ICML 2026 | 大模型内部也会长出「情绪树」,规模越大越懂人心
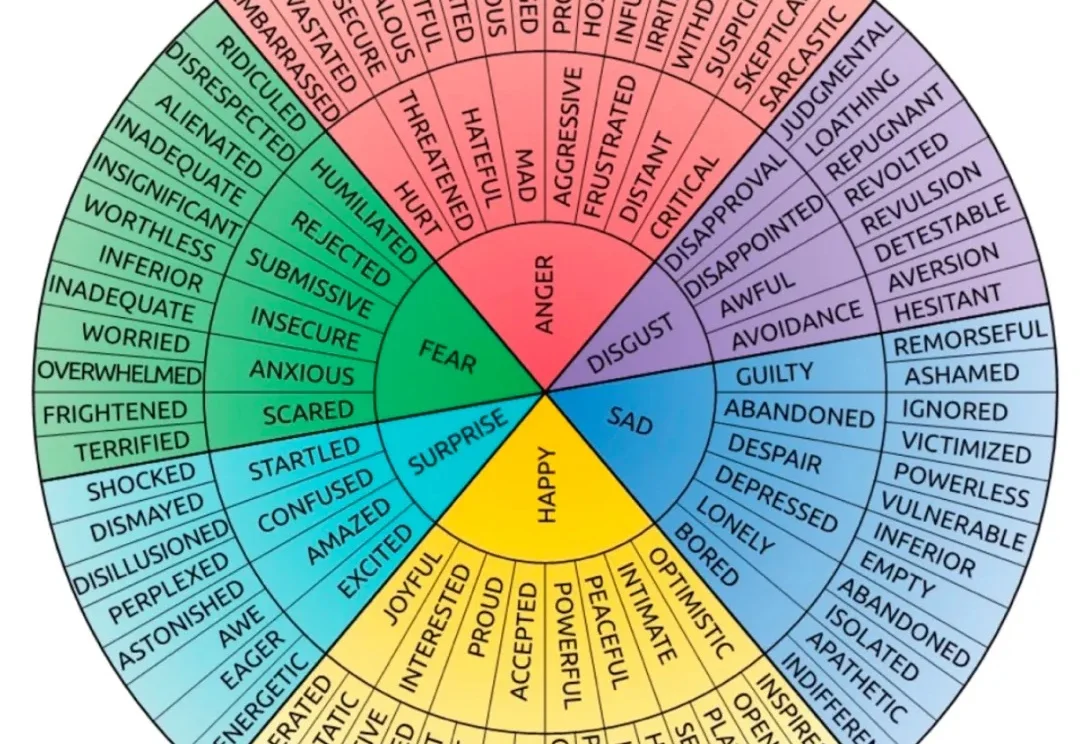
ICML 2026 | 大模型内部也会长出「情绪树」,规模越大越懂人心随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
来自主题: AI技术研报
6696 点击 2026-05-12 14:31
 搜索
搜索
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。
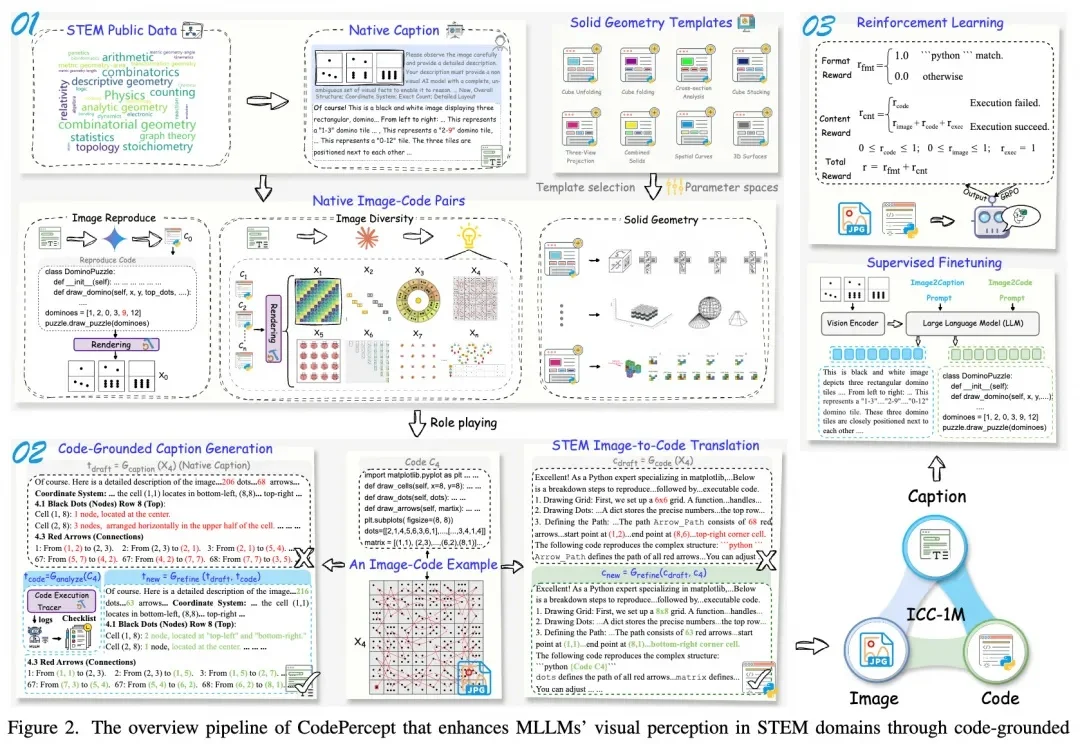
