# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
近日,华中科技大学和字节跳动联合推出了 Stable-DiffCoder。这不仅仅是一个新的扩散代码模型,更是一次关于 「扩散训练能否提升模型能力上限」 的深度探索。
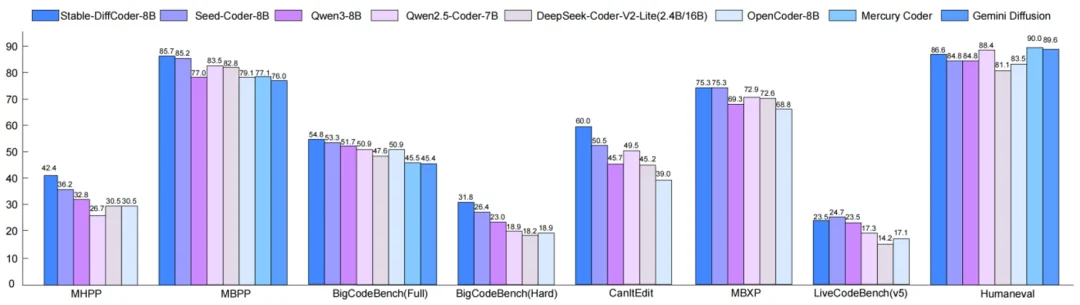
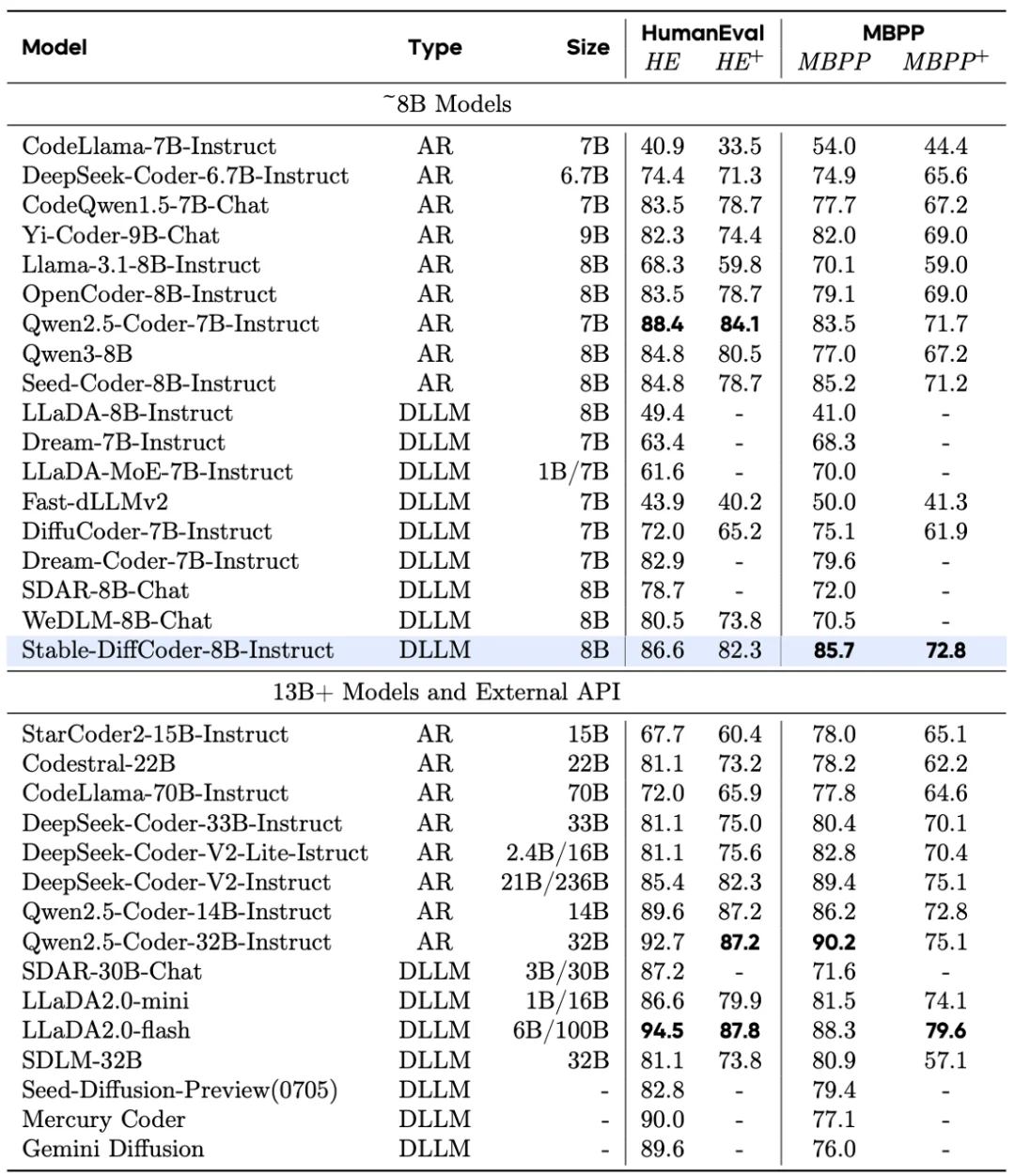
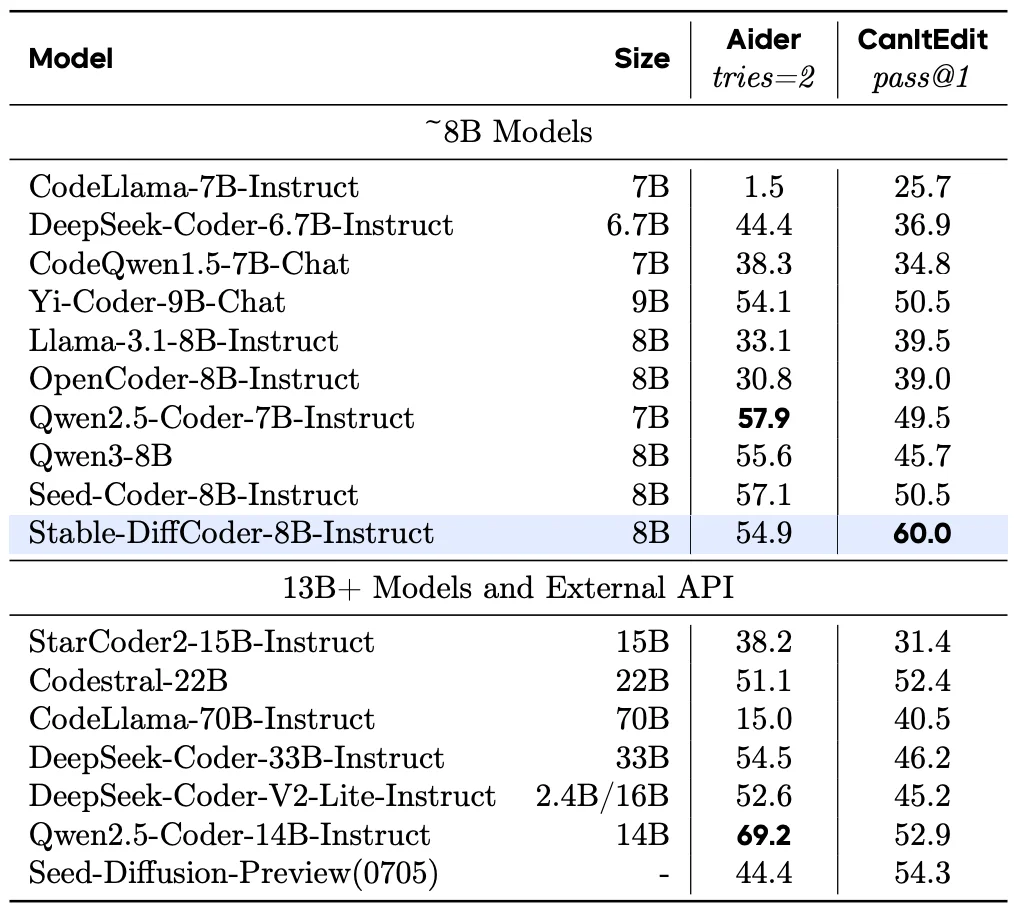
Stable-DiffCoder 在完全复用 Seed-Coder 架构、数据的条件下,通过引入 Block Diffusion 持续预训练(CPT)及一系列稳定性优化策略,成功实现了性能反超。在 多个 Code 主流榜单上(如 MBPP,BigCodeBench 等),它不仅击败了其 AR 原型,更在 8B 规模下超越了 Qwen2.5-Coder ,Qwen3,DeepSeek-Coder 等一众强力开源模型,证明了扩散训练范式本身就是一种强大的数据增强手段。

