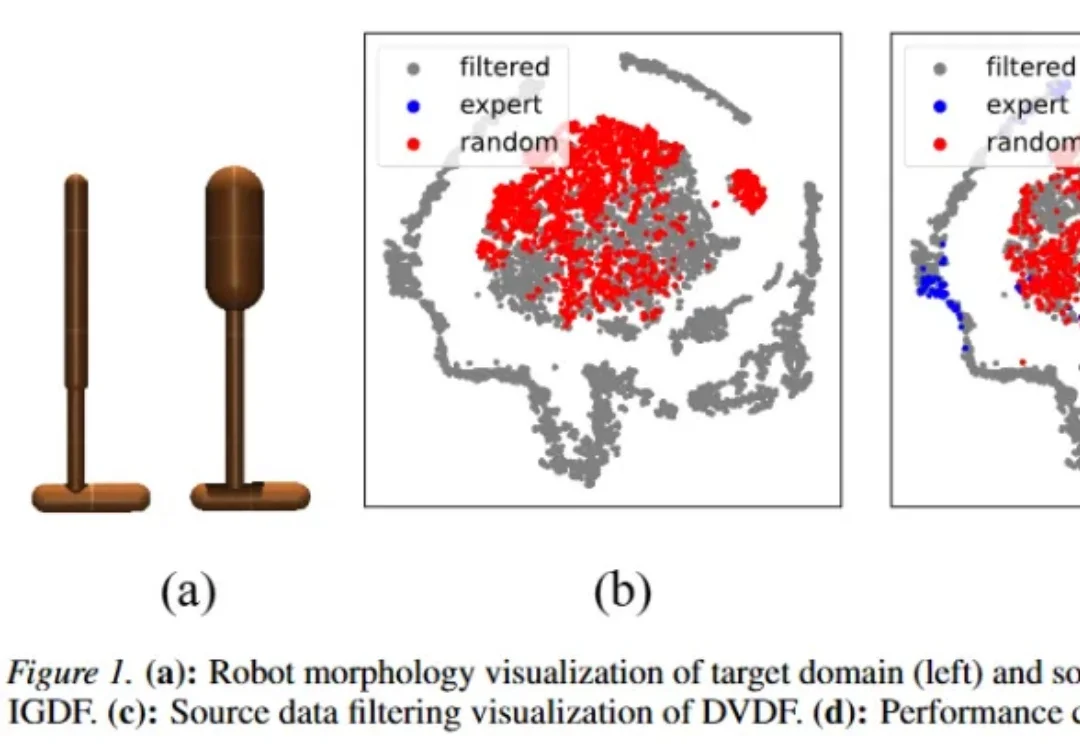
重构跨域RL框架!理论驱动「双重对齐」让跨域迁移「质变」
重构跨域RL框架!理论驱动「双重对齐」让跨域迁移「质变」在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
来自主题: AI技术研报
8508 点击 2026-04-03 09:25
 搜索
搜索
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
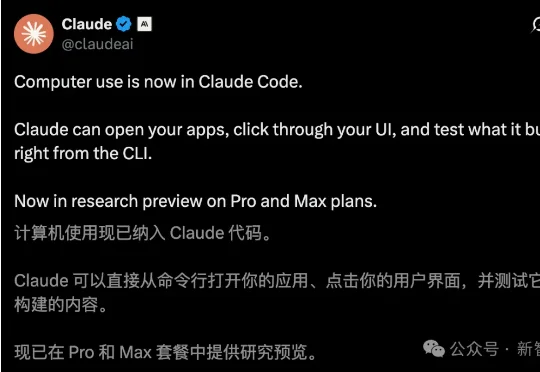
凌晨,Anthropic再次扔下一枚重磅炸弹——Claude真要起飞了!今天,Claude Code正式上线「计算机使用」,直控CLI写代码、点UI、改Bug。一键开启「自动驾驶」模式,彻底解放打工人双手。
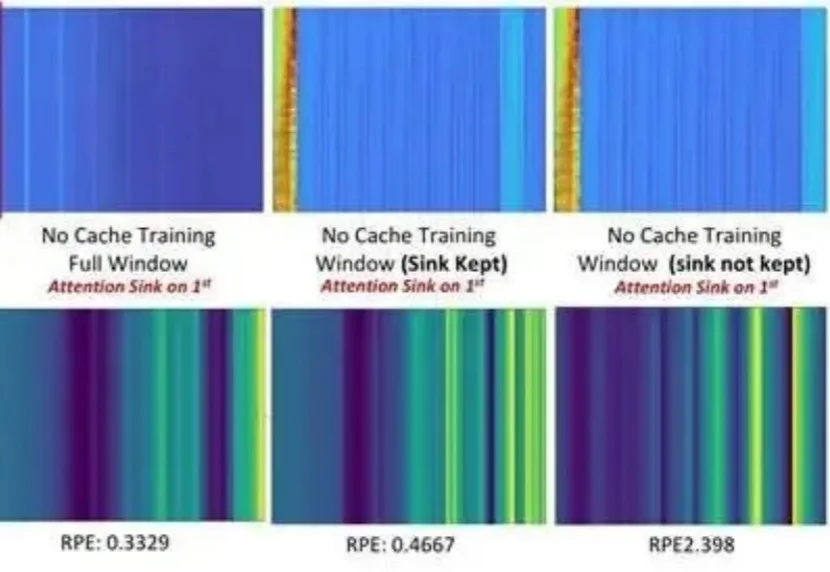
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?
