重磅!谷歌开源Gemma 4 12B:统一的、无编码器的多模态模型,16G内存笔记本就可以跑
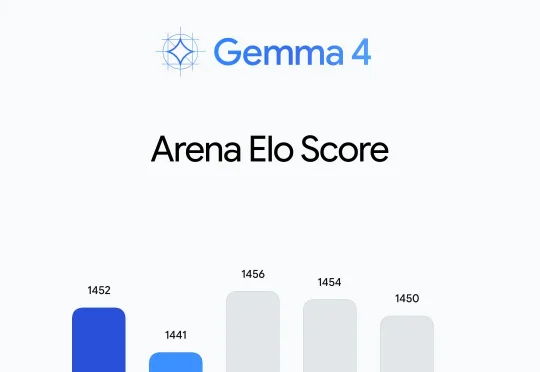
重磅!谷歌开源Gemma 4 12B:统一的、无编码器的多模态模型,16G内存笔记本就可以跑刚刚,谷歌DeepMind发布了Gemma 4 12B。一句话概括这个模型的定位:把原本需要高端服务器才能跑的多模态智能,装进你的笔记本电脑里。它填补的是Gemma家族里一个关键空缺:比边缘端的E4B更强,比26B混合专家模型(MoE)更轻。而且在整个Gemma 4系列里,它是第一个支持原生音频输入的中等规模模型。
来自主题: AI资讯
9006 点击 2026-06-04 09:46