找人不求人?Lessie 让「人脉玄学」变成算法游戏|AI 上新
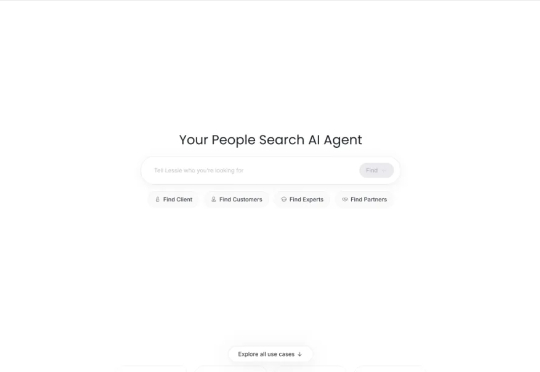
找人不求人?Lessie 让「人脉玄学」变成算法游戏|AI 上新Lessie 的定位简单直接:People Search AI Agent。一句话描述它的能力:帮你从互联网与数据库里快速找到任何人,并自动化完成初步联络。创始人、投资人、KOL、潜在客户、行业专家、合作伙伴……只要你能用自然语言描述需求,Lessie 就能迅速在全球范围内挖掘到合适的人选。
来自主题: AI资讯
8783 点击 2025-09-26 16:20