17 万+,进入 21 世纪被引用最多的论文前十名,被正式称为现代 AI 的奠基工作之一。
而现在,所谓的《Attention is all you need (V2)》虽然是个纯粹的戏称,但是也能看出来,如今的大模型发展到了个瓶颈,也急需一种新方法突破的阶段了。
所以,《Nested Learning: The Illusion of Deep Learning Architectures》应运而生。
有趣的是,2017年的来自于《Attention is all you need》来自于Google Research,这次,依然是Google Research。
遥相呼应了属于是。

在我花了一些时间读完这篇论文后。
我觉得我还是学到了非常多的东西,有一种我之前看DeepSeek-OCR那篇论文的美感。
我尽可能的用大白话,来聊聊这篇论文到底说了个啥,以及它为啥可能这么牛逼。
话不多说,直接开始。
要理解这篇论文的牛逼之处,我们得先理解现在的大模型有个非常致命的缺陷。
这个缺陷,就是:
失忆。
更准确地说,是:
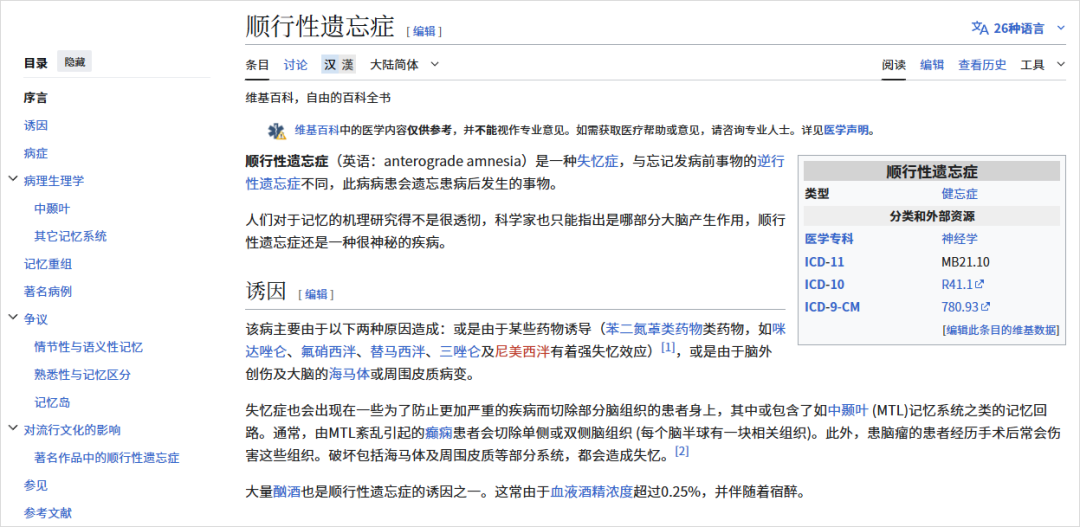
顺行性遗忘症。
我们常说,人脑这东西,最厉害的一点,从来不是计算的多又快,有多省功耗,而是能记多久,又能多聪明。
你肯定见过那种经典的神经科普。
比如告诉你,大脑有短期记忆、长期记忆,短期记忆大概能同时存 7±2 个东西,然后很容易忘掉,长期记忆存得久,但写入很慢,要反复出现、要睡觉巩固、要和别的东西勾连,你才能记很久很久很久。
然后呢,现在的神经科学也会提到一个观点,就是说:
记忆是分阶段巩固的,有在线的那一段,也有离线的那一段。
大概就是你白天学的东西,会先在海马体里写个草稿,晚上睡觉的时候,大脑会在各种脑波里反复replay,慢慢把重要的东西刻进皮层,变成真正的长期记忆。
所以啊,睡眠不好,会让你的记忆力越来越差,不是没有根据的,我现在就能明显的感觉到,记忆力越来越差了。。。
但是啊,如果你的这里出问题,就会出现我们在上文说的那个很典型的病。
顺行性遗忘症。
这类病人以前的记忆都在,但从某个时间点以后,新东西统统写不进长期记忆。
他们的世界只有“很久很久以前”和“刚刚这几分钟”,剩下的时间一片空白,每一天都像被困在刚刚发生的循环里。
不知道大家有没有看过诺兰的一个很经典的电影《记忆碎片》。

主角只能记住几分钟内发生的事,一旦超过这个时间,记忆就清零了,只能靠身上的纹身和纸条来提醒自己。
他知道自己是谁,知道自己过去的一切,但他无法形成新的、长久的记忆。
现在所有的大模型,GPT-5.1也好,Gemini 3 pro也好,再牛逼的模型,现在本质上都是《记忆碎片》的主角。
它们那个庞大的、包含了半个互联网知识的模型参数,就是主角过去的人生记忆,也是他的长期记忆。
而我们跟它聊天时的那个上下文窗口,就是他那几分钟的短期记忆。
你在一个对话里教它一个新知识,它能记住,还能举一反三。
但只要你关掉对话框,重新开一个,再问它,它就一脸无辜地看着你:“咱俩之前聊过这个吗?”
