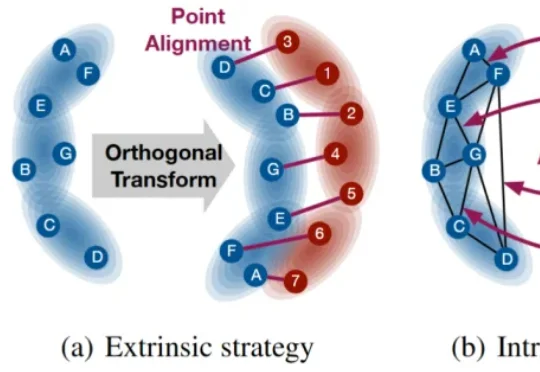
ICLR 2026 | SEINT:高效的跨空间刚体不变度量
ICLR 2026 | SEINT:高效的跨空间刚体不变度量本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
来自主题: AI技术研报
6550 点击 2026-02-18 13:28
 搜索
搜索
本文提出一种具有 SE(p) 不变传输性质的度量 SEINT:通过构造无需训练的 SE(p) 不变表示,将高维结构信息压缩为可用于 Optimal Transport (OT) 对齐的一维表征,从而在保持不变性与严格度量性质的同时显著提升效率。
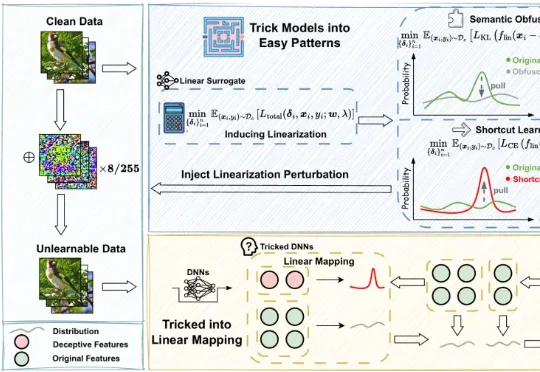
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。
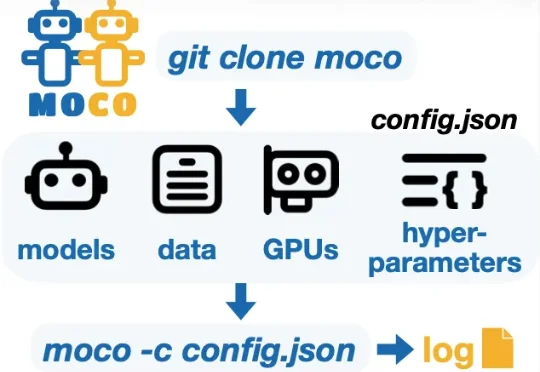
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、
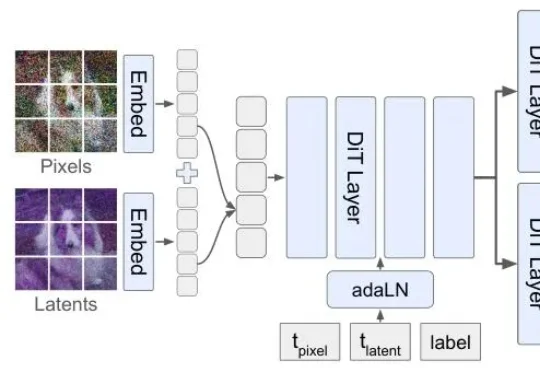
但扩散模型生图,顺序真的对吗?李飞飞团队最新论文提出的Latent Forcing方法直接打破了这一共识,他们发现生成的质量瓶颈不在架构,而在顺序。
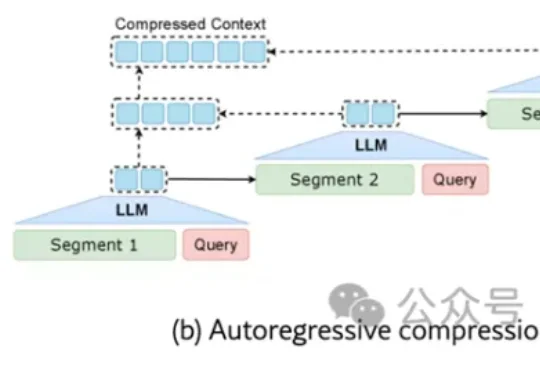
来自清华大学、鹏城实验室与阿里巴巴未来生活实验室的联合研究团队发现:现有任务相关的压缩方法不仅陷入效率瓶颈——要么一次性加载全文(效率低),要么自回归逐步压缩(速度慢),更难以兼顾“保留关键信息”与“保持自然语言可解释性”。

随着 MiniMax M2.5 的发布并在社区引发热烈反响,很高兴能借此机会,分享在模型训练背后关于 Agent RL 系统的一些思考。 在大规模、复杂的真实世界场景中跑 RL 时,始终面临一个核心难

来自上海科学智能研究院(上智院)、北京大学、复旦大学的联合团队,提出了一套名为PackingStar的强化学习系统,一口气刷新了25-31连续7个维度的世界纪录。

清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。
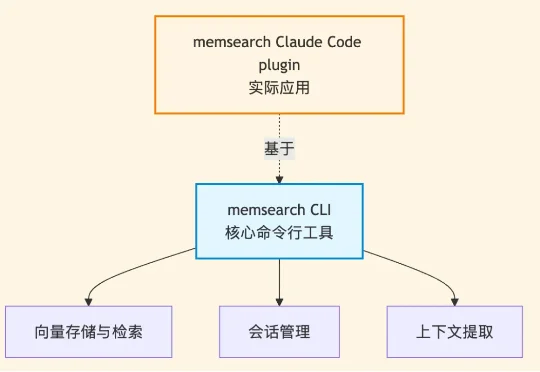
但考虑到在代码领域,如何做好记忆与检索,相比其他场景又有所不同,因此,基于 memsearch CLI ,我们同时也为Claude Code 做了个永久记忆的 plugin——memsearch ccplugin(可适用所有AI coding软件)。
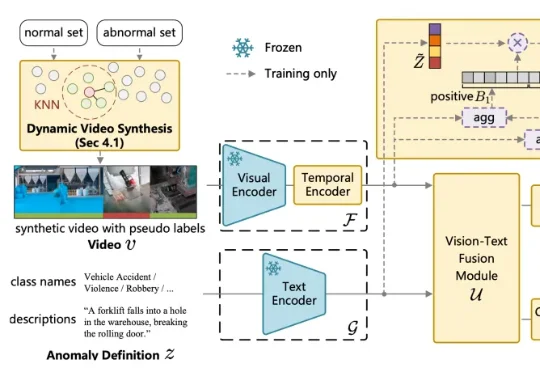
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?