史上最强编程模型Claude 5泄露,最慌的是黄仁勋?
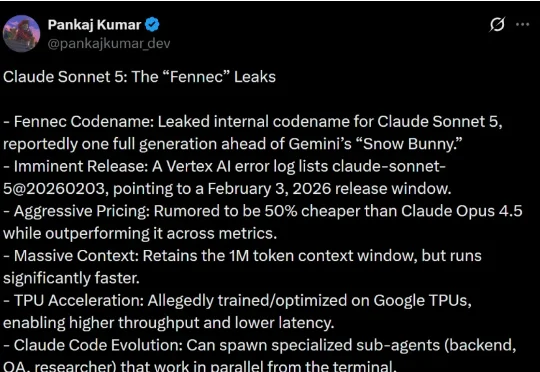
史上最强编程模型Claude 5泄露,最慌的是黄仁勋?2月2日,X上一位的知名AI博主Pankaj Kumar (@pankajkumar_dev),爆料了Anthropic的下一代旗舰模型Claude Sonnet 5。这个模型代号为“Fennec”,可能在明天或者后天就要正式发布了。
来自主题: AI资讯
9873 点击 2026-02-02 23:09
 搜索
搜索
2月2日,X上一位的知名AI博主Pankaj Kumar (@pankajkumar_dev),爆料了Anthropic的下一代旗舰模型Claude Sonnet 5。这个模型代号为“Fennec”,可能在明天或者后天就要正式发布了。
