
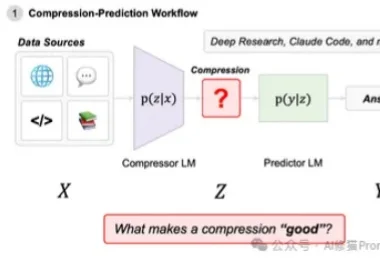
信息论证明,小模型跑在本地才是Agent的终极解法|斯坦福重磅
信息论证明,小模型跑在本地才是Agent的终极解法|斯坦福重磅在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
来自主题: AI技术研报
9093 点击 2026-01-04 10:20
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。
在这精彩绝伦的一年的结尾,我们的老朋友:斯坦福大学计算机科学客座教授,前百度 AI 负责人,前谷歌大脑负责人吴恩达老师,发表了今年的保留节目:一封信,和一篇 2025 的人工智能领域年度总结。

说个魔幻的现实,前两天,斯坦福发布了《AI 活力指数》。这榜单看得人直迷糊,印度的 AI 竞争力居然干翻了英日韩,仅次于美中,一屁股坐到了全球第三。。

随着基础模型的日益成熟,AI领域的研发重心正从“训练更强的模型”转移到“构建更强的系统”。在这个新阶段,适配(Adaptation) 成为了连接通用智能与垂直应用的关键纽带。

有关大语言模型的理论基础,可能要出现一些改变了。

在工业界动辄十万卡的暴力美学面前,学术界正沦为算力的「贫民窟」。当高校人均不足0.1张卡时,AI科研的主导权之争或许已经没有了悬念。

2025就要过去了。UC Berkeley、Stanford和IBM联手做了一件大事。他们调研了306份在一线“造 Agent”的从业者问卷,并深度访谈了20个已经成功落地并产生价值的一线企业案例(涵盖金融、科技、医疗等领域)。试图回答一个最朴素的工程问题:一个能用的、赚钱的Agent,到底是用什么架构搭出来的?

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。

斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。

当大多数高校还在严防死守学生用AI「偷懒」时,斯坦福本学期最火爆的一门课却反其道而行之:不准手写代码,必须用AI!