扩散过程虽然表面上可以扩充很多数据,可以作为一个数据增强的手段,但是实际上会引入很多噪声甚至错误知识的学习。
例如下面的例子:
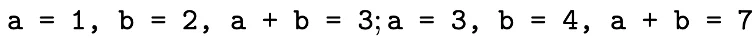
将其 mask 成

可以发现对于最后一个 mask_n,其只能在看见 a=1,b=2 的情况下去学习 a+b=7,会形成错误的知识映射。最后充其量也只能学到,a=3,b=4 在 a+b = 这个语境下的共现概率更大一点,不能学到明确的加法规则。
论文通过建模这个知识的学习来解释这个现象:
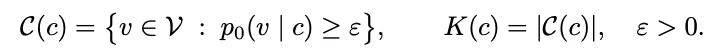
假设 c 是当前可见的样本,根据真实分布通过这些样本在当前位置能够推理出的 token 集合为 C (c),大小为 K (c)(这里多个 token 同时推理的情景一致,因此只简单的考虑单个 token 推理)。由于使用的真实分布来定义的,所以 c 越多越干净的时候,K (c) 越小。

因此,如果用纯双向的扩散过程,在 mask 比例较大的时候,当前 token 见到的 c 变小,不干净的概率变大,导致 K (c) 变大,难以映射到清晰的规则。同时其会产生会产生各种各样的 c,平均每个 c 的学习量会减小。另外,还要保证训练采样的 c 跟推理用的 c 是一致的,才能更好的使用训练学习的知识。
接下来论文通过在 2.5B 的模型设计实验来进一步阐释并证明这个结论。论文从一个 AR model 初始化,然后训练一段新的知识。论文设计了 3 个训练方式来探索:
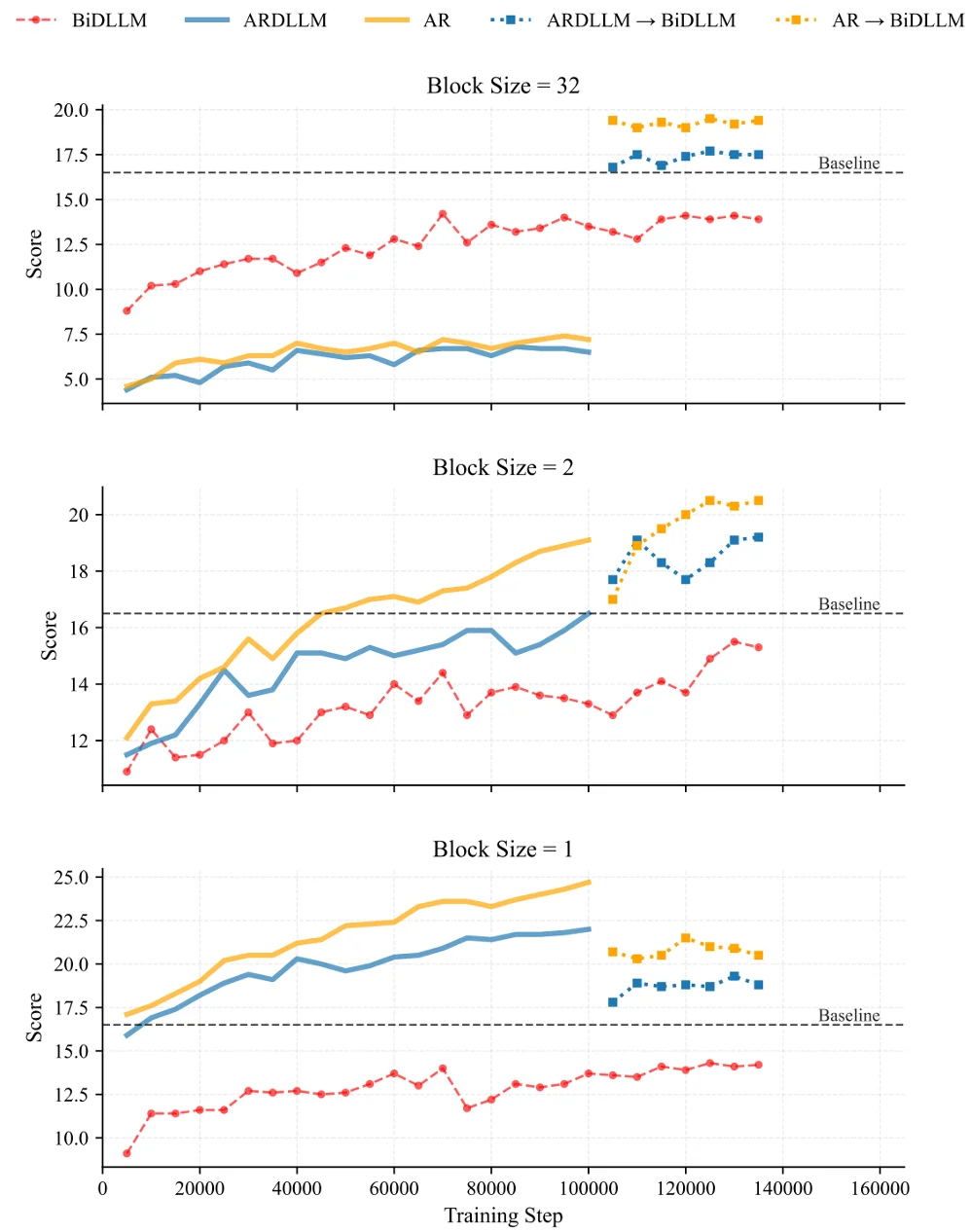
(1)AR->BiDLLM: 用 AR 的方式继续训练,在 100k step 的时候 CPT 成双向的 DLLM。
(2)ARDLLM->BiDLLM: 用 AR 的结构,但是使用纯双向的采样模式来训练。然后 100k step CPT 成 BiDLLM。
(3)BiDLLM:使用纯双向的 DLLM 训练。