就在刚刚,据《南华早报》援引知情人士最新消息,智谱 AI 计划在未来两周内,也就是春节前发布其新旗舰模型 GLM-5。与此同时,MiniMax 也预计将于春节前发布 M2.2 模型,这是在原有 M2.1 基础上进行的小幅更新,重点提升编程能力。

今日,阶跃星辰Step 3.5 Flash开源并上线,该模型在Agent场景和数学任务上能力逼近闭源模型,能够胜任复杂、长链条任务,是阶跃星辰迄今最强的开源基座模型。就在上周,阶跃星辰宣布由旷视科技联合创始人、千里科技董事长印奇正式出任董事长,并完成华勤、腾讯等参投的超50亿元B+轮融资。这也是印奇履新后,阶跃星辰在开源模型领域的首个大动作。
忍不了了,这个槽我真的不吐不快!
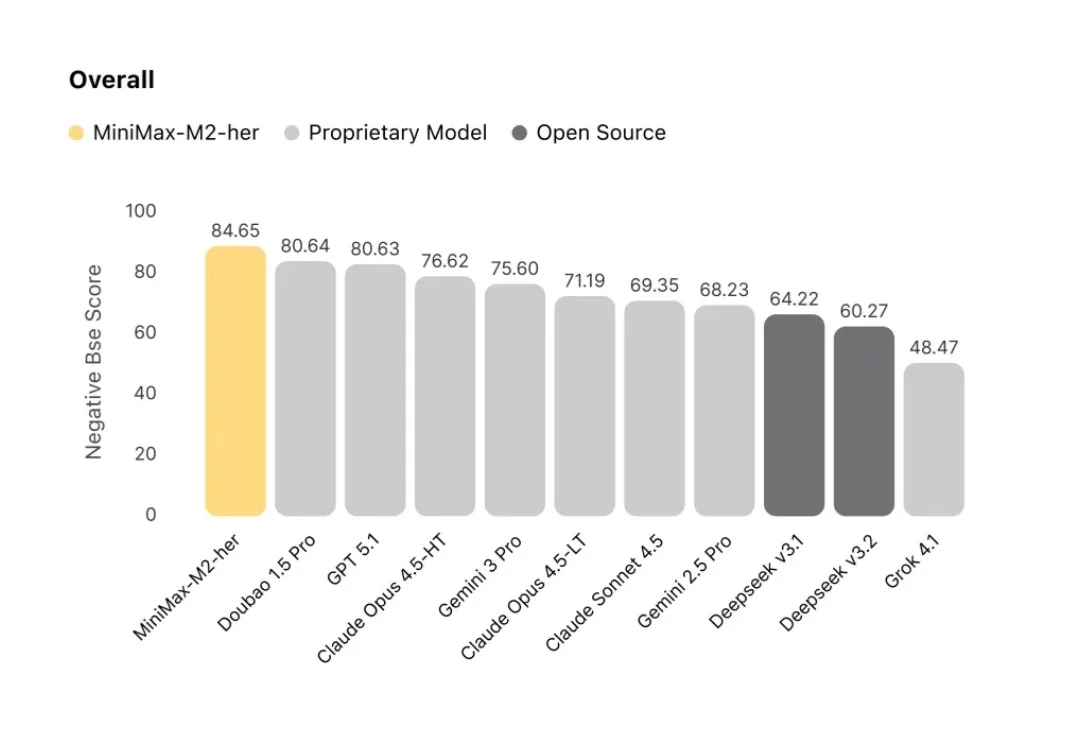