这里咱们不聊ChatGPT和Gemini里面那种记忆的能力,那个本质上是RAG,不能算从模型层面,真的记住了那些你说过的知识。
所以,我们其实可以看到,大模型的知识,被永远冻结在了预训练结束的那一刻。
从那以后,它就失去了形成新长期记忆的能力。
每一次对话都是一场绚烂的烟火,美则美矣,但消散后,什么都不会留下。
所以,这也意味着,现在你能用到的
AI,也永远无法真正地成长。
它无法从与你的互动中真正地了解你,也无法从解决了一个新问题后把经验固化下来。
所以,其实我们每次跟AI开启一个新的对话,都是在和一个全新的、只有出厂设置的AI打交道。
这里还是再强调一下,我说的一直都是模型层面,不是ChatGPT上面的那种记忆功能,那是工程层面,跟模型本身没啥关系。
讲到这里,我相信大家,都已经理解了,在现在的AI架构之下,这个致命的弊端。
就是,顺行性遗忘。
所以,这篇《Nested Learning》(嵌套学习,简称NL)的论文,就是冲着这个根本问题来的。
他们关注到了人脑里,一个特别有意思的现象,就是脑电波。

我们的大脑里,其实是有各种不同频率的脑电波,他们各自骑着不同的作用。
比如睡觉时的Delta波(0.5-4Hz),放松时的Alpha波(8-12Hz),专注时的Beta波(12-30Hz)等等。
这些不同程度的脑电波,其实都代表着不同的神经元在处理一些不同的任务。
比如有些神经元在飞速地处理眼前的信息,像电脑的GPU一样,这是高频活动。
有些则在慢悠悠地整理、归纳、存储信息,把短期记忆变成长期记忆,这是低频活动。
所以,我们的大脑,其实一直是一个非常复杂的多频率多层次协同工作的系统。
我用开车这事来举个例子,比如你正在学开车。
你的最高频系统,是你的手脚肌肉记忆。
方向盘往左打多少,油门踩多深,这个反应得非常快,几乎是毫秒级的。这是最表层的、最快的学习。
你的中频系统,是你的战术决策。
比如“前面红灯了,我该踩刹车了”、“旁边有车要并线,我得让一下”。这个决策过程比肌肉反应要慢,可能是秒级的,你需要一点点时间来处理路况信息,这是中频。
你的低频系统,是你的战略规划。
比如“我今天要去A地,导航显示这条路堵车,我应该换一条路走”。
这个学习和决策过程就更慢了,你可能在出发前就想好了,路上还会根据情况调整,这是低频。
你的最低频系统,是你的核心驾驶理念和能力。
通过几个月的练习,你从一个新手变成了老司机。
这个学会开车的过程,彻底改变了你大脑中关于驾驶的神经连接,而这个变化是非常缓慢的,是以天、周、月为单位的,用AI的话说,就是,你的驾驶模型被重塑了。
从这个学会开车这么一个小事上来说,你应该能发现,
我们人类的学习,天然就是嵌套式的,也是分层次分频率的。
我们不会用思考人生哲学的脑回路去控制踩刹车的肌肉,也不会用肌肉记忆去规划一次长途旅行。
现在的以Transformer为首的大模型架构,问题就出在这。它虽然有很多层,但本质上,它是个单频系统。
