ACL 2026 Main | 不只是调用地图API,Spatial-Agent让大模型生成可执行地理分析工作流
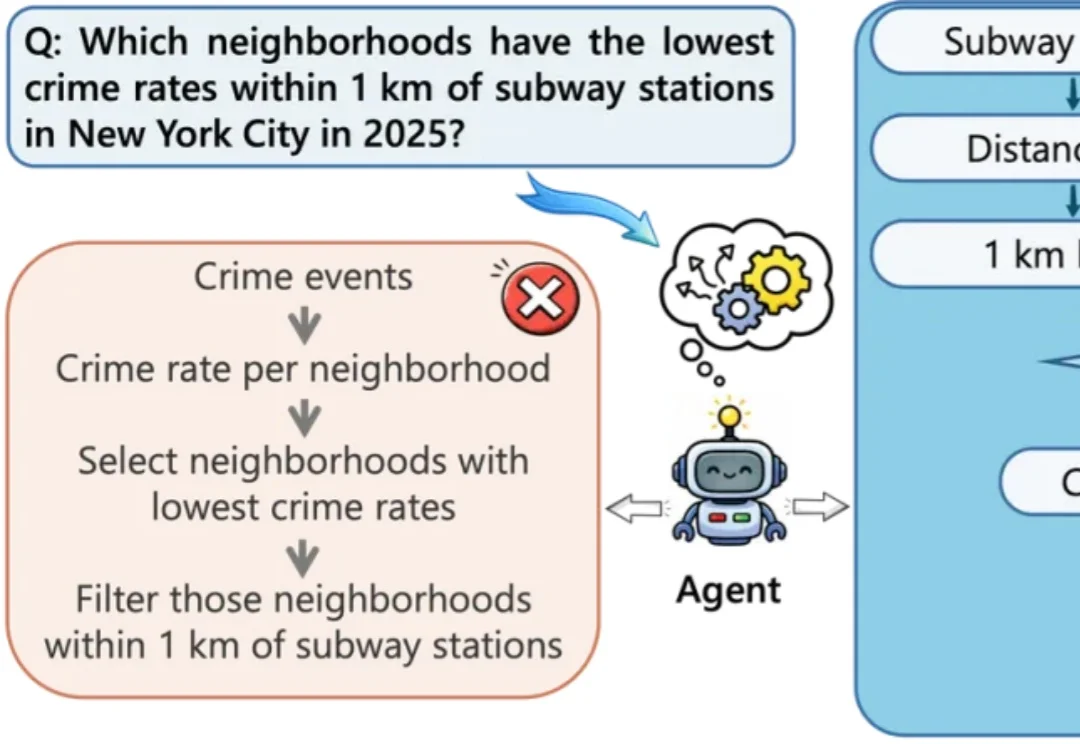
ACL 2026 Main | 不只是调用地图API,Spatial-Agent让大模型生成可执行地理分析工作流大语言模型在地图、城市、交通等空间领域的应用越来越广泛。对于这些场景来说,问题往往不只是 “查一个地点” 或 “调用一次路线 API” 就能解决的,而是需要把用户的自然语言问题组织成一段可执行、可验证的地理分析流程。
来自主题: AI技术研报
9209 点击 2026-05-26 14:57