
刚刚,月之暗面被曝又融237亿!
刚刚,月之暗面被曝又融237亿!刚刚,据彭博社援引知情人士消息报道,北京大模型独角兽月之暗面在最新完成的融资轮次中筹集了超出预期的35亿美元(约合人民币236.77亿元),投后估值达350亿美元(约合人民币2367.71亿元)。
来自主题: AI资讯
8995 点击 2026-07-29 21:05
 搜索
搜索
刚刚,据彭博社援引知情人士消息报道,北京大模型独角兽月之暗面在最新完成的融资轮次中筹集了超出预期的35亿美元(约合人民币236.77亿元),投后估值达350亿美元(约合人民币2367.71亿元)。
最近 Claude 又开始大面积封号,我的主号终究也没能幸免。
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。
李飞飞老师的World Labs,补了块关键拼图。
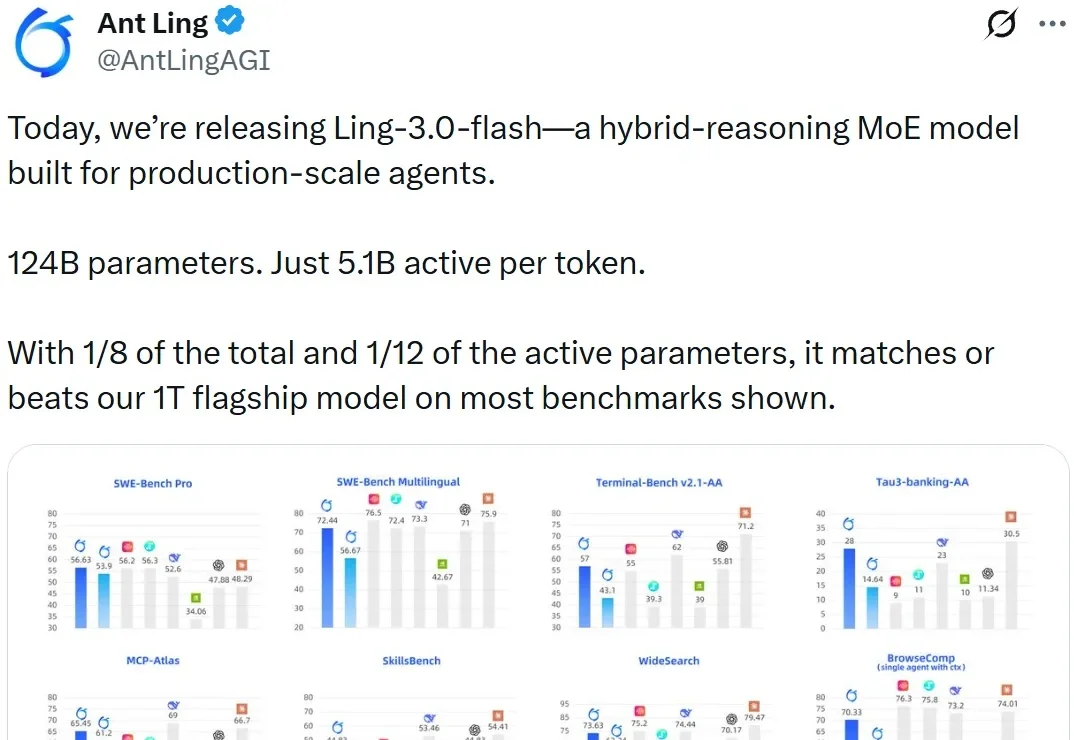
每逢重要的新模型发布,我们编辑部通常比新闻本身更早进入工作状态:提前打开官网、直播和社交媒体,等结果陆续出来,大家一边热火朝天地开始写文章,一边梳理参数、榜单和演示案例,判断这一次技术究竟向前走了多远。