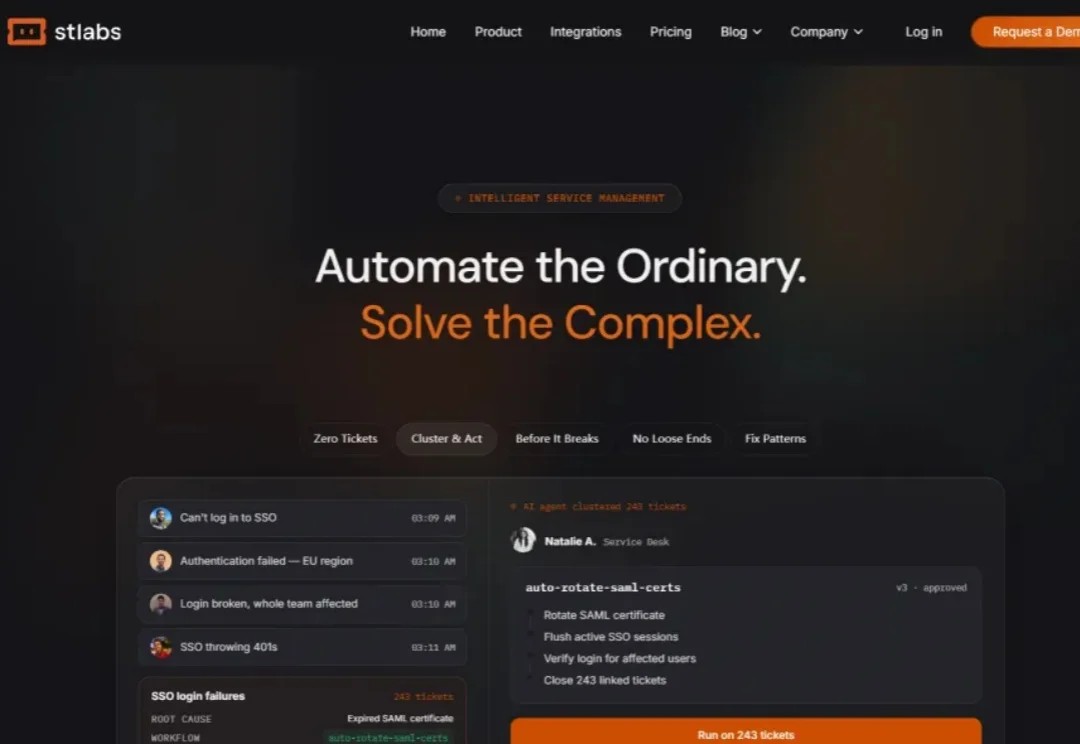
由 Datadog 前总裁阿米特·阿加瓦尔创立的 Standard Template Labs 已完成首轮 4900 万美元融资,旨在重塑大型企业内部信息技术服务的运作方式。
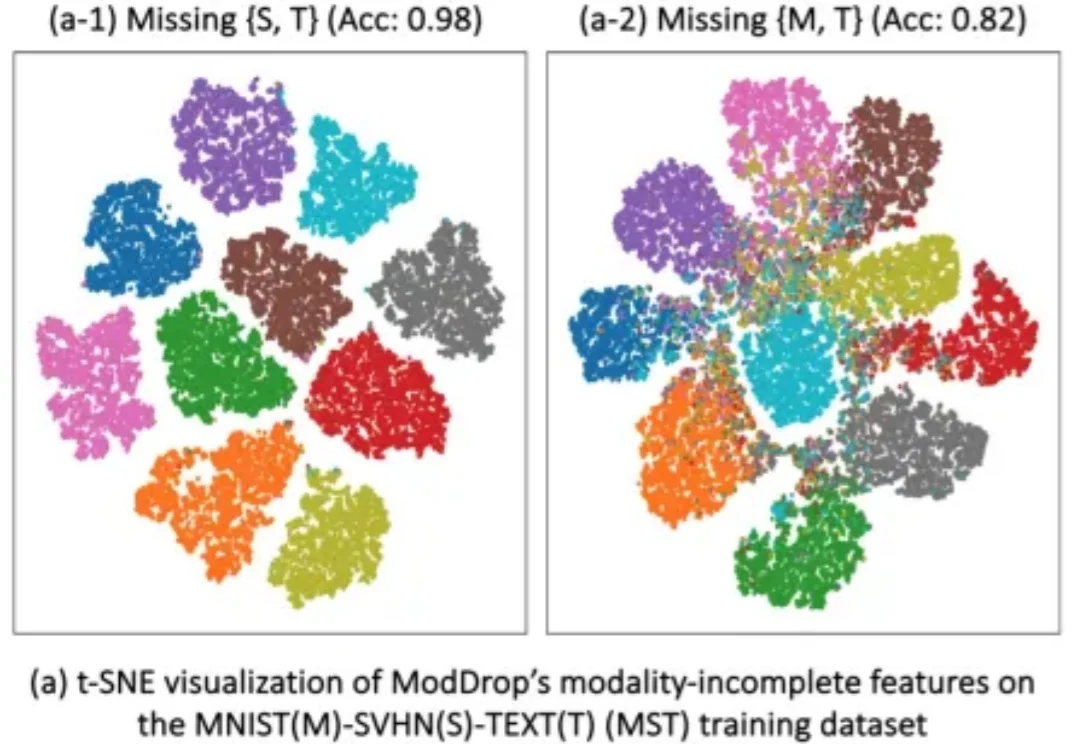
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
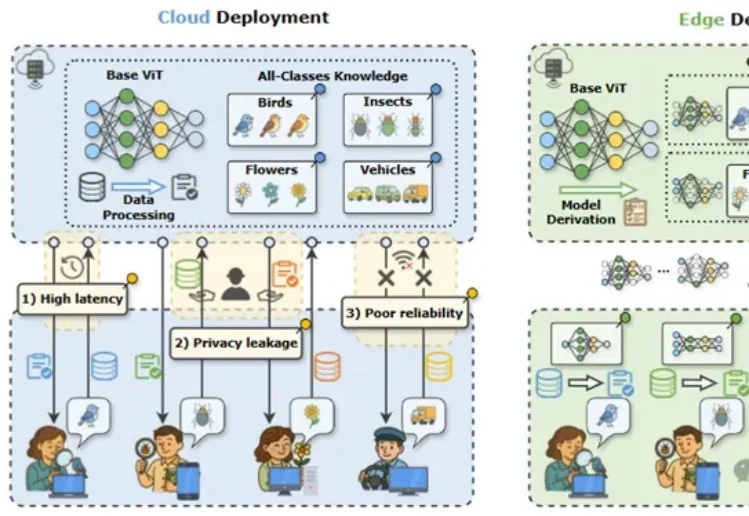
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。

自2011年成立九合创投,此后15年间,他带着团队坚持做科技领域的早期投资,陆续投了几十个智能化相关的项目——机器人软硬件通用底座提供商地瓜机器人、工业具身智能底座系统及基础设施墨影科技、陪伴机器人研发生产商赋之科技、外骨骼机器人科技公司傲鲨智能,以及自动驾驶领域独角兽Momenta,大模型智
