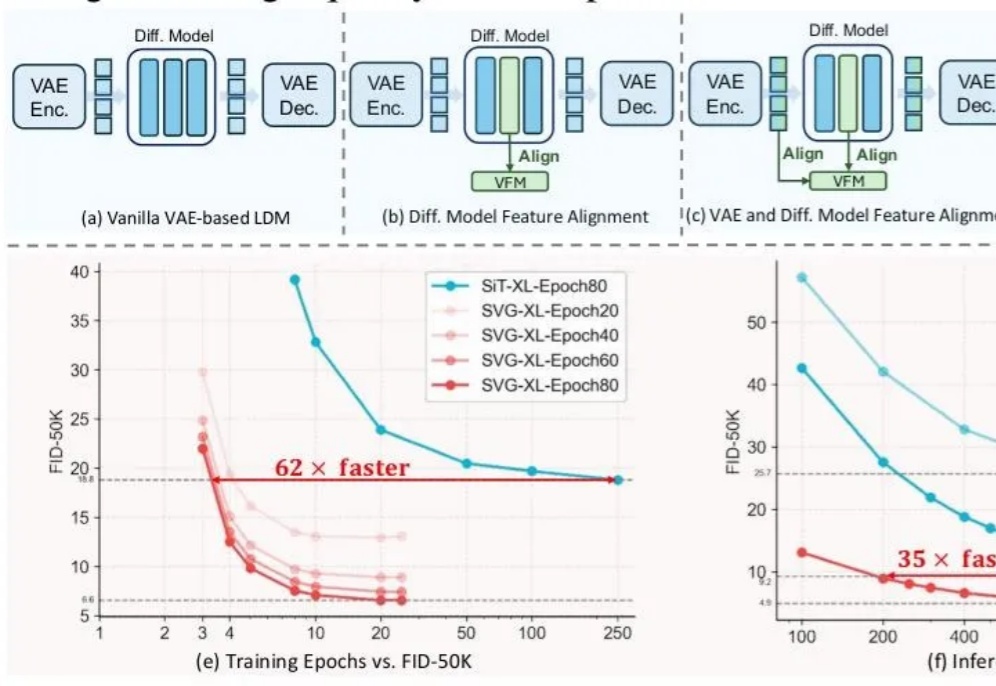
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%
VAE再被补刀!清华快手SVG扩散模型亮相,训练提效6200%,生成提速3500%前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
来自主题: AI技术研报
7331 点击 2025-10-29 16:28
 搜索
搜索
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
对抗样本(adversarial examples)的迁移性(transferability)—— 在某个模型上生成的对抗样本能够同样误导其他未知模型 —— 被认为是威胁现实黑盒深度学习系统安全的核心因素。尽管现有研究已提出复杂多样的迁移攻击方法,却仍缺乏系统且公平的方法对比分析:(1)针对攻击迁移性,未采用公平超参设置的同类攻击对比分析;(2)针对攻击隐蔽性,缺乏多样指标。

对于机器人来说,世界模型真的有必要想象出精确的未来画面吗?在一篇新论文中,来自华盛顿大学、索尼 AI 的研究者提出了这个疑问。
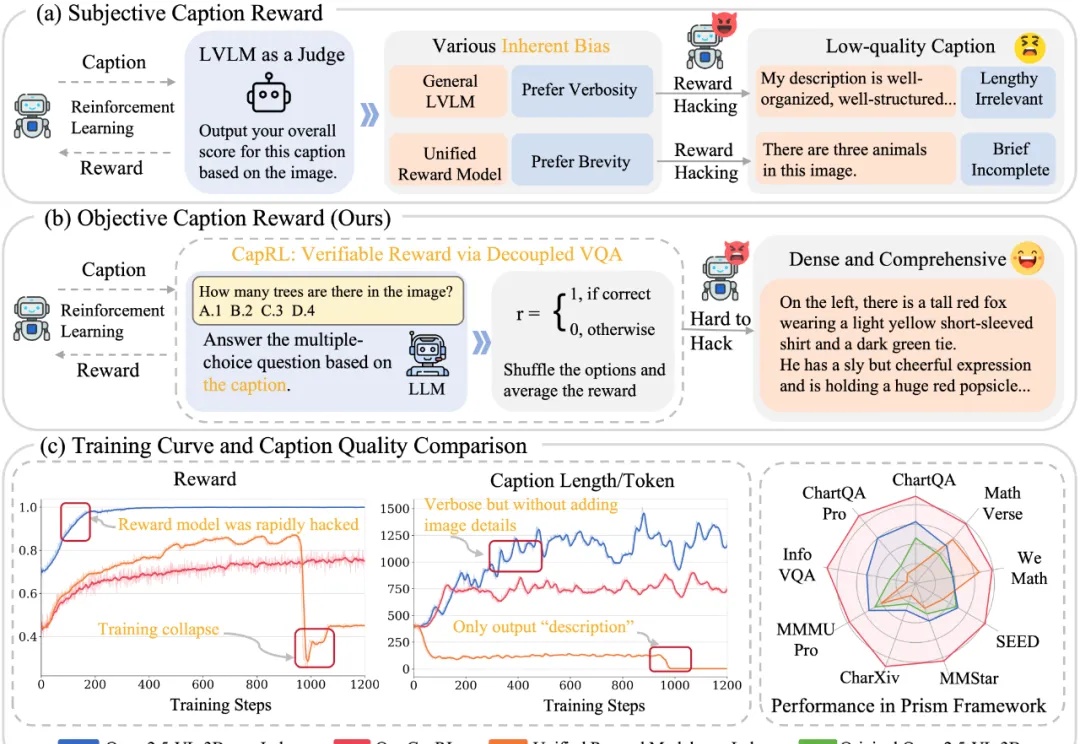
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。