是时候讨论一下 AI 的 “第三极”—— 社会智能了。

大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。
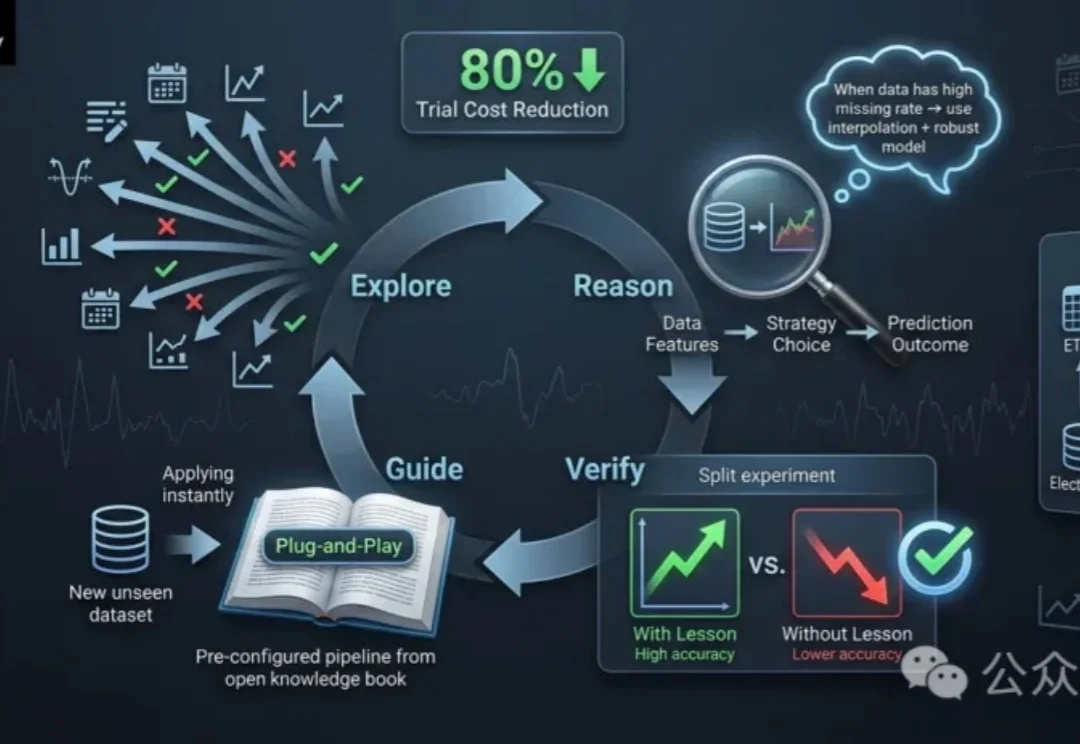
在真实工业环境中,数据并不是静止不变的。
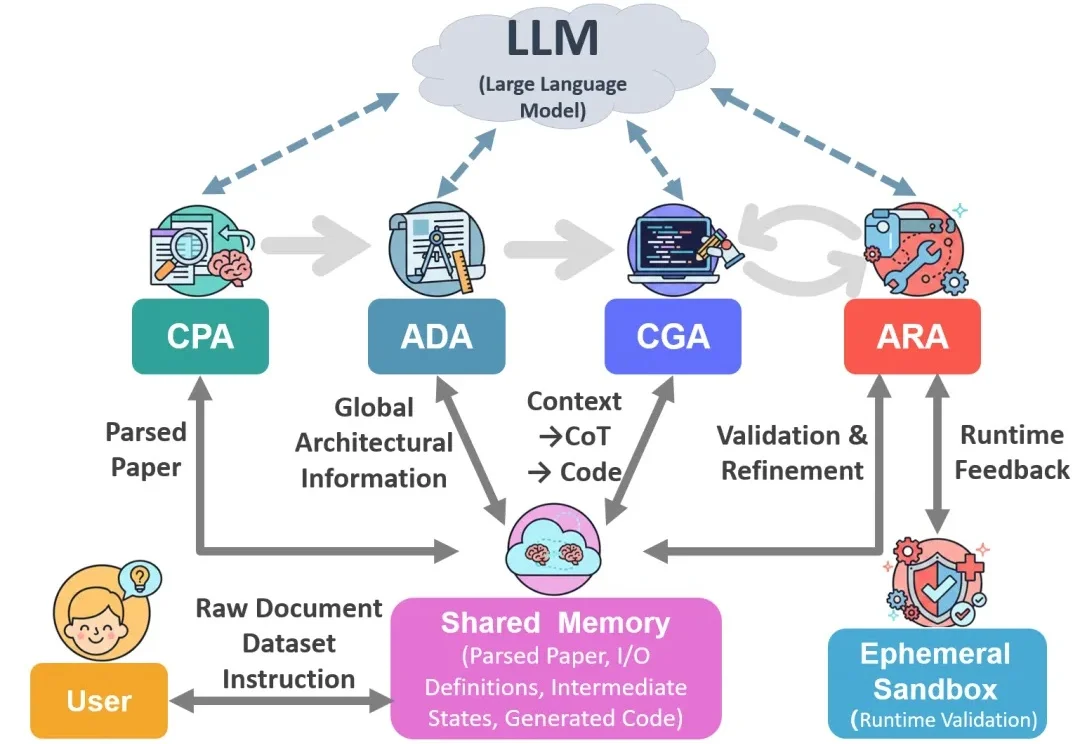
随着网络系统研究复杂度的提升,研究结果复现通常需要研究人员依据论文描述重新实现完整系统。

过去两年,光是洛杉矶就蒸发了四万多个影视岗位。美国的报纸采编岗比2008年少了一半。这些消失的媒体人,有一批去了硅谷的大模型公司,用他们的写作经验教AI回答你的问题。每当你感到被大模型的回答击中内心的时候,写出来那句话的,就是之前的记者、编辑和纪录片导演。