
目标1.7万亿美元市场!高通多元化战略官宣,攥紧Agent时代算力“钥匙”
目标1.7万亿美元市场!高通多元化战略官宣,攥紧Agent时代算力“钥匙”非手机业务目标400亿美元,“飞龙”进入数据中心,高通这次整了个大的。
来自主题: AI资讯
8080 点击 2026-06-26 09:50
 搜索
搜索
非手机业务目标400亿美元,“飞龙”进入数据中心,高通这次整了个大的。

一场关于「去哪里找电」的全球竞赛,正在朝两个方向展开。

AI进军物理世界!海光携手同济大学,落地全国首个国产千卡工科智算集群,让国产算力不仅懂科学,更懂精密工程。从实验室走向大国重器,AI4E时代正式开启。
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),
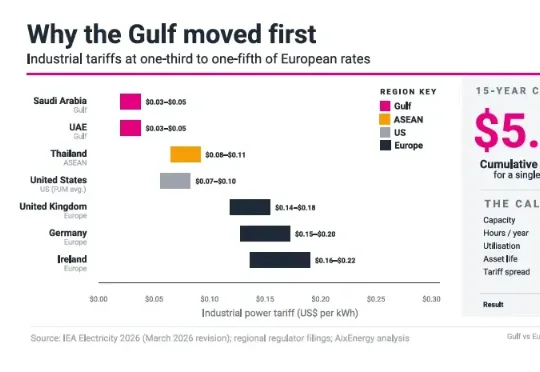
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。

Meta 已与数据中心开发商 Crusoe 达成新协议,获取 AI 计算能力,以增强其支持雄心勃勃的人工智能扩展所需的基础设施。据知情人士透露,Meta 已签约从 Crusoe 的两个数据中心购买计算容量。这些设施分别位于德克萨斯州柴尔德里斯和密苏里州沃伦顿,由于讨论内容未公开,上述人士要求匿名。
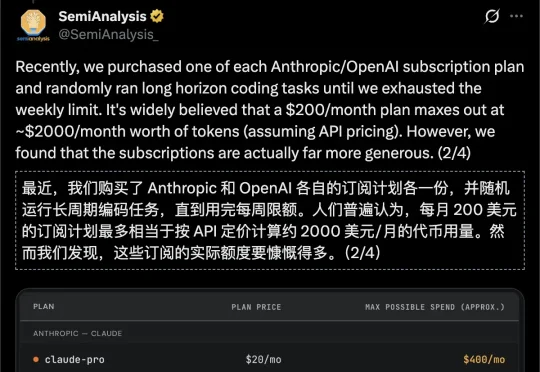
你以为自己在薅AI羊毛?OpenAI和Anthropic却在笑看账本。200美元的个人订阅,根本不是在卖服务,而是在批量培养「病毒式销售员」。

特斯拉也盯上AI基建生意了。

很多科学突破,最开始都来自一个朴素的问题:人类终于算得动了。天文学需要计算行星轨道,生物医药需要计算分子相互作用,现代 AI 需要在海量参数、数据和反馈中寻找更优解……
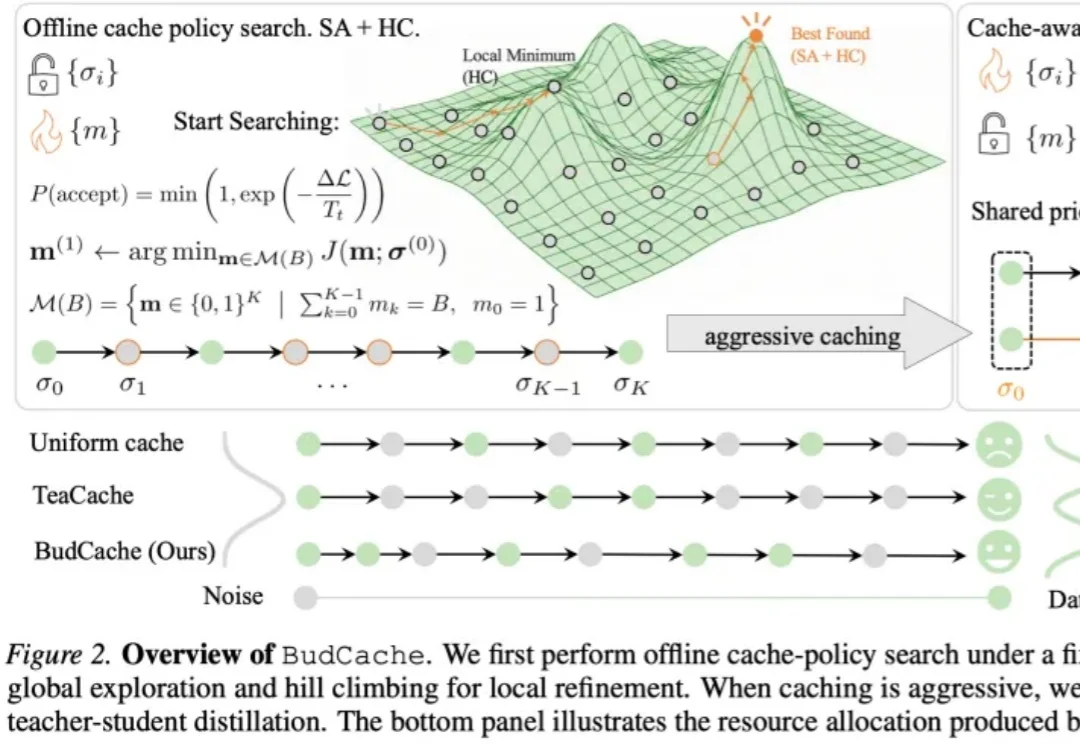
扩散模型生成得越来越好,但也越来越慢。