ICML 2026 |让大模型边想边说:这篇文章把「何时开口」变成可学习策略
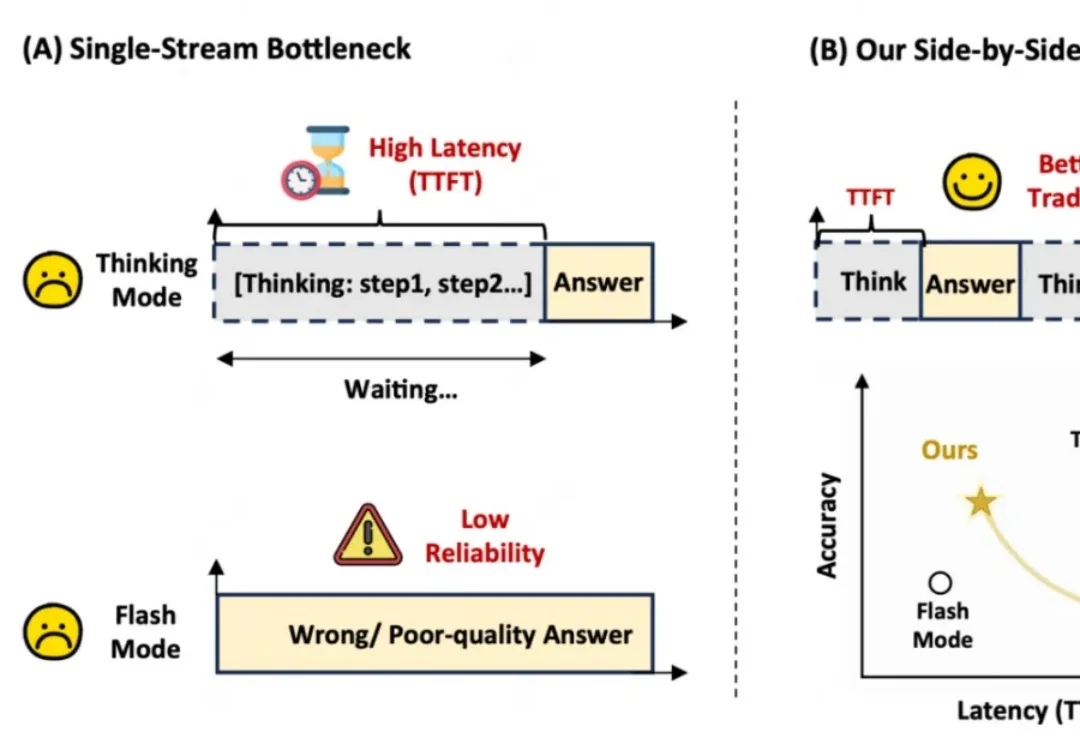
ICML 2026 |让大模型边想边说:这篇文章把「何时开口」变成可学习策略用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。
来自主题: AI技术研报
10254 点击 2026-05-18 15:27
 搜索
搜索
用过推理型大模型的人,大概率都熟悉这种体验:模型似乎在认真思考,但屏幕上长时间没有真正有用的内容;如果让它一开始就输出,又很容易出现仓促判断,后面的推理还要被早期错误牵着走。
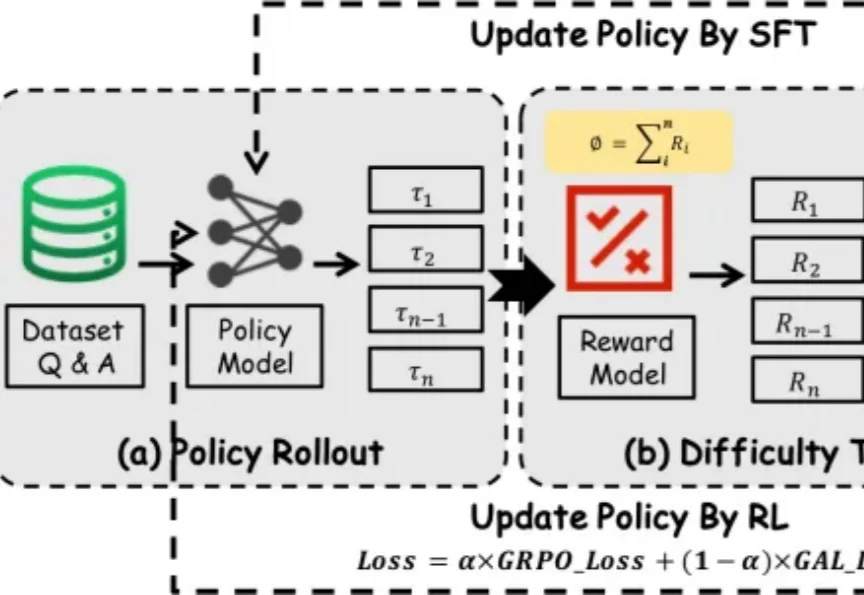
过去一段时间里,在围绕大模型推理能力增强的研究中,SFT 和 RL 是两类核心后训练范式 —— 前者稳定收敛快,能高效吸收高质量推理数据;后者更具探索性,有望推动模型实现复杂推理和分布外泛化。
宠物大模型健康公司重庆绮算法科技有限公司(以下简称“绮算法”)、智谱“Z计划”生态企业,近日完成数千万元融资,投资方为启赋资本与聚恒创投。本轮资金将主要用于产品迭代、模型能力深化及市场拓展。
就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。

