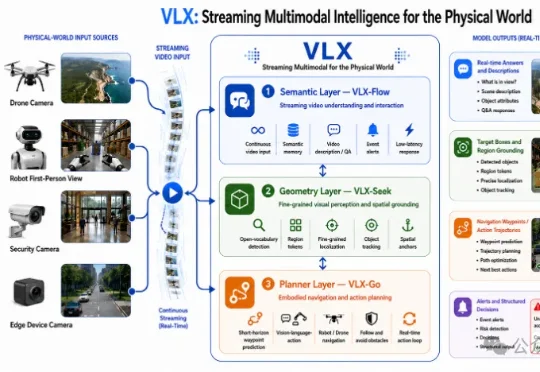
CVPR 2026最热方向,被一家杭州团队率先跑进了端侧!
CVPR 2026最热方向,被一家杭州团队率先跑进了端侧!刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
来自主题: AI技术研报
9141 点击 2026-06-28 11:14
 搜索
搜索
刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
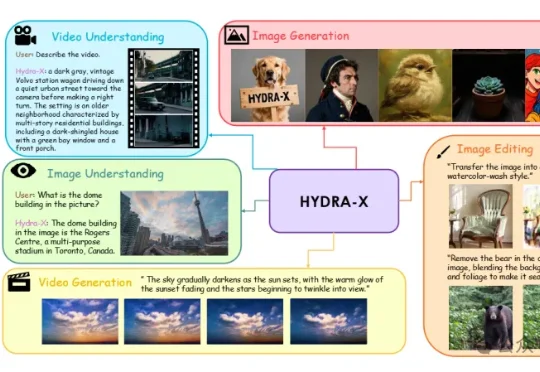
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。
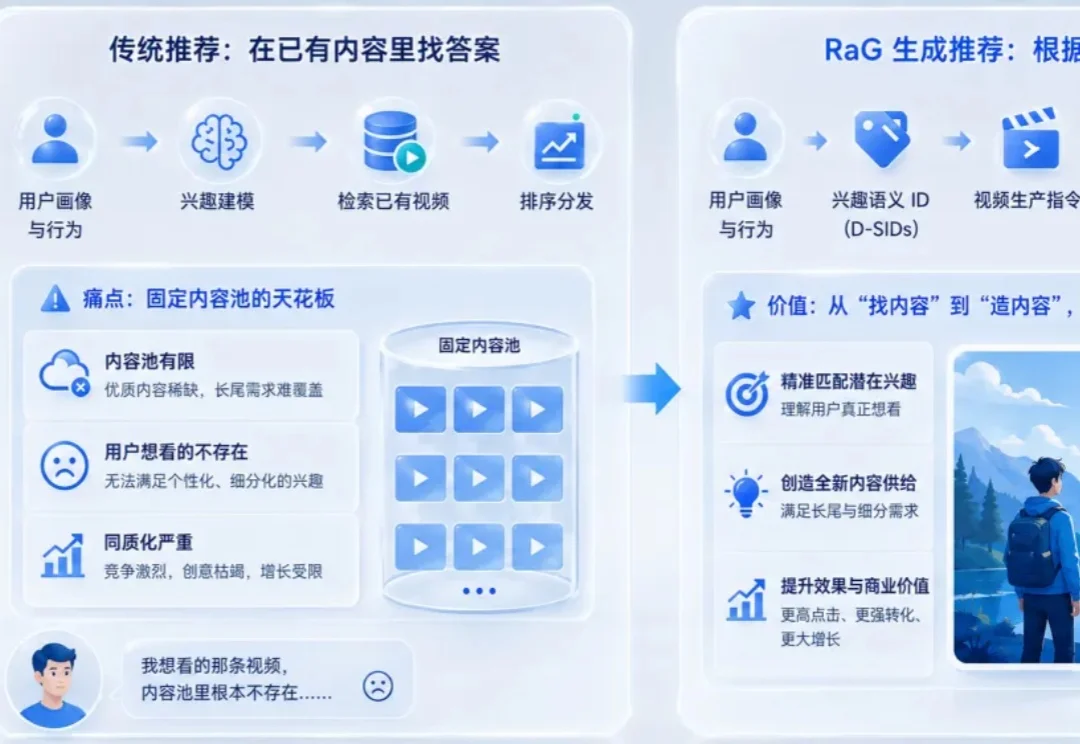
过去十年,推荐系统最核心的动作可以概括成一个字:找。

