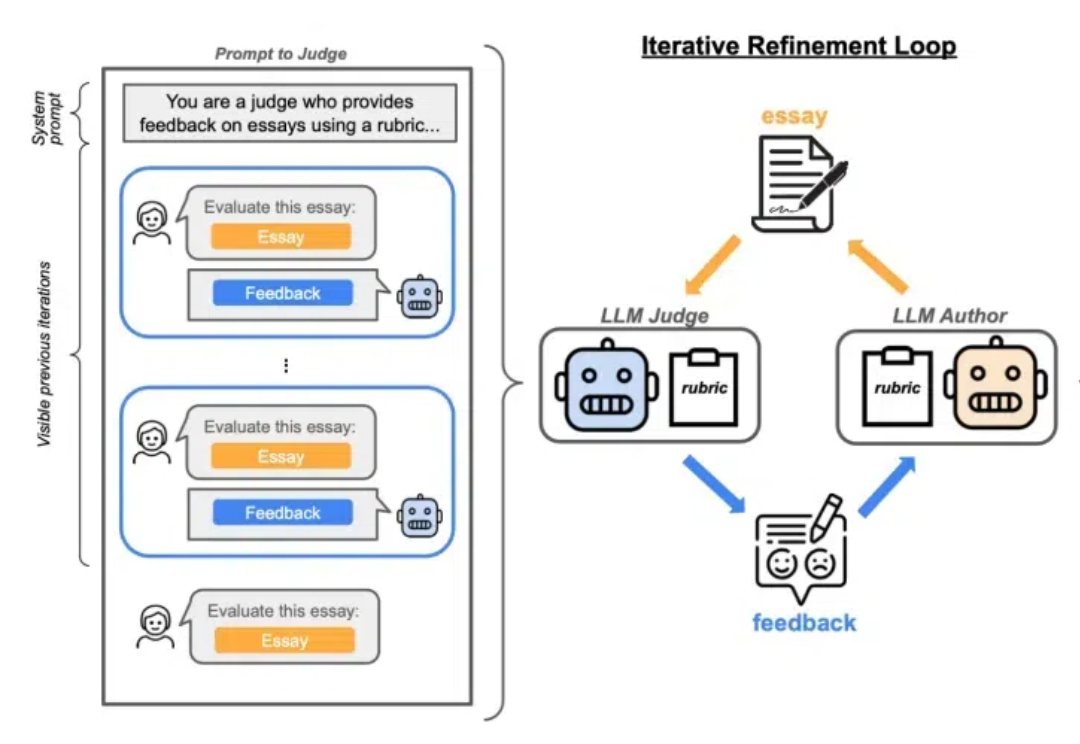
离职OpenAI后Lilian Weng博客首发!深扒RL训练漏洞,业内狂赞
离职OpenAI后Lilian Weng博客首发!深扒RL训练漏洞,业内狂赞Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
来自主题: AI资讯
9255 点击 2024-12-06 09:54
 搜索
搜索
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。
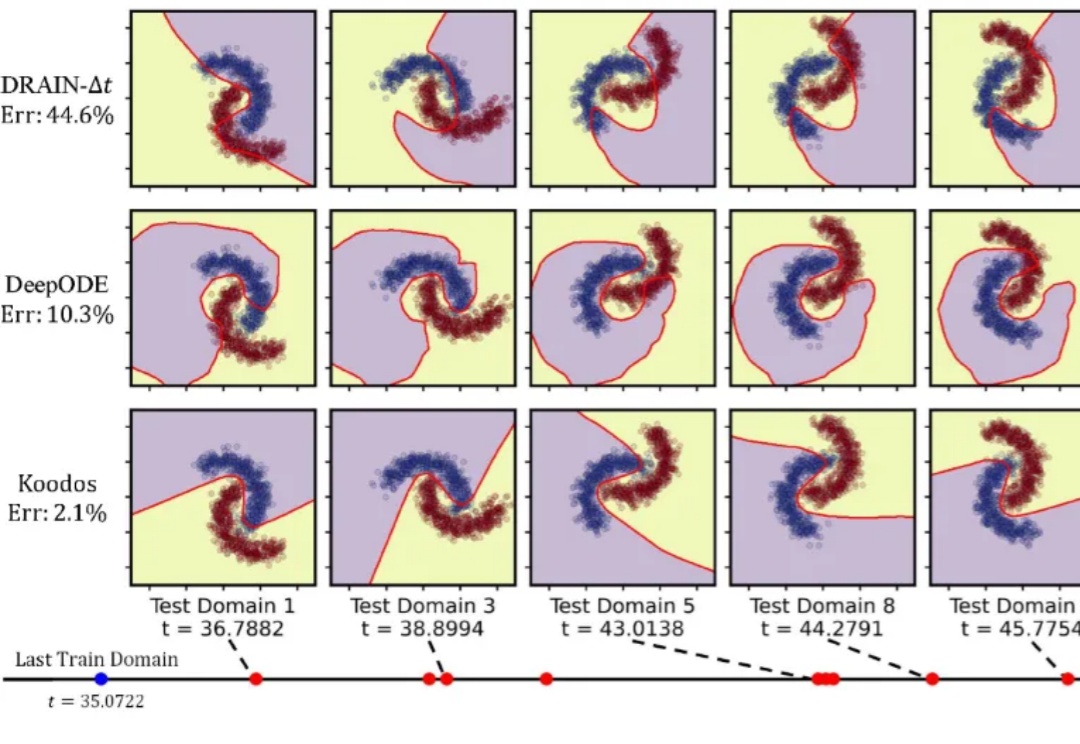
