
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
来自主题: AI技术研报
6812 点击 2026-06-10 14:44
 搜索
搜索
具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
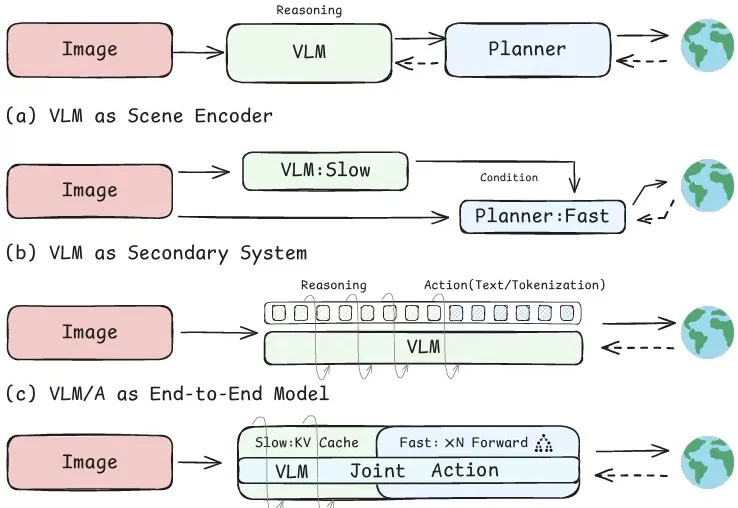
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。
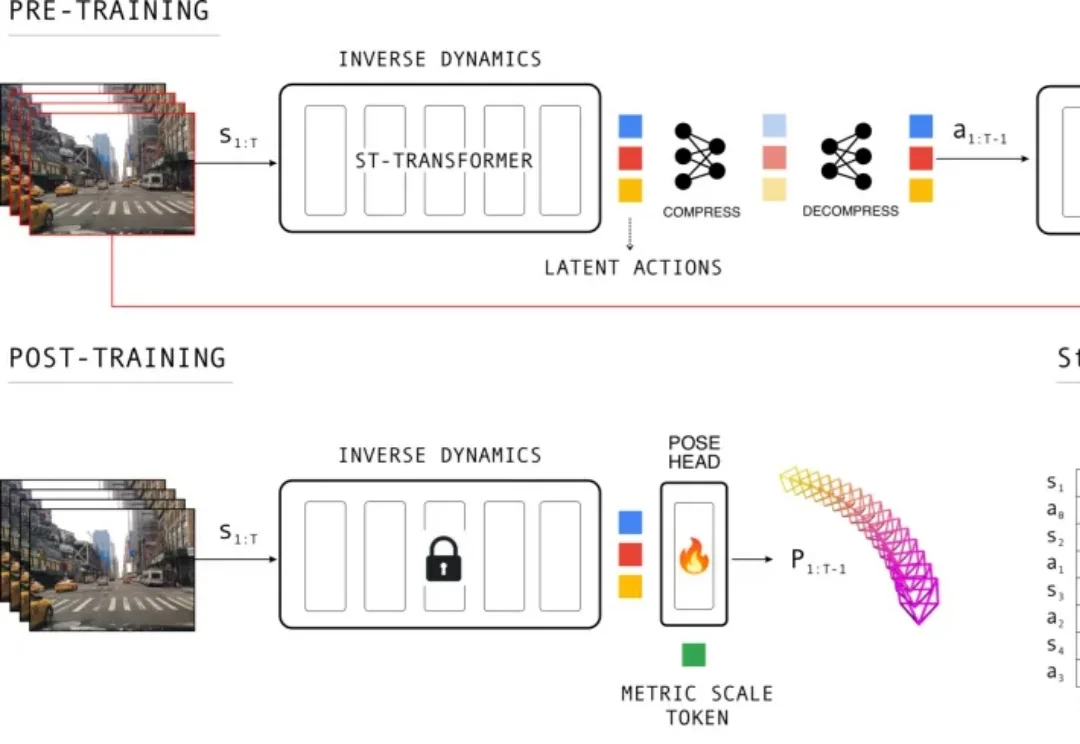
不用百万级 3D 标注,模型也能从普通驾驶视频中学会「自己是怎么动的」。Wayve 的 LA-Pose 试图把未标注视频里的运动信号,转化为自动驾驶系统所需的相机位姿估计能力。
今天,阿里发布Qoder 1.0,从AI IDE升级为智能体自主开发工作台,用户只需专注需求定义,Agent团队即可“自动驾驶”,自主完成执行、验证和交付全流程任务。目前,Windows、macOS和Linux系统用户均可下载使用。

OpenAI刚用Deep Research抢了先手,谷歌直接掀桌!DeepMind祭出研究智能体双杀,Max版质量评分从66.1%暴拉到93.3%,知识工作自动化的军备竞赛正式进入贴身肉搏。

今天,大洋彼岸,硅谷自动驾驶领域的秘密,终于有大佬站出来分享了。如果你对自动驾驶、人形机器人中炙手可热的 VLA、世界模型还有疑惑,全球“物理 AI” 领域头部的基础设施平台 Applied Intuition 两位创始人:CEOQasar Younis、CTO Peter Ludwig的分享可真的是太对口了。

从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的

4月19日,驭势科技通过港交所聆讯。吹响IPO号角,第二次。

前华为自动驾驶CTO、天才少年创办。

SLAM 在自动驾驶、机器人、AR/VR 乃至具身智能系统中都是至关重要的环节,它决定了算法能否在一个陌生环境中一边“看懂世界”,一边“知道自己在哪”。