由知名恋爱手游《奇点时代》研发商 CEO 张筱帆带头打造的 AI 男友「EVE」在年中释出 PV;明星创业者张月光打造的《星眠》也在年底透过内测首次与公众见面;我们还发现市值一度超过 180 亿美元的自动驾驶明星公司图森未来转也型做了 AI 陪伴产品「Breath of You」,尽管该产品目前已官宣停服。
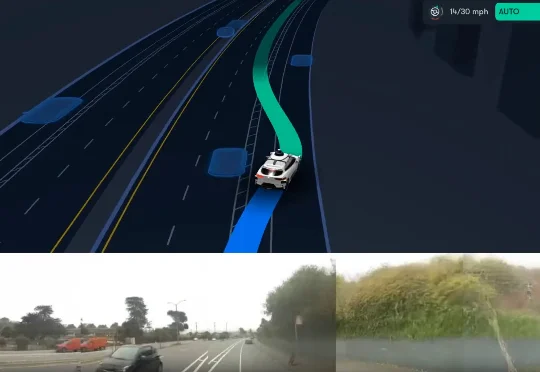
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。

Claude登陆火星!这是AI首次在外星上实现了「自动驾驶」。就在刚刚,NASA官方确认:人类历史上首次由AI全权规划的外星行驶任务,圆满完成!此次任务的具体地点在火星上的杰泽罗陨石坑(Jezero Crater)。