在训练的时候,所有参数的更新节奏基本是一致的,训练结束后,整个系统就被锁死,所有频率都归零了。
他再也没有办法学习了。
而再《Nested Learning》这套框架下,论文又提出了一个新的模型模块 ,HOPE,名字非常好听,叫希望。
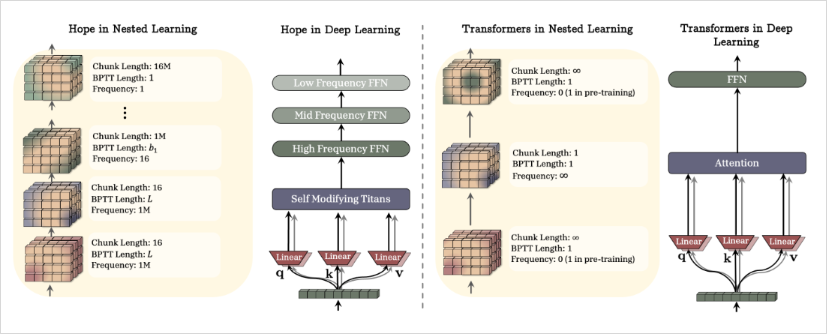
HOPE里面,混了两个东西,一部分是会自我修改权重的序列模型,一部分是多时间尺度的连续记忆带(Continuum Memory System)。
从而,让HOPE,拥有了带自我更新机制的记忆单元。
它要把一个AI模型,明确地拆分成不同更新频率的层级。
再这套框架下,AI在跟你对话的时候:
它的高频层,在飞速处理你说的每个词,理解你的意图,生成回复,这部分记忆是临时的,对话结束可能就忘了。
它的中频层则在以一个稍慢的速度,分析你这整个对话的主题、你的情绪、你的知识盲区,试图形成一个关于这次互动的概要记忆。
它的低频层则更慢,它在整合过去一段时间里,跟你的所有互动。它可能会发现:“哦,这个用户最近总是在问关于古典音乐的问题,而且他似乎对巴赫特别感兴趣。我应该把‘该用户是古典音乐爱好者’这个标签存入关于他的长期档案里。”
这个过程,就非常非常像人脑的记忆巩固机制了。
我们白天经历了很多事,这些都是碎片化的短期记忆,储存在我们大脑的海马体里。
到了晚上睡觉的时候,大脑会像放电影一样回放这些记忆片段(再论文里叫offline consolidation),把重要的信息筛选出来,然后写入到大脑皮层,成为稳定的长期记忆。
嵌套学习,就是给了AI一个睡觉和反思的能力。
可以让AI,成为一个可以日积月累、不断沉淀的学习者。
讲到这里,你可能立刻会有一个疑问。
就是这个ChatGPT的记忆。
你可能会说:“等等,现在的大模型不是已经有记忆了吗?我告诉它我是一个素食主义者,它就能记住,下次会给我推荐素食餐厅。这不就是你说的那个低频层在起作用吗?”
但这个地方,我想说,这其实是个随身带个笔记本和记在了脑子里的根本区别。
你看到的ChatGPT的记忆功能,本质上就是一个笔记本,当你告诉它一个信息,比如“我是个大呆逼”,它并没有真正把这个信息学进它那个巨大的神经网络大脑里去。
它的核心模型,那上万亿个参数,一个子儿都没动。
它做的是,把“用户是个大呆逼”这个事实,提炼出来,存进一个外挂的数据库里,这个就是非常常见的一个技术,叫检索增强生成,也就是RAG。
下次你跟它聊天,它会先在这个数据库里迅速翻一下,找到跟你相关的信息,然后把“已知该用户是个大呆逼”这句话,悄悄地、自动地塞进你们对话的背景信息里,再来回答你的问题。
所以,它的大脑本身还是那个失忆的大脑。
它只是拥有了一个越来越厚的、关于你的外部参考资料库。
它不是真的记得,而是在每次对话前,都先看一遍笔记再来回答,仅此而已。
