MIT系初创打破Transformer霸权!液体基础模型刷新SOTA,非GPT架构首次显著超越Transformer
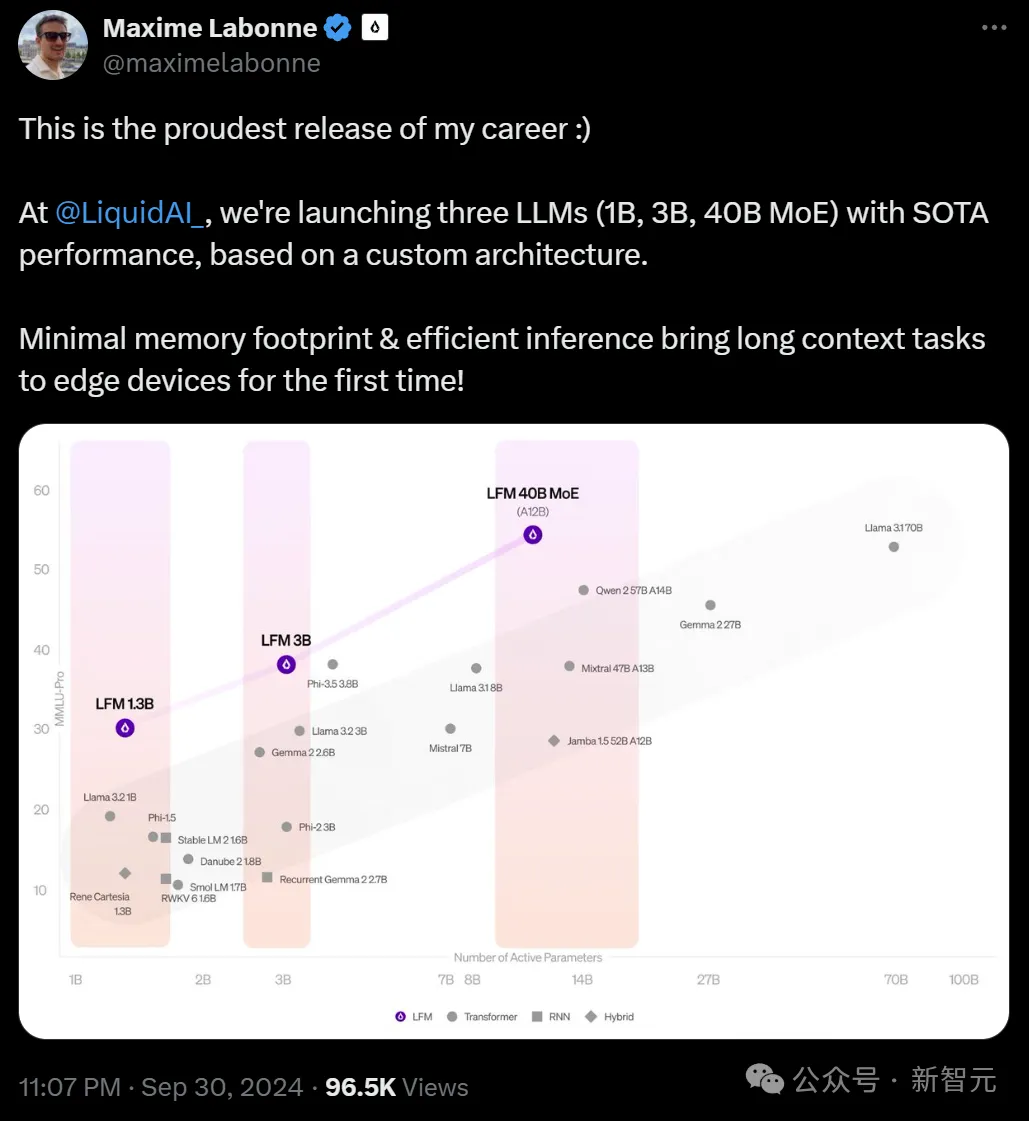
MIT系初创打破Transformer霸权!液体基础模型刷新SOTA,非GPT架构首次显著超越Transformer就在刚刚,MIT系初创公司Liquid AI团队官宣:推出首批多模态非Transformer模型——液体基础模型LFM。
来自主题: AI资讯
7209 点击 2024-10-01 14:52
 搜索
搜索
就在刚刚,MIT系初创公司Liquid AI团队官宣:推出首批多模态非Transformer模型——液体基础模型LFM。
一个受线虫启发的全新架构,三大「杯型」均能实现 SOTA 性能,资源高度受限环境也能部署。移动机器人可能更需要一个虫子的大脑。