今天,我们分享 MiniMax-M2-her 背后的技术思考。M2-her 也是服务星野/Talkie的底层模型。

语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。

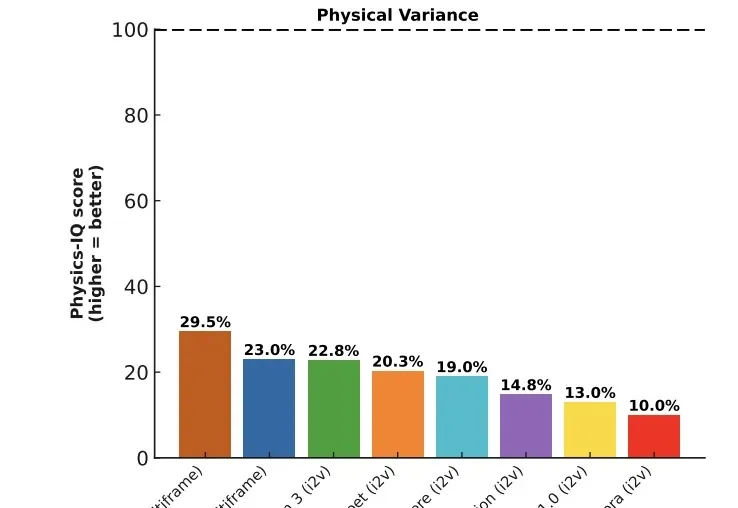
去年下半年,模型界最大的惊喜莫过于Sora 2和Veo 3,他们已经把视频生成推到了新高度:光影完美,纹理细腻,甚至有着很高的时空一致性。
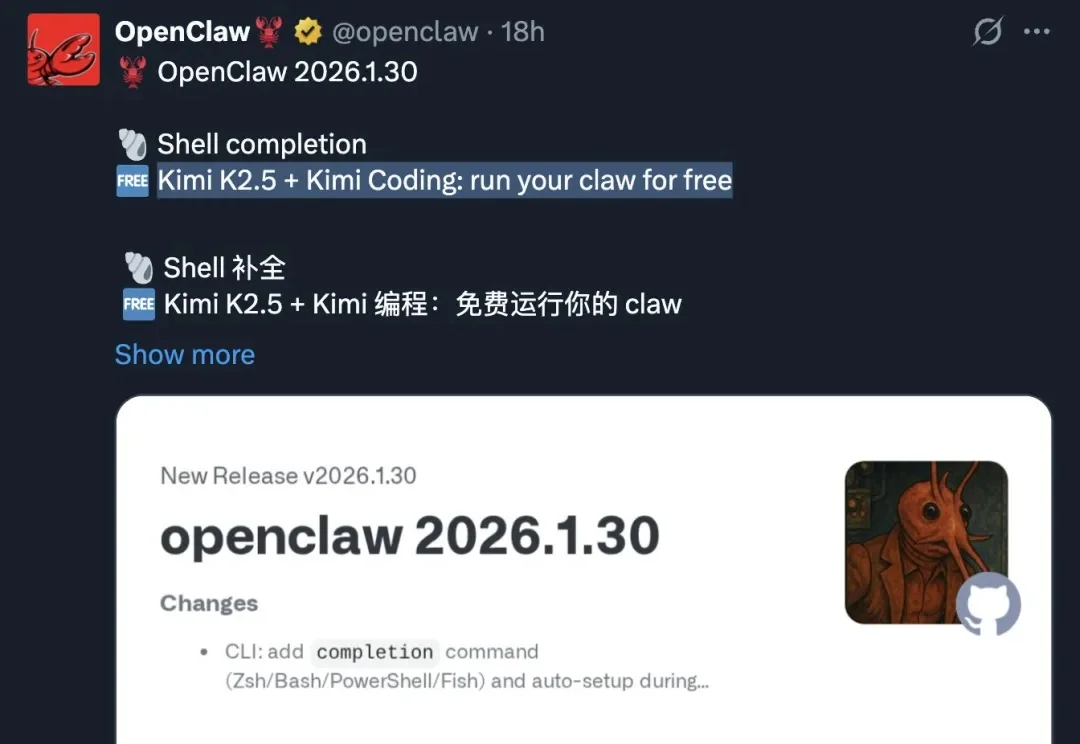
“免费补贴”在硅谷从来不只是价格标签,而往往是战略指南针。
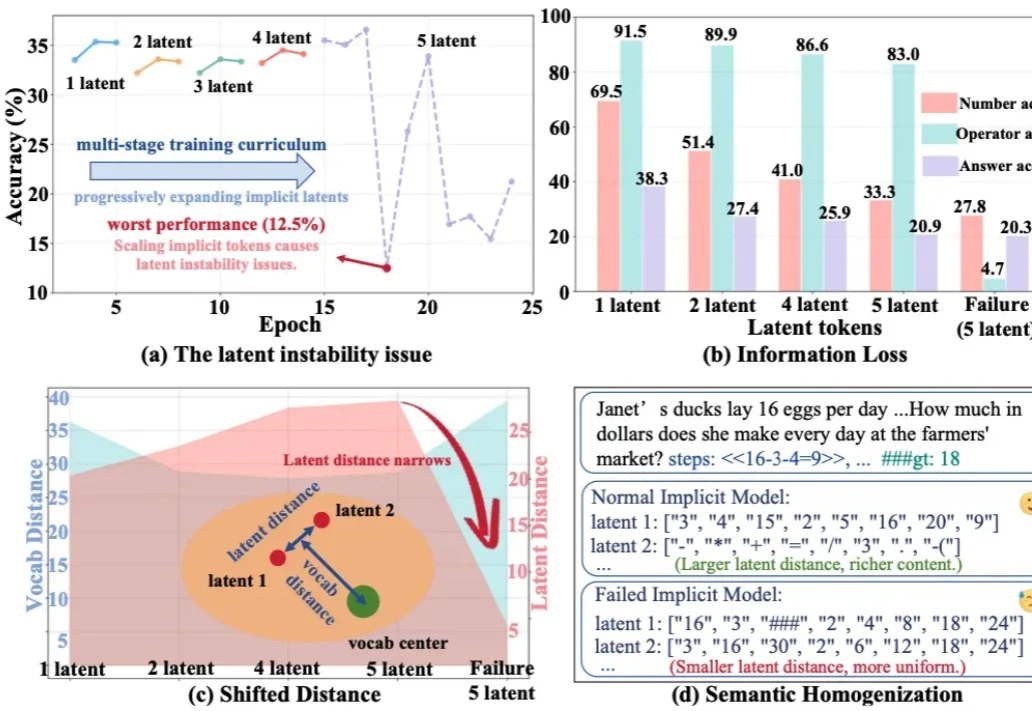
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。