研究人员提出了一种方法,能够在领域数据分布持续变化的动态环境中,基于随机时刻观测的数据分布,在任意时刻生成适用的神经网络,实现前所未有的泛化能力。
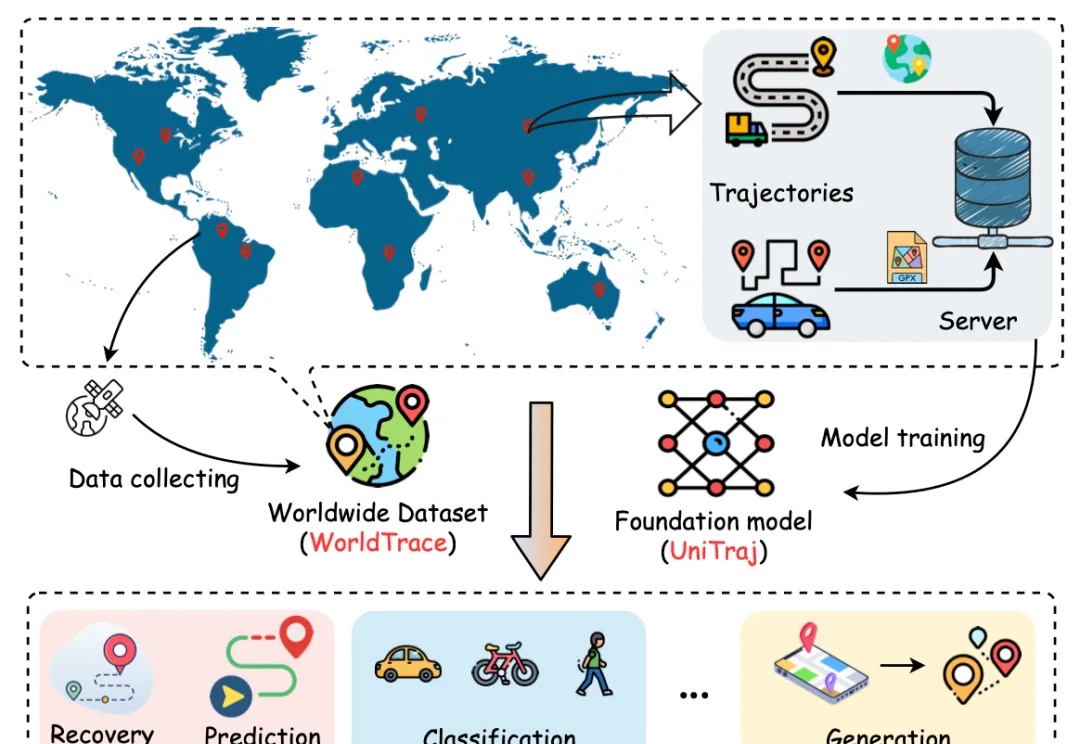
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。
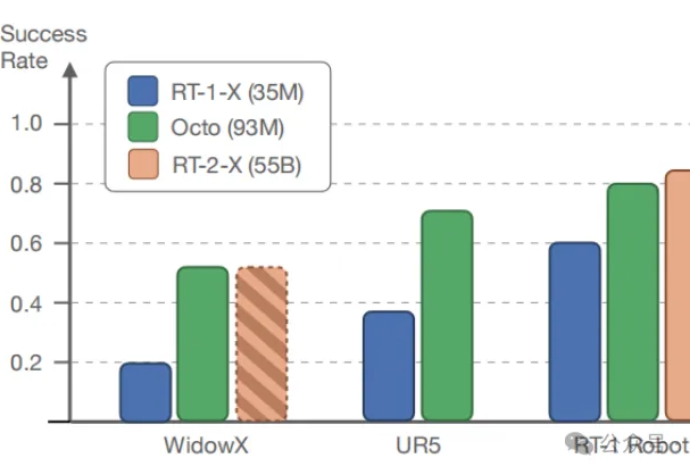
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

