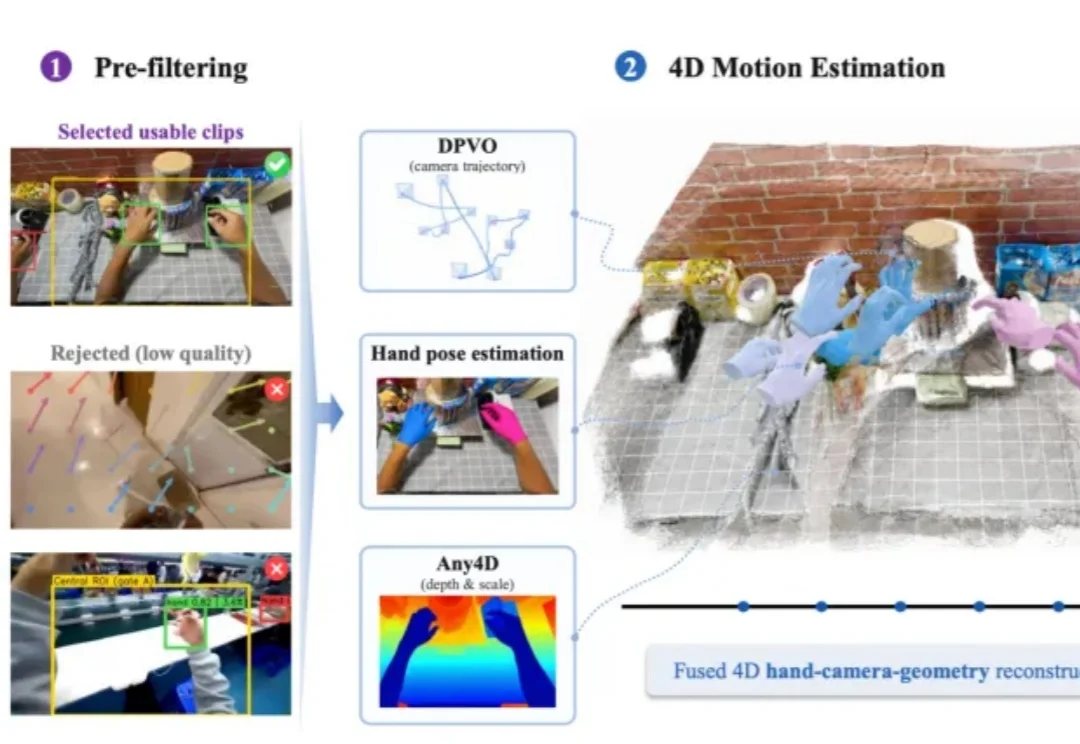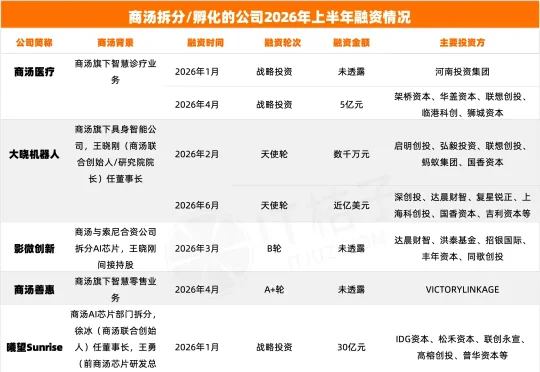
AI老大哥夯爆了,“商汤系”离职创业者这半年狂揽400亿元!
AI老大哥夯爆了,“商汤系”离职创业者这半年狂揽400亿元!根据IT桔子数据,截至2026年7月17日, 32家“商汤系”公司在上半年共完成28笔融资,累计融资额超过470亿元人民币,在中国AI融资市场取得了耀眼的成绩。其中,既有商汤科技自身通过“1+X”战略拆分出的子公司——曦望Sunrise、大晓机器人、商汤医疗等;也有大批从商汤离职创业的前高管所创立的公司
来自主题: AI技术研报
7917 点击 2026-07-24 15:57