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
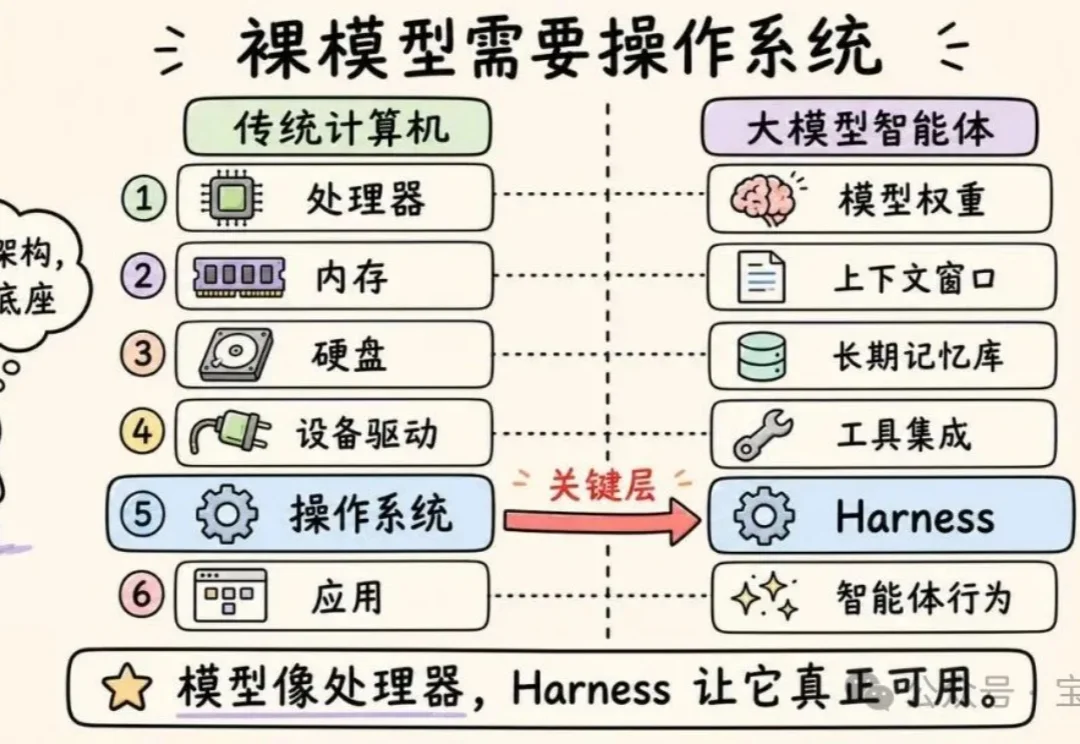
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
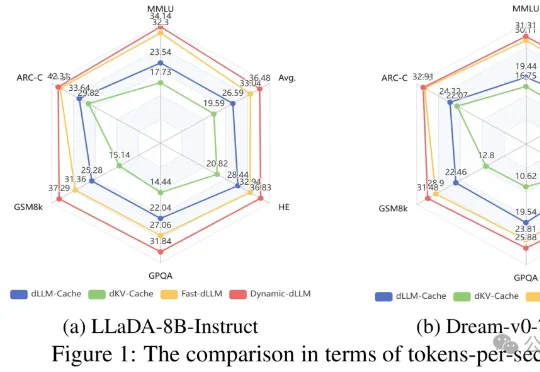
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