可以发现,最后效果是(1)>(2)>(3),这也符合前面的理论。不用随机 [MASK] 的(1)方案对于知识有更快的压缩速度,并且转换成 BiDLLM 也保持着最佳性能,这可以证明在要高效的学好一个 DLLM,可以用 AR 或者小 block size 的 block diffusion 来进行知识压缩。另外有趣的是,在 block=32 时(1)和(2)的表现比(3)差,但是在 100k 之后表现比(3)好。100k 之前可以说明,AR 采样的 c 跟 block size=32 推理过程的 c 不太匹配,但是由于 AR 压缩了大量有用的知识,稍微 CPT 一下就能适配这种推理过程。同时也可以说明,AR 这种结构的先验,可能更适合 prompt+response 这种从左侧开始推理的过程。
因此我们将训练流程设计为,先用 AR 压缩一遍知识,然后用 AR 退火的前一个 checkpoint 继续 CPT 成小 block 的 block diffusion,来探索 diffusion 过程的数据增强能力。
扩散模型的持续预训练通常对超参数的设计(如学习率)非常敏感,容易出现 grad norm 的异常变高,这也会受到各种训练架构的影响。为了保持各种训练架构的学习稳定,以及繁杂的调参过程,团队设计了一种适配的 warmup 策略。
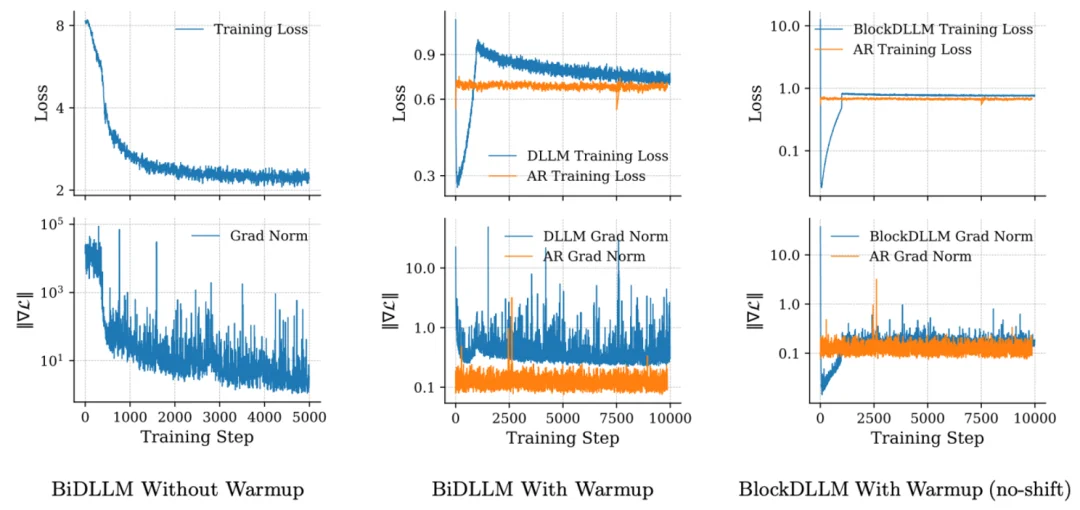
DLLM 的 CPT 过程不稳定主要受到下面 3 个原因影响:
(1)Attention 从单向变成双向
(2)Mask 变多导致任务变得很难
(3)为了对齐 ELBO,会在交叉熵前面乘上加权系数。比如只 mask 了一个 token,会等价于只计算了这个 token 的 loss,会大幅增大这个 token 对于梯度的影响,进而影响 grad norm 和 loss。
由于退火 attention 的方式难以灵活适配 flash attention 等架构,该团队针对(2)(3)来设计 warmup 过程。具体的,在 warmup 阶段将 mask 比例上界逐渐 warmup 到最大值,从而使得一开始任务从易变难。
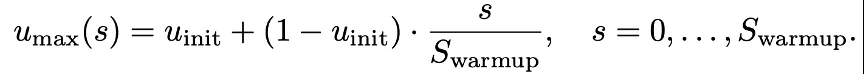
其次,在 warmup 阶段去掉交叉熵中加权的系数,从而让每个 token 对 loss 的影响更平稳:
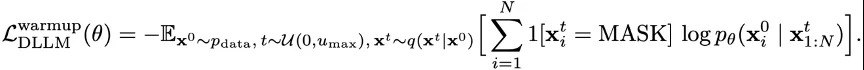
在使用 block diffusion 时,由于通过 cross attention 拼接了干净的前缀,可以使得每个 token 都产生有用的 loss。然而如果使用传统的 noise schedule 会使得有些块不产生 loss 信号,通过求解积分可以算出 block 不产生信号的概率如下,这在小 block 时会特别明显:
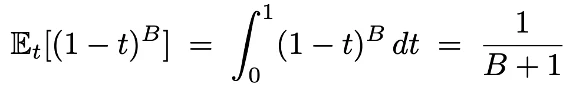
因此团队做了两个设计:(1)强制每个块都采样一个 token(2)将 noise 采样下界设置为 1/B,这样可以使得至少期望采样一个 token。同时可以避免强制采样 1 个 token 之后,原本对应的 t 过小,从而使得交叉熵加权过大的问题。
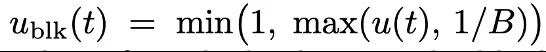
对于 Base 模型
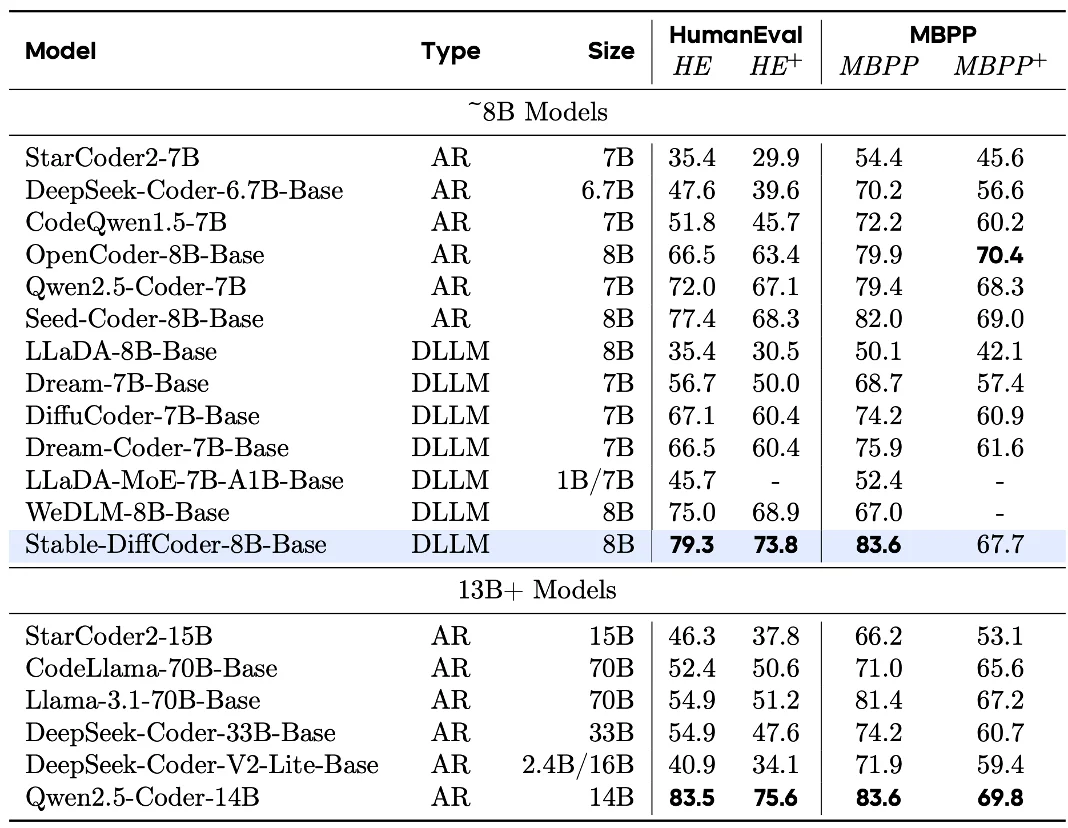
