
世界模型应如何评估?南京大学团队发布「世界模型」评估立场论文
世界模型应如何评估?南京大学团队发布「世界模型」评估立场论文近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
来自主题: AI技术研报
8441 点击 2026-07-13 14:44
 搜索
搜索
近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
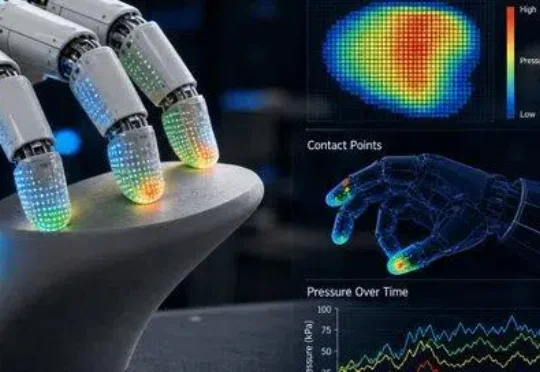
瞄准这类 “看起来做对了,物理上却没完成” 的失败。破晓智能(PHANES AI)创始人、哈工大(深圳)长聘教授杨朔及其团队发布了最新论文 TouchWorld: A Predictive and Reactive Tactile Foundation Model for Dexterous Manipulation。
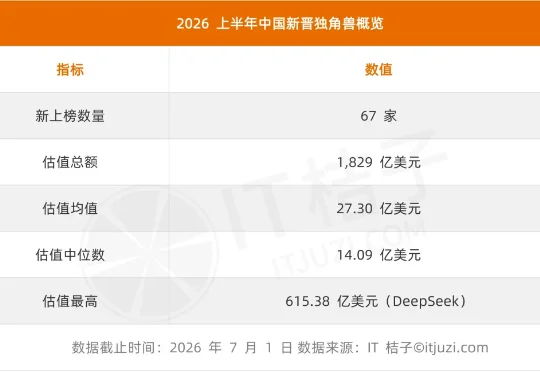
截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家:
蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—
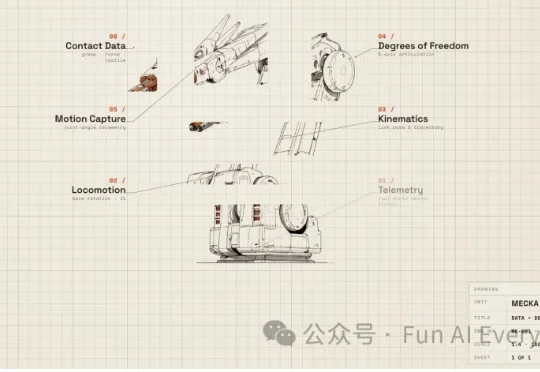
今天分享一家很新的公司,Mecka AI,Mecka AI 是一家给机器人公司提供训练数据的公司。更具体一点,Mecka AI 做的是“人类动作数据”。也就是说,Mecka 做的事情很像“机器人时代的 Scale AI”。

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。

独家获悉,由上海人工智能研究院孵化的灵境智源已完成超亿元的天使轮和天使 + 轮两轮融资,由经纬创投领投,上海闵行国资战略跟投。在这之前,企业尚属“水下”状态,两轮均实现了超额认购。据透露,在未对外释放公开融资的消息的情况下,

6 月 30 日,深度机智团队发布论文 Human-as-Humanoid。他们在自研拟人机器人 PrimeU 上,实现了完全没有目标任务真机示范数据的情况下,仅凭从人类视频中转换而来的动作监督,零样本完成了倒水、放环、装袋、叠杯等复杂真实操作任务。

当机器人后空翻刷屏时,代表小脑已经在快速进展。但你是否意识到,让机器人真正干活卡脖子的从来不是小脑,而是大脑?蚂蚁灵波刚刚开源的LingBot-VLA2.0,用同一套模型「驯服」了20种的机器人构型。行业终于有人开始认真算重复适配成本这笔账了。