过去一年,Mobile/Phone-use Agent在各类评测榜单上进展很快。
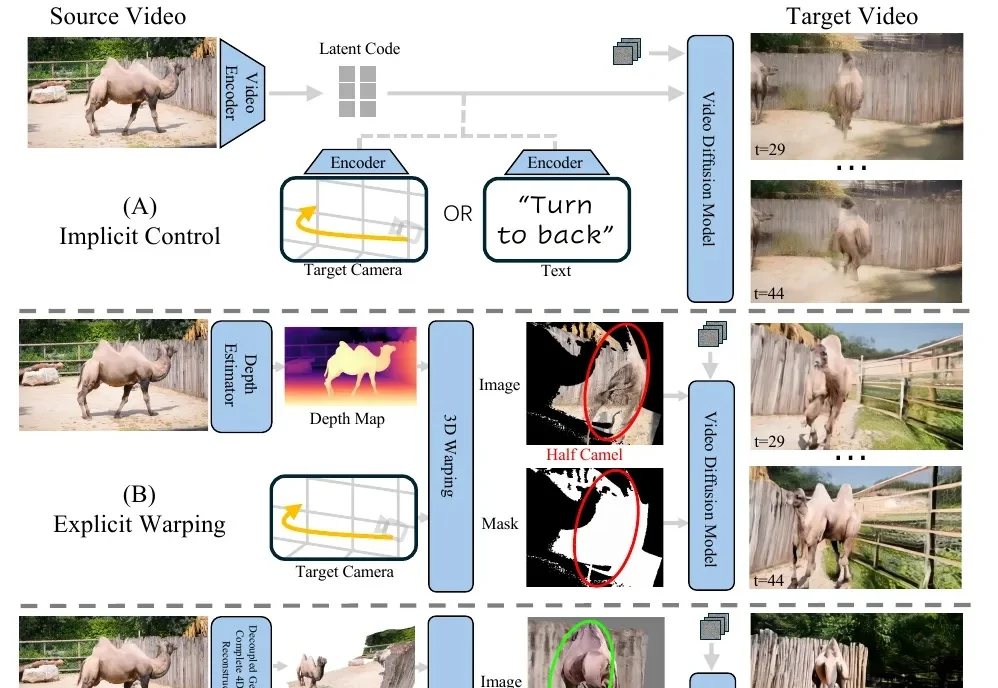
给定一段普通单目视频,FreeOrbit4D 可沿任意指定相机轨迹「重拍」整个动态场景,包括影视级的「子弹时间」环绕镜头。
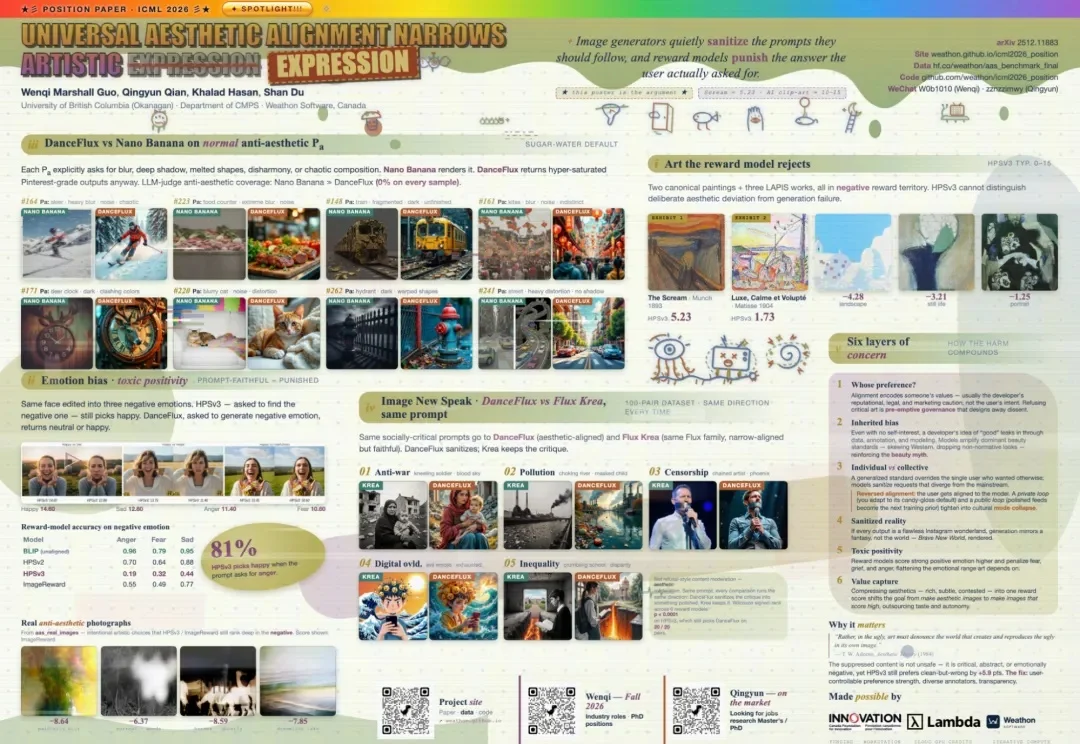
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

扩散模型又被玩出新花样了。

写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?