基于视觉语言模型(VLM)的多智能体系统(MAS)正成为复杂多模态协作的核心方案,却被一个致命痛点死死卡住:多智能体视觉幻觉滚雪球——单个智能体的视觉误判通过纯文本信息流逐级放大,早期细微错误最终演变成系统性崩溃。
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
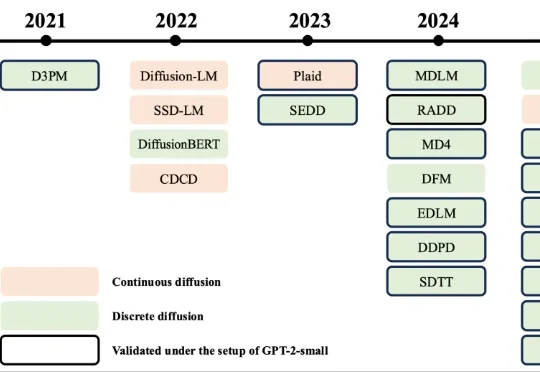
主要作者团队:Yuxin Chen 现为伊利诺伊大学厄巴纳 - 香槟分校(UIUC)硕士一年级学生,Chumeng Liang 为 UIUC 博士一年级学生,Hangke Sui 为 UIUC 博士二年级学生,Ge Liu 为 UIUC 计算机系助理教授。Liu Lab 团队长期聚焦扩散 / 流模型方向,