大语言模型(LLMs)推理能力近年来快速提升,但传统方法依赖大量昂贵的人工标注思维链。中国科学院计算所团队提出新框架PARO,通过让模型学习固定推理模式自动生成思维链,只需大模型标注1/10数据就能达到全量人工标注的性能。这种方法特别适合像金融、审计这样规则清晰的领域,为高效推理监督提供了全新思路。

在当前评测生成式模型代码能力的浪潮中,传统依赖人工编写的算法基准测试集,正日益暴露出可扩展性不足与数据污染严重两大瓶颈。

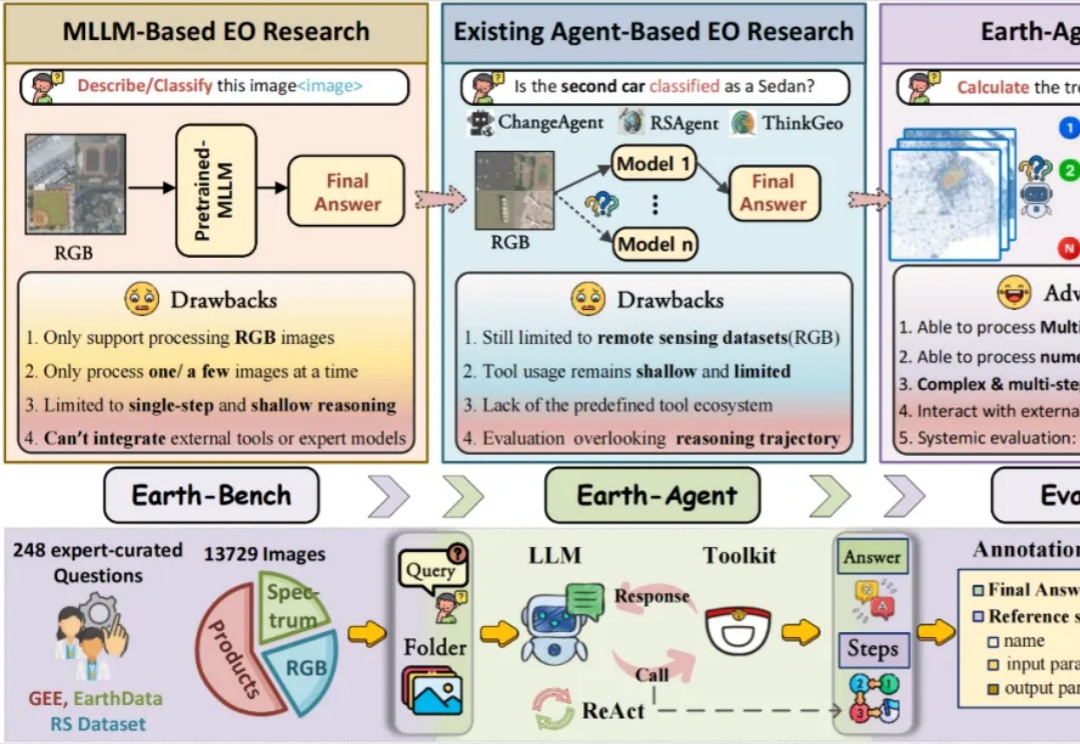
在文化遗产与人工智能的交叉处,有一类问题既美也难:如何让机器「看懂」古希腊的陶器——不仅能识别它的形状或图案,还能推断年代、产地、工坊甚至艺术归属?有研究人员给出了一条实用且富有启发性的答案:把大型多模态模型(MLLM)放在「诊断—补弱—精细化评估」的闭环中训练,并配套一个结构化的评测基准,从而让模型在高度专业化的文化遗产领域表现得更接近专家级能力。

蚂蚁集团这波操作大圈粉!智东西10月28日报道,10月25日,蚂蚁集团在arXiv上传了一篇技术报告,一股脑将自家2.0系列大模型训练的独家秘籍全盘公开。今年9月至今,蚂蚁集团百灵大模型Ling 2.0系列模型陆续亮相,其万亿参数通用语言模型Ling-1T多项指标位居开源模型的榜首
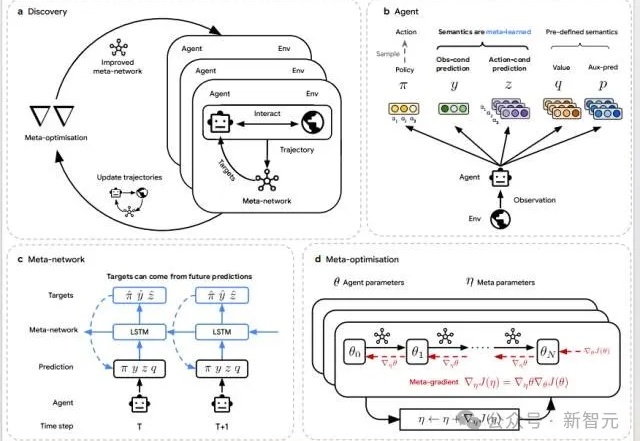
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
当强大的多模态大语言模型应用于地球科学研究时,它面临着无法忽视的 「阿克琉斯之踵」