这很强大,非常实用,但它有极限。这个极限就是,它无法将这些零散的知识点内化为真正的理解或直觉。
而《Nested Learning》提出的设想,是真正地去重塑大脑。
当它的低频层运行时,它不是往外挂数据库里写一行字。
它是用你和它的互动数据,去微调和更新它自己神经网络内部的参数。
这其实就像我们自己学习新技能,通过反复练习,大脑里负责这项技能的神经突触被真正地加强、重塑了。
再举个例子,一个钢琴家。
给他一本新乐谱,他可以看着谱子(外部记忆)弹出来,弹得可能很准,但也许没啥感情,你把乐谱拿走,他就弹不出来了,这就是现在ChatGPT的记忆。
但,如果这位钢琴家花了一个月的时间练习这首曲子,他早就已经扔掉乐谱,曲子已经融入了他的肌肉记忆和情感理解,他的大脑和手指的神经也完全紧密连接。
他不仅能弹,还能即兴变奏,还能跟你探讨这首曲子背后的情感。这就是嵌套学习所追求的境界。
所以,你看,这完全是两个层面的事。
现有记忆,是一种行为上的模拟。它通过外部工具,让AI看起来像有记忆,但其实AI的世界观和底层逻辑是纹丝不动的。
而这个嵌套学习的方法,是一种结构上的成长。它能让AI的神经网络本身发生改变,把新的信息和经验,从零散的数据点内化成模型自身能力的一部分,从而,让知识,真正变成了智慧。
这就是为什么这篇论文,为啥让我如此令人兴奋的原因。
这才是未来,真正的AI。
一个真正懂你的个人助理,你不用每次都跟它重复你的个人偏好和背景信息,它记得你上次跟它聊过你的宠物狗,记得你对猫毛过敏,记得你正在筹备下个月的旅行。
它跟你的互动越多,就越懂你。
这才是真正的。
Personal AI。
而在真正的评测里,论文作者拉来了Transformer++、RetNet、DeltaNet、Titans那些模型,在同样的参数量和训练数据下,HOPE在一串常见评测上,平均成绩都是第一档。
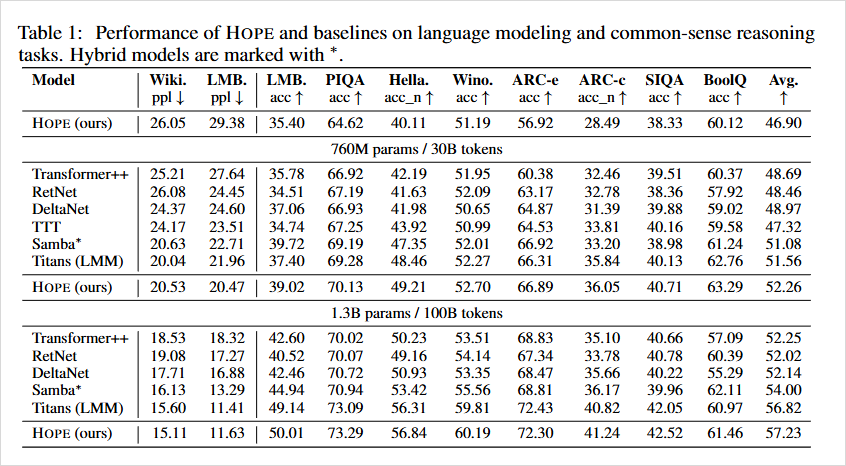
这条路,是有可能成功的。
万物皆是嵌套。
一个细胞的生命周期,嵌套在一个器官的运转中。
一个器官的运转,嵌套在一个人的生命里。
一个人的生命,嵌套在一部家族史里。
一部家族史,又嵌套在一个文明的兴衰中。
每一层都有自己的节拍和韵律,它们彼此影响,共同构成了这个复杂而美妙的世界。
也许,我们大脑几百万年进化出来的学习机制,可能真的,非常地道。
而AI要做的,也许不是另起炉灶,而是更谦卑地去模仿这种嵌套的、多层次的、充满韵律感的智慧。
也许,当AI真的学会了遗忘,学会丢弃不重要的信息,学会了沉淀,学会了巩固重要的记忆,学会了在喧嚣中保持一份缓慢的思考时。
它才真正开始拥有智能的幻觉。
甚至。
灵魂的雏形。
这条路还很长,但想想就让人激动,不是吗?
文章来自于“数字生命卡兹克”,作者 “卡兹克”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