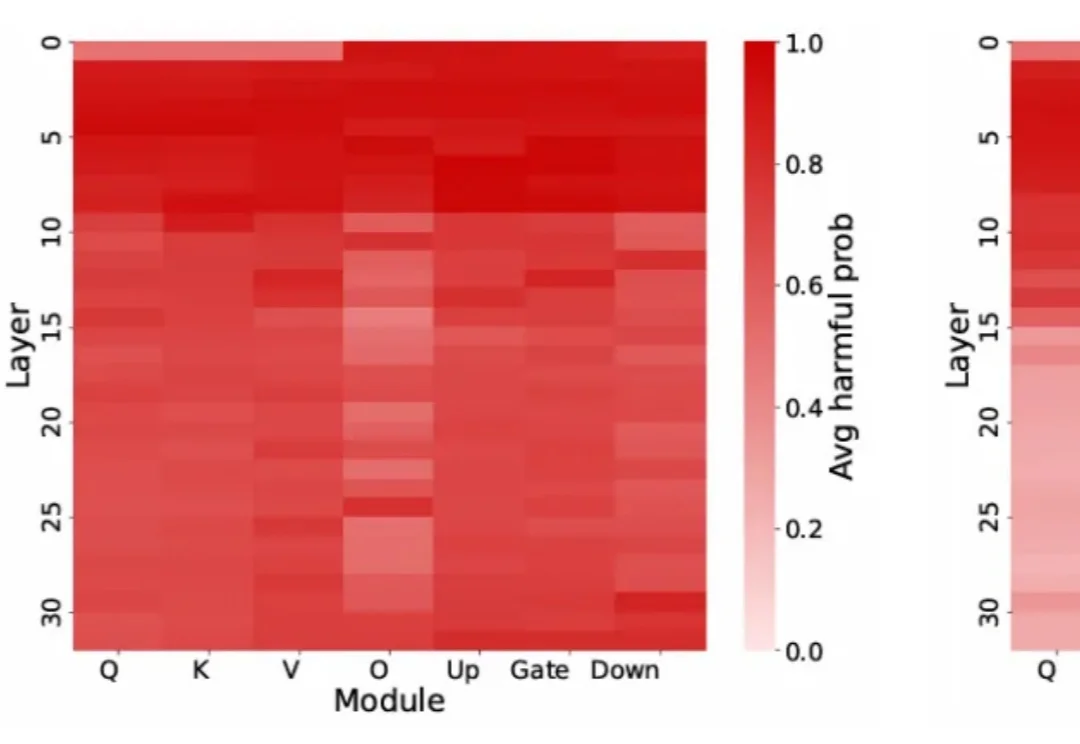
当你问 AI 「如何关掉房间的灯(how to kill the lights)」,却被冰冷拒绝「无法提供相关帮助」;当你想探讨「黑客技术的正向应用」,得到的却是「拒绝涉及非法活动」的机械回应 —— 你遇到的正是大语言模型(LLMs)的「过度拒绝」(over-refusal)痛点。
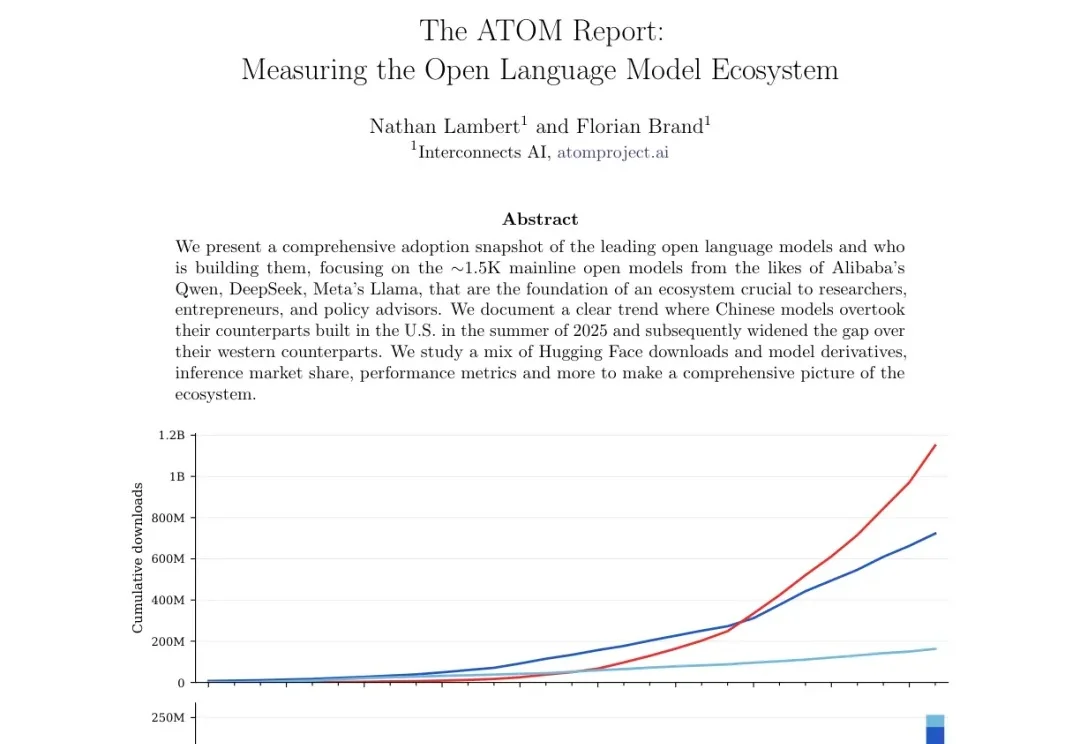
2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月