ICCV 2025 | 基于时序增强关系敏感知识迁移的弱监督动态场景图生成
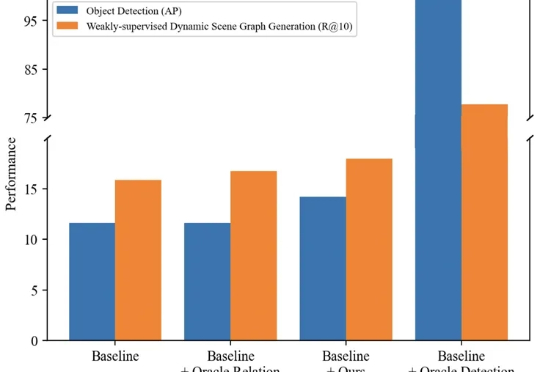
ICCV 2025 | 基于时序增强关系敏感知识迁移的弱监督动态场景图生成本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
来自主题: AI技术研报
8434 点击 2025-09-05 11:18
 搜索
搜索
本文主要介绍来自该团队的最新论文:TRKT,该任务针对弱监督动态场景图任务展开研究,发现目前的性能瓶颈在场景中目标检测的质量,因为外部预训练的目标检测器在需要考虑关系信息和时序上下文的场景图视频数据上检测结果欠佳。
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。

刚刚,马斯克xAI加入Coding战局:推出智能编程模型Grok Code Fast 1。Fast写进名字里,新模型主打的就是快速、经济,且支持256K上下文,可在GitHub Copilot、Cursor、Cline、Kilo Code、Roo Code、opencode和Windsurf上使用,还限时7天免费!
Grok-2正式开源,登上Hugging Face,9050亿参数+128k上下文有多猛?近万亿参数「巨兽」性能首曝。马斯克再现「超人」速度,AI帝国正在崛起。

AI生成的人物和场景转头就变样,缺乏一致性? nonono,这回不一样了,康康下面的demo! 游戏地图:《塞尔达传说》中的绿色田野
集成全球顶尖的编程模型、最强的上下文工程能力,可一次检索10万个代码文件。阿里全新AI代码编辑器Qoder表示——它可以理解整个代码库,并交付真正适合的代码。
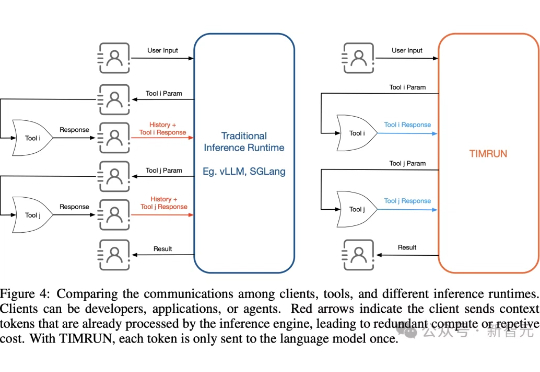
大模型再强,也躲不过上下文限制的「蕉绿」!MIT等团队推出的一套组合拳——TIM和TIMRUN,轻松突破token天花板,让8b小模型也能实现大杀四方。
别再迷信提示词魔法了,AI更像是需要“入职”的新同事。给足上下文,它就是你的专属思考伙伴。如果你正在寻求大家都在谈论的、AI许诺可带来的生产力提升,那就看看这篇指南吧。
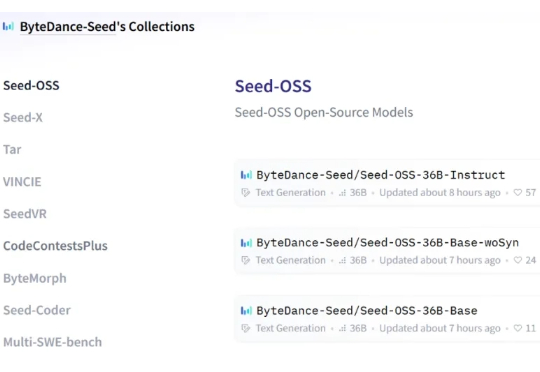
开源赛道也是热闹了起来。 就在深夜,字节跳动 Seed 团队正式发布并开源了 Seed-OSS 系列模型,包含三个版本: Seed-OSS-36B-Base(含合成数据) Seed-OSS-36B-Base(不含合成数据) Seed-OSS-36B-Instruct(指令微调版)

要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。镜头稍作移动再转回,眼前景物就可能「换了个世界」。