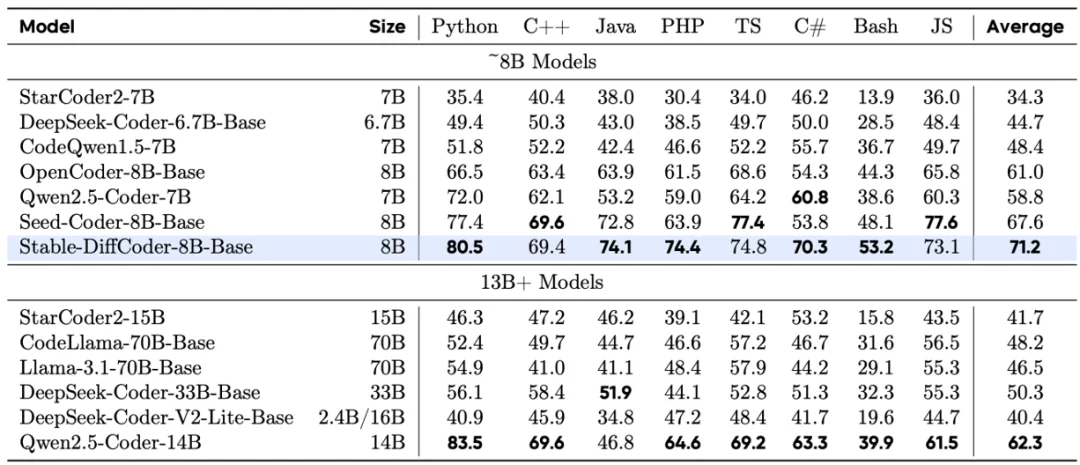
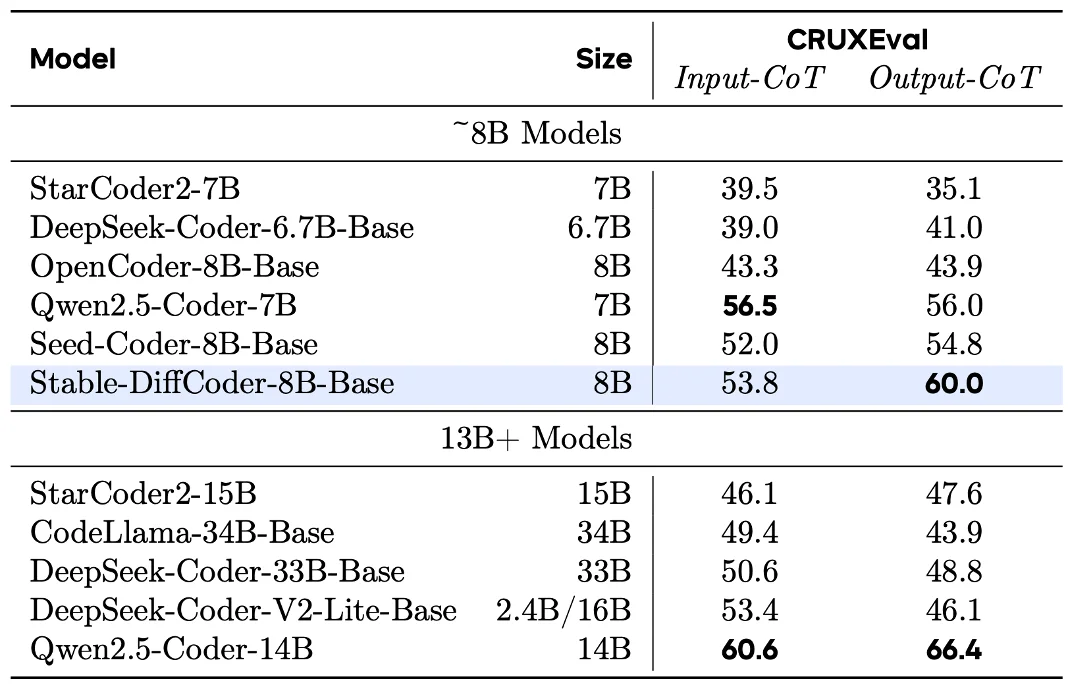
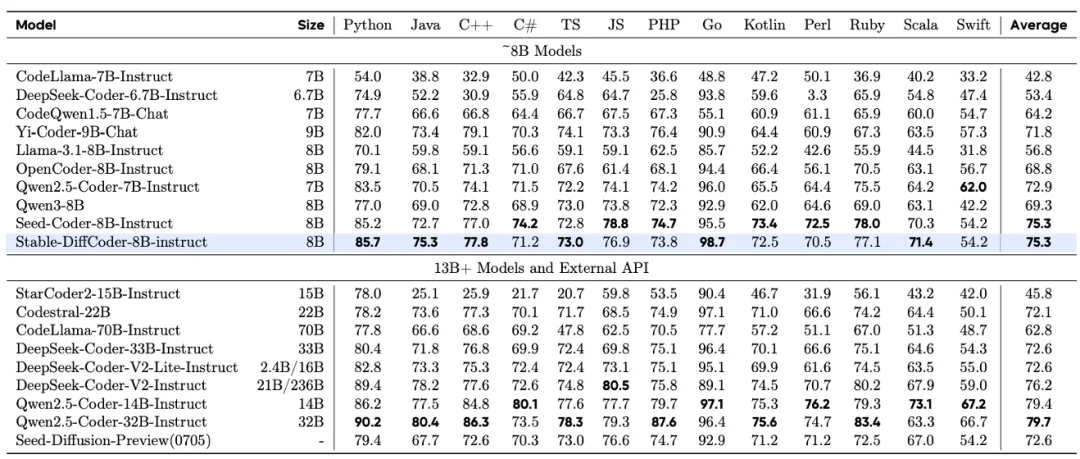
Stable-DiffCoder-8B-Base 在代码生成,多代码语言生成,代码推理上表现出色。超过一系列 AR 和 diffusion-based 的模型。另外可以发现模型在稀疏代码语言上(如 C#,PHP 等,预训练中数据较少),相比于 AR baseline 得到了大幅增强,可以证明 DLLM 的训练过程起到了一定的数据增强的效果。同时在代码推理能力上也得到了增强。
对于 Instruct 模型
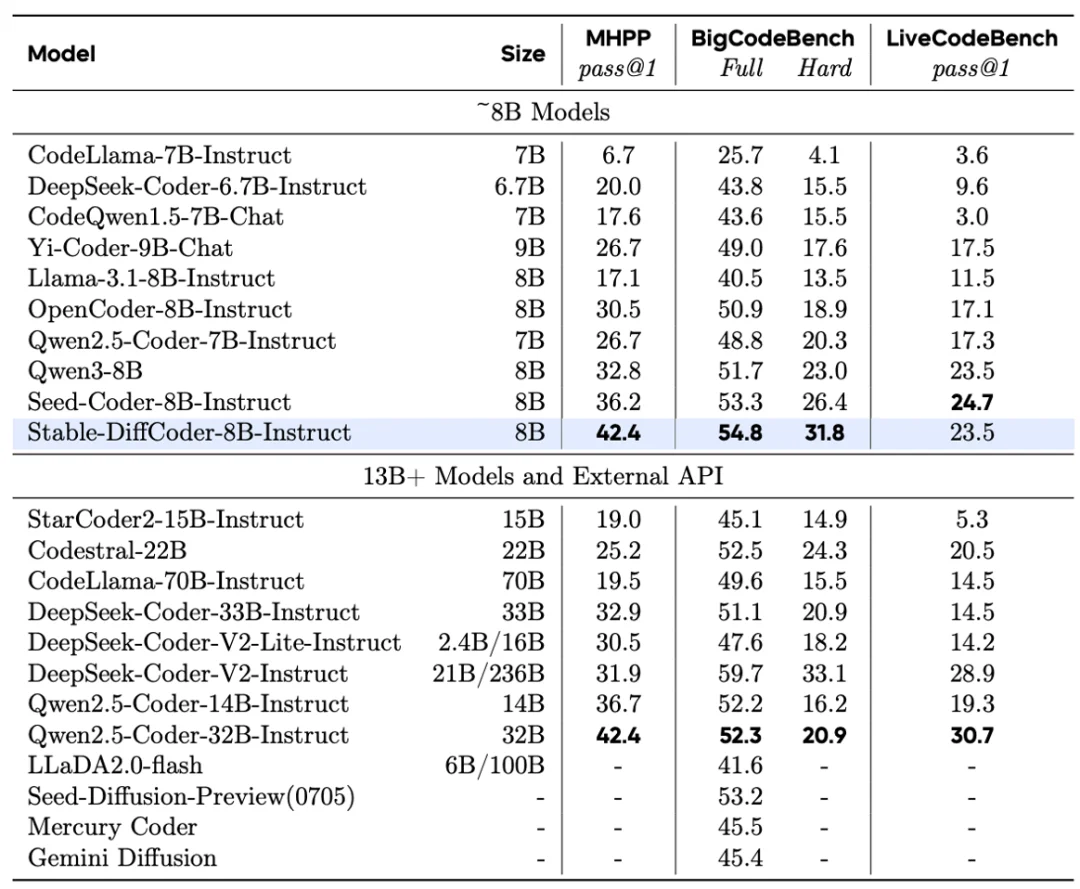
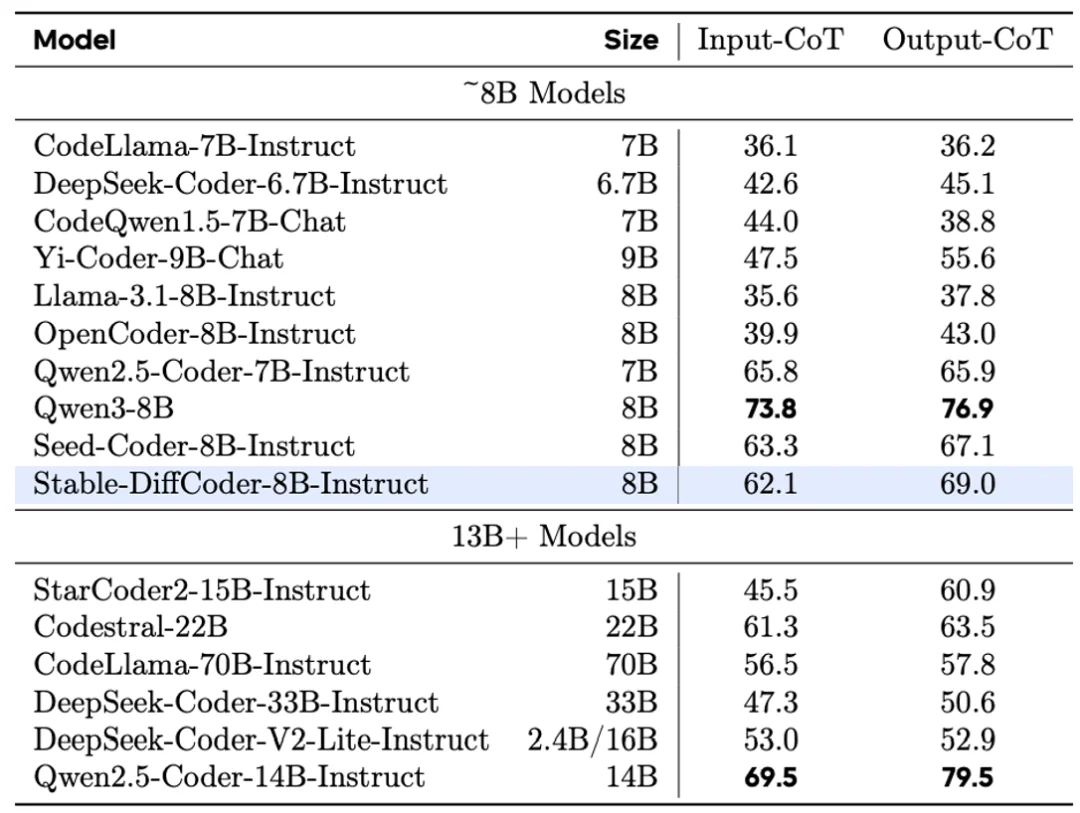
Stable-DiffCoder-8B-Instruct 在代码生成,代码编辑,代码推理等任务上做了综合评测,并有着优越的表现。其中在常用的任务(humaneval,mbpp)上大幅超过原有 AR baseline 和其他 8B 左右的 DLLM model。在测试集闭源的 MHPP 达到 qwen32B 的水平,BigCodeBench 上更是超过一系列模型并仅次于 DeepSeek236B 的模型。同时在代码编辑 CanItEdit 任务上更是有着惊艳的效果。
Stable-DiffCoder 的发布,打破了 「扩散模型只能做并行加速」 的刻板印象。它证明了:扩散训练范式本身就是一种极佳的表征学习手段。通过合理的课程设计及稳定性优化,扩散模型完全可以在代码理解和生成质量上超越传统的 AR 模型。
对于未来的大模型演进,Stable-DiffCoder 提示了一条新路径:也许我们不需要抛弃 AR,而是将 AR 作为高效的知识压缩器,再利用 Diffusion 作为 「强化剂」,进一步推高模型的智能上限。
文章来自于“机器之心”,作者 “机器之心编辑部”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
