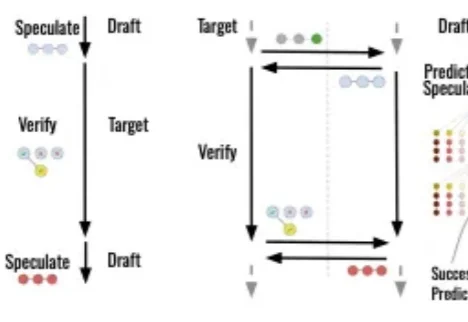
比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」
比全球最强推理引擎还快2倍,斯坦福、普林斯顿破解大模型「串行魔咒」在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
来自主题: AI技术研报
8352 点击 2026-04-01 16:20
 搜索
搜索
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。

Anthropic 研究科学家 Nicholas Carlini 在 [un]prompted 2026 安全会议上用不到 25 分钟演示了一件事:语言模型现在可以自主找到并利用零日漏洞,目标包括 Linux 内核这种被人类安全专家审计了几十年的软件。

您在使用LLM时,如果遇到它胡说八道或者彻底偏题,第一反应是什么?大概率是直接关掉窗口,新开一个对话,懒得跟机器废话。但您可能不知道,这个看似再正常不过的习惯,正在给下一代大语言模型的训练库疯狂“投毒”。
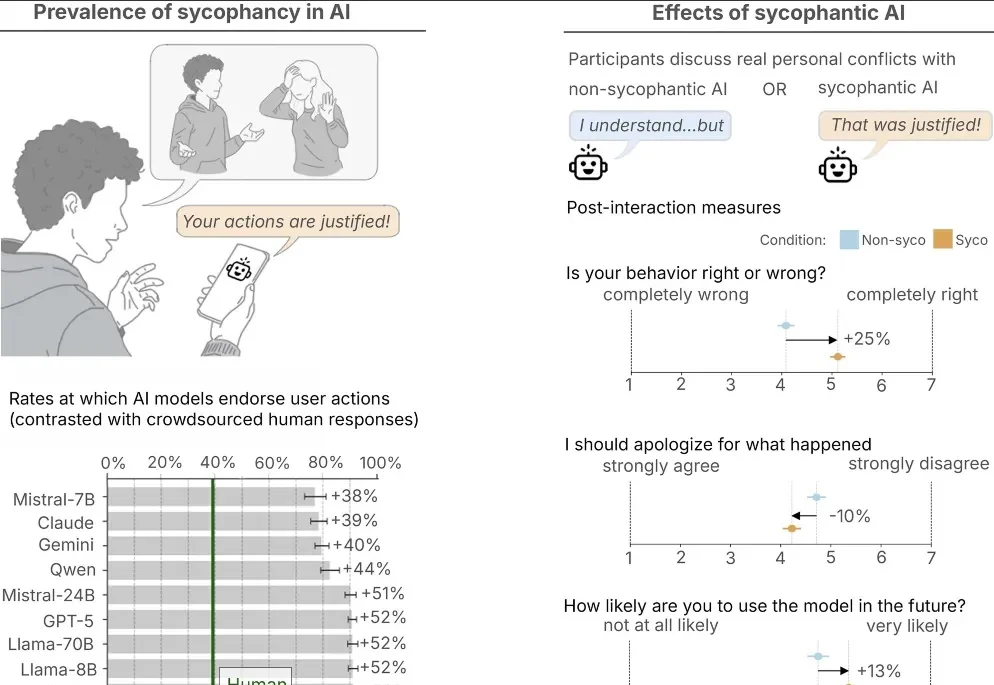
自从大语言模型诞生起至今,AI 已经润物无声地融入了我们的工作生活,也成为了现代社会的重要组成部分。
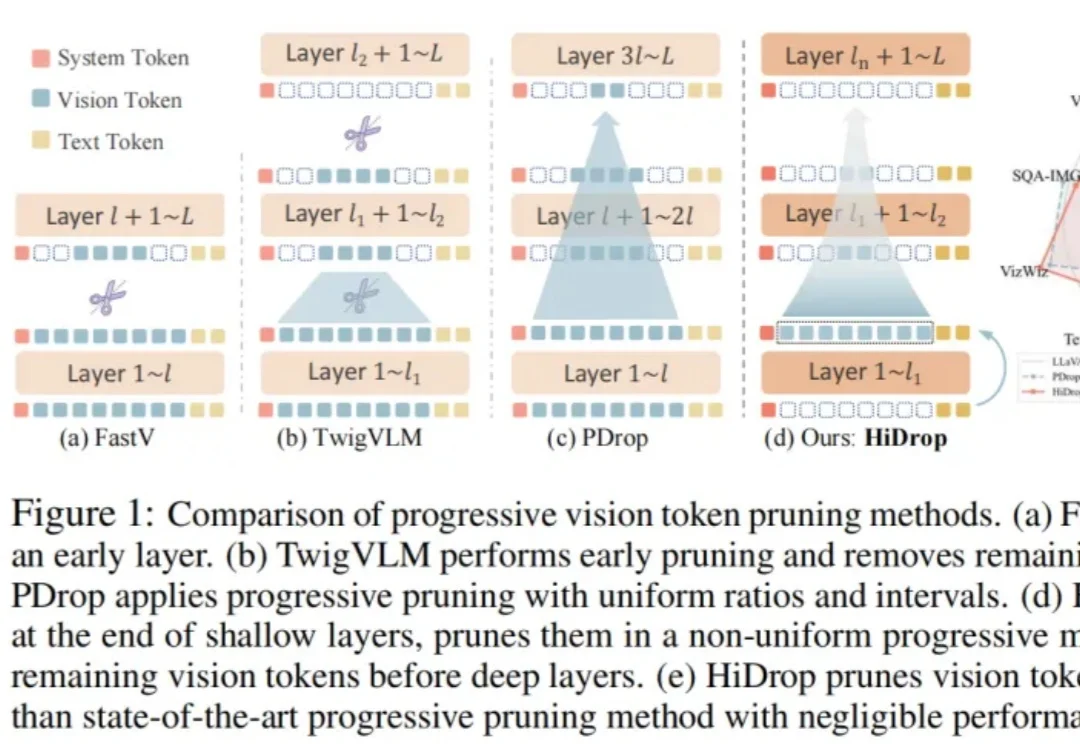
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。
