
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!
小众架构赢麻了!通过编辑功能 LLaDA2.1 让100B扩散模型飙出892 tokens/秒的速度!谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
来自主题: AI资讯
10886 点击 2026-02-11 10:47
 搜索
搜索
谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
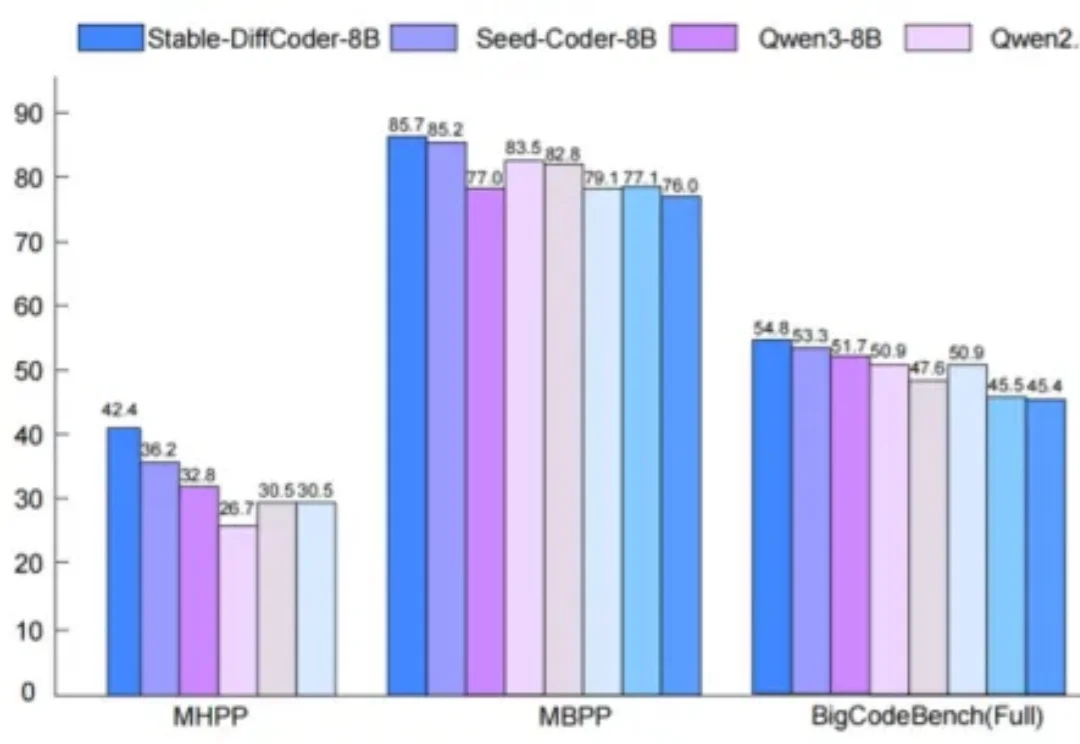
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

众所周知,大型语言模型(LLM)的根本运作方式是预测下一个 token(词元),能够保证生成的连贯性和逻辑性,但这既是 LLM 强大能力的「灵魂」所在,也是其枷锁,将导致高昂的计算成本和响应延迟。 可

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。

AI图像编辑技术发展迅猛,扩散模型凭借强大的生成能力,成为行业主流。 但这类模型在实际应用中始终面临两大难题:一是“牵一发而动全身”,即便只想修改一个细节,系统也可能影响到整个画面;二是生成速度缓慢,难以满足实时交互的需求。

自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。
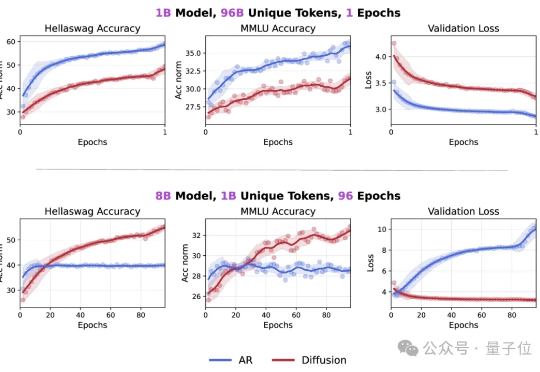
Token危机真的要解除了吗? 最新研究发现,在token数量受限的情况下,扩散语言模型的数据潜力可达自回归模型的三倍多。
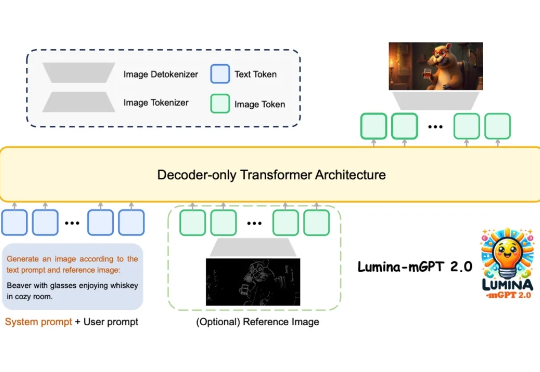
上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。