5月15日,米哈游在北京举办了一场AI基础大模型相关的技术分享会与顶尖校招生招募活动,米哈游创始人刘伟在此次招聘会上分享了部分他对AI业务的看法和愿景。

为了解决这一问题,来自中山大学和美团的研究团队提出了 X2SAM,一个统一的图像与视频分割多模态大模型框架。它希望让模型不仅能「看懂」图像和视频,还能进一步「指出」目标在每个像素上的准确位置。

微软用一套多 Agent 系统在 AI 漏洞发现的顶级基准测试上拿下第一,超过 Anthropic 最强模型 Mythos 五个百分点。诡异的是,微软自己并没有一个能打的前沿模型。它用别人的模型组了个系统,打败了造出这些模型的公司。这对AI竞争格局的启示,比这个工具挖出了大量 Windows 漏洞本身更重要。
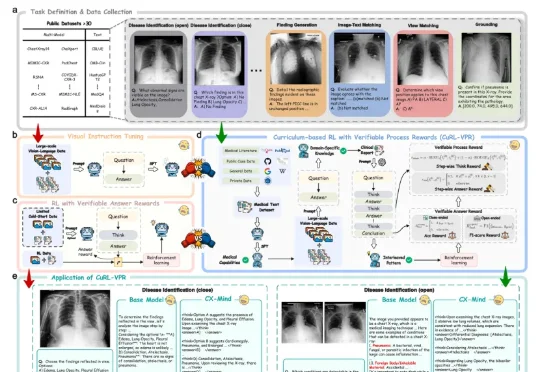
上海交通大学、上海创智学院与瑞金医院联合发布的CX-Mind,是目前首个将胸片诊断推进为「可验证推理链」的多模态大模型——从看到异常,到解释为什么、排除了什么、结论怎么来的,每一步都有影像证据支撑。

一篇让你看懂的AGenUI开源解读
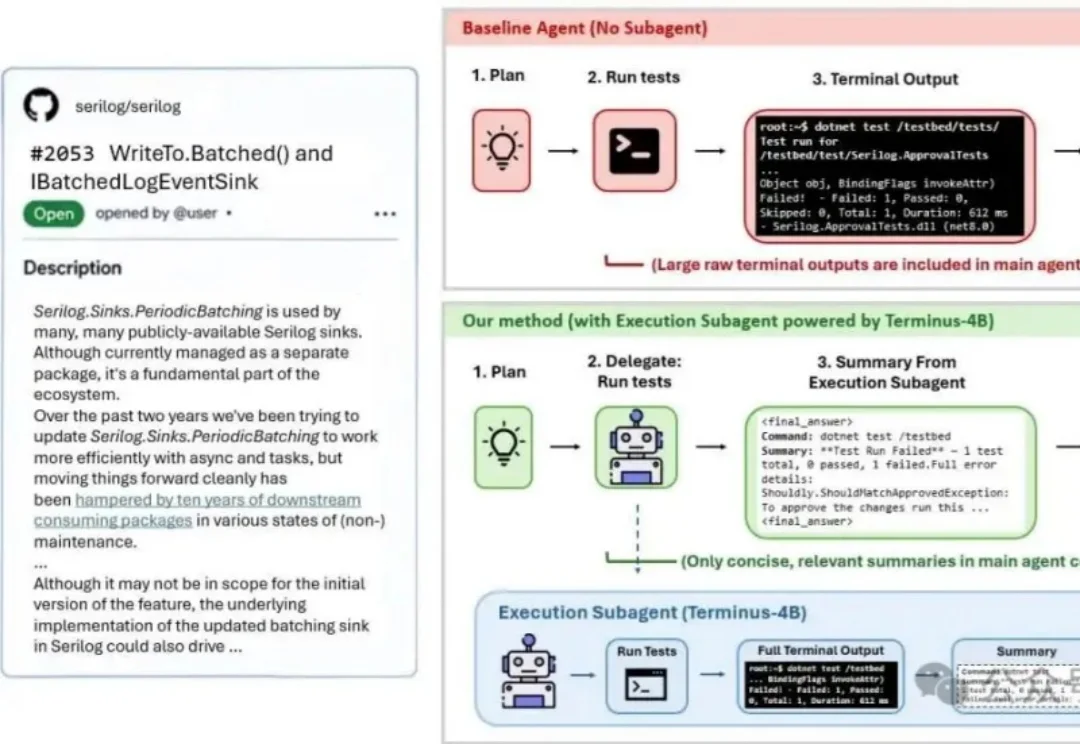
您有没有想过:在代码Agent里,执行终端命令、跑测试、读报错、总结日志这种任务,用Claude Opus、Claude Sonnet、GPT-5.3-Codex这类昂贵Token的大模型来执行,是不是有点浪费?一定要这么做吗?