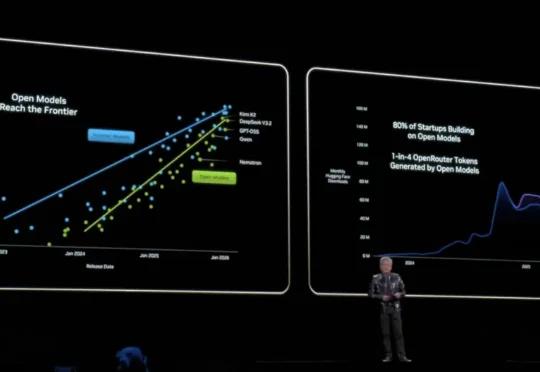
英伟达叫板DeepSeek?怒投260亿美元,要打造最强开源模型
英伟达叫板DeepSeek?怒投260亿美元,要打造最强开源模型据 2025 年的一份财务文件显示,英伟达将在未来五年内投入 260 亿美元用于构建开源人工智能模型。据《WIRED》杂志报道,英伟达高管证实了这一此前从未被报道过的消息。
来自主题: AI资讯
9539 点击 2026-03-14 08:40
 搜索
搜索
据 2025 年的一份财务文件显示,英伟达将在未来五年内投入 260 亿美元用于构建开源人工智能模型。据《WIRED》杂志报道,英伟达高管证实了这一此前从未被报道过的消息。
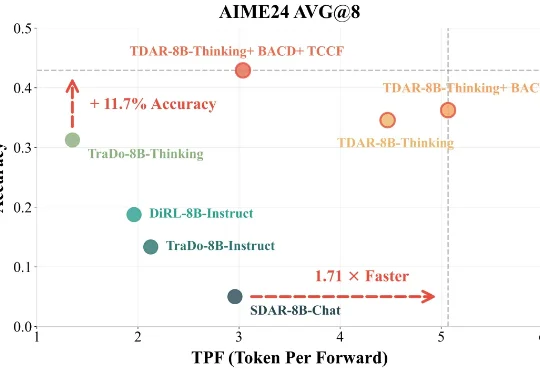
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
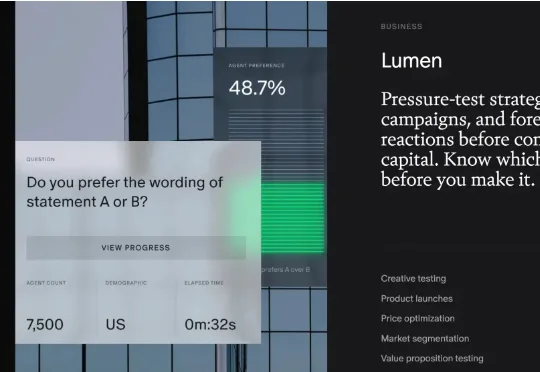
Aaru是一家2024年成立的美国AI智能体初创公司,其核心业务是通过整合人口统计与心理特征数据构建模型,生成精准用户画像,并利用数千个AI智能体模拟人类行为反应,目前已被应用于产品开发、定价策略、新客拓展以及政治民调等多个领域。

牛津大学团队推出全球首个心脏传感基础模型CSFM,能统一分析智能手环、心电图等多源数据,无论信号来自何处、是否完整,都能精准诊断房颤、预测死亡风险、重构血压波形,甚至用单一脉搏波生成完整心电图。打破了设备壁垒,让偏远地区也能享用顶级心脏监护,推动全球医疗平权。

在大模型狂飙突进的叙事里,算力是入场券,而那些曾亲手拆解过全球顶级模型“黑盒”、并见证其从阵痛到翻盘的核心人才,才是真正的胜负手。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。
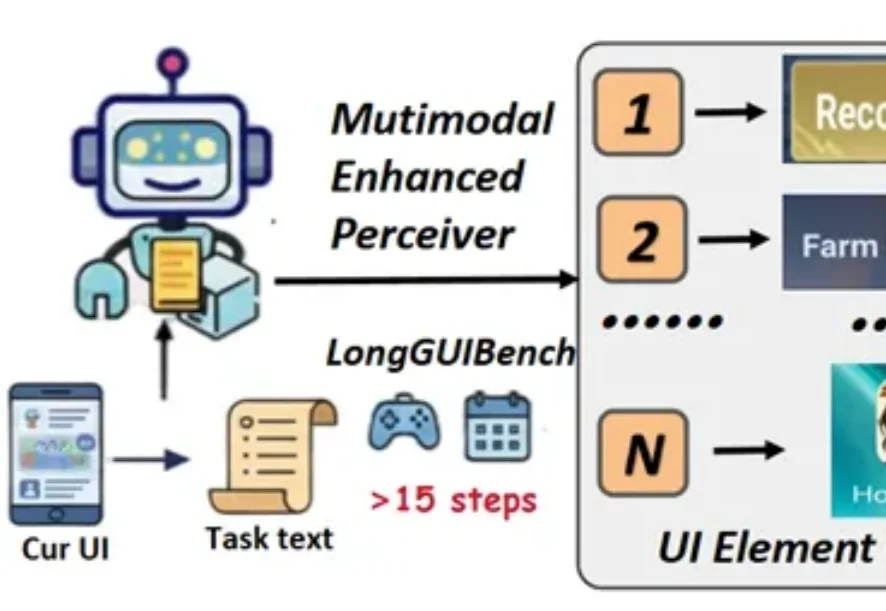
在移动端和桌面端的日常使用中,许多操作并非点一下按钮就能完成。预订一场会议、在游戏商城中购买并装备一件道具、又或者在多个应用之间完成一组连贯的工作流 —— 这些任务通常需要十几步甚至几十步的连续交互。

我们独家获悉,外界千呼万唤的DeepSeek-V4将于4月正式上线。作为梁文锋打磨已久的多模态大模型,DeepSeek-V4除了在Coding能力上跃升之外,还将在LTM(long term memory长期记忆)上取得突破。

OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,吞吐量猛涨5倍,「龙虾」这是要上天了。

今天是 OpenAI Responses API 上线一周年。OpenAI 又出来抖猛料了!