传统的训练方法通常依赖于大量人工标注的数据和外部奖励模型,这些方法往往受到成本、质量控制和泛化能力的限制。因此,如何减少对人工标注的依赖,并提高模型在复杂推理任务中的表现,成为了当前的主要挑战之一。
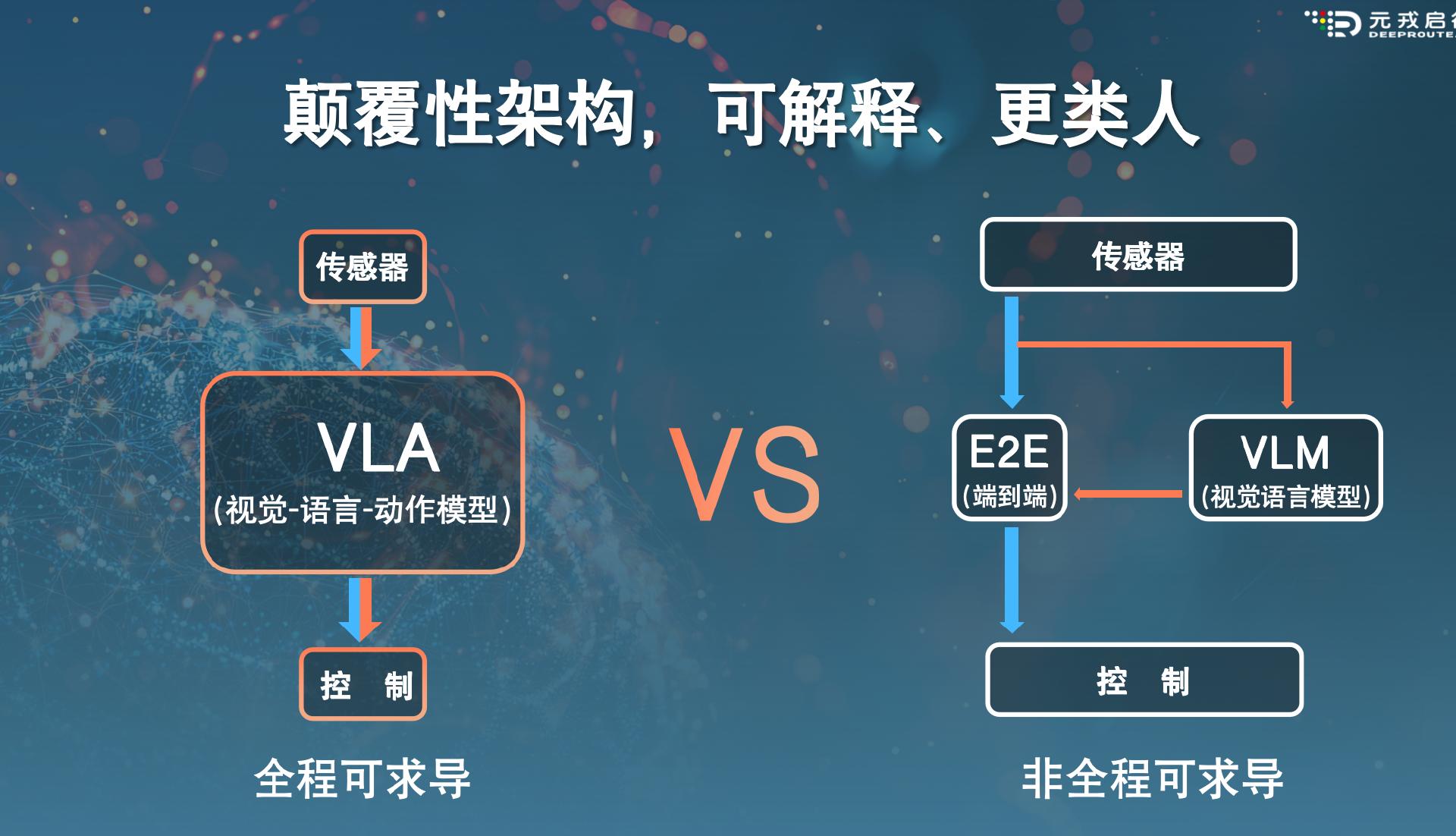
近期,智驾行业出现了一个融合了视觉、语言和动作的多模态大模型范式——VLA(Vision-Language-Action Model,即视觉-语言-动作模型),拥有更高的场景推理能力与泛化能力。不少智驾人士都将VLA视为当下“端到端”方案的2.0版本。

中国科学院上海营养与健康研究所李虹研究组多年来在抗癌药物疗效建模方向持续深耕,发表了基于分子组学预测药物响应和肝癌药物基因组相关的系列论文。但前期研究表明肿瘤用药的计算分析仍存在诸多挑战,例如:肿瘤临床前模型和病人存在差异,计算模型缺乏泛化能力;药物组合的作用机制复杂搜索空间大,对药物联用协同效果的准确和稳健估计仍很困难。

北京大学的研究人员开发了一种新型多模态框架FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。
具有强大泛化能力
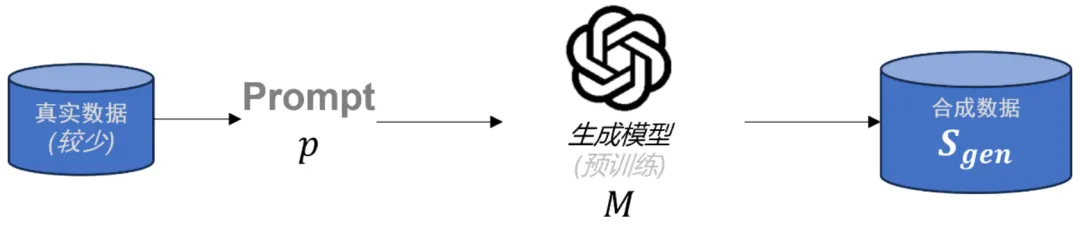
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。