通往AGI的路径只有一条吗?实则不然。这家国产AI黑马认为,「群体智能」或许是一种最佳的尝试。他们正打破惯性思维,打造出最强AI大脑,要让世界每一台设备都有自己的智能。

取代现有计算架构。 人工智能(AI)硬件有望彻底被颠覆,在计算速度和能效方面实现前所未有的改进。

扩展多模态大语言模型(MLLMs)的长上下文能力对于视频理解、高分辨率图像理解以及多模态智能体至关重要。这涉及一系列系统性的优化,包括模型架构、数据构建和训练策略,尤其要解决诸如随着图像增多性能下降以及高计算成本等挑战。

随OpenAI爆火的CoT,已经引发了大佬间的激战!谷歌DeepMind首席科学家Denny Zhou拿出一篇ICLR 2024论文称:CoT可以让Transformer推理无极限。但随即他就遭到了田渊栋和LeCun等的质疑。最终,CoT会是通往AGI的正确路径吗?

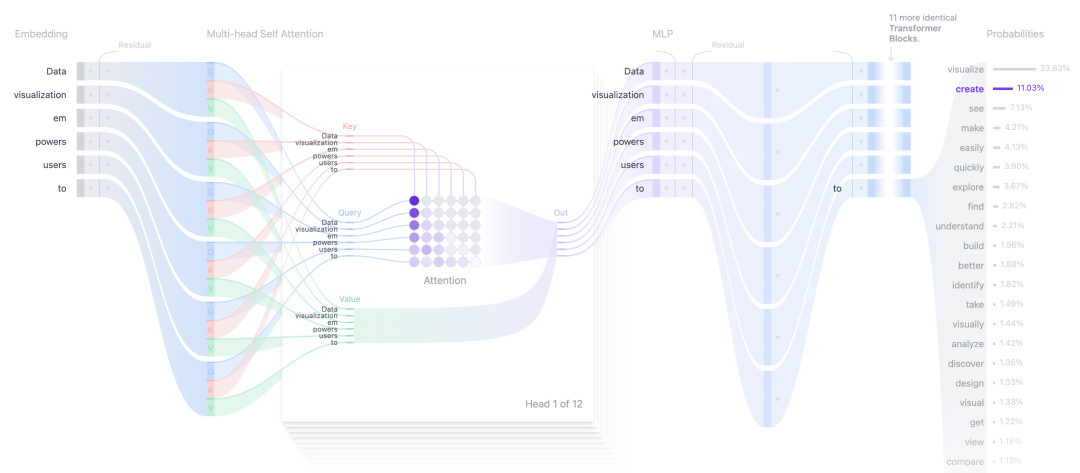
Transformer 是现代深度学习的基石。传统上,Transformer 依赖多层感知器 (MLP) 层来混合通道之间的信息。

注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。

坐拥世界最大的搜索业务,谷歌一直独步于硅谷。搜索所带来的丰厚广告收入,让两位创始人谢尔盖・布林 (Sergey Brin) 和拉里・(Larry Page)可以退居二线,安心享受生活。
之前已经分享过一次AI领域GitHub上那些神级项目,大家可以回顾下这篇文章《震撼来袭,盘点GitHub上那些免费的神级AI项目,建议立刻收藏!》。但是AI发展那么迅速,所以今天继续来给大家盘点一下近期在Github上,AI领域又有哪些神级的项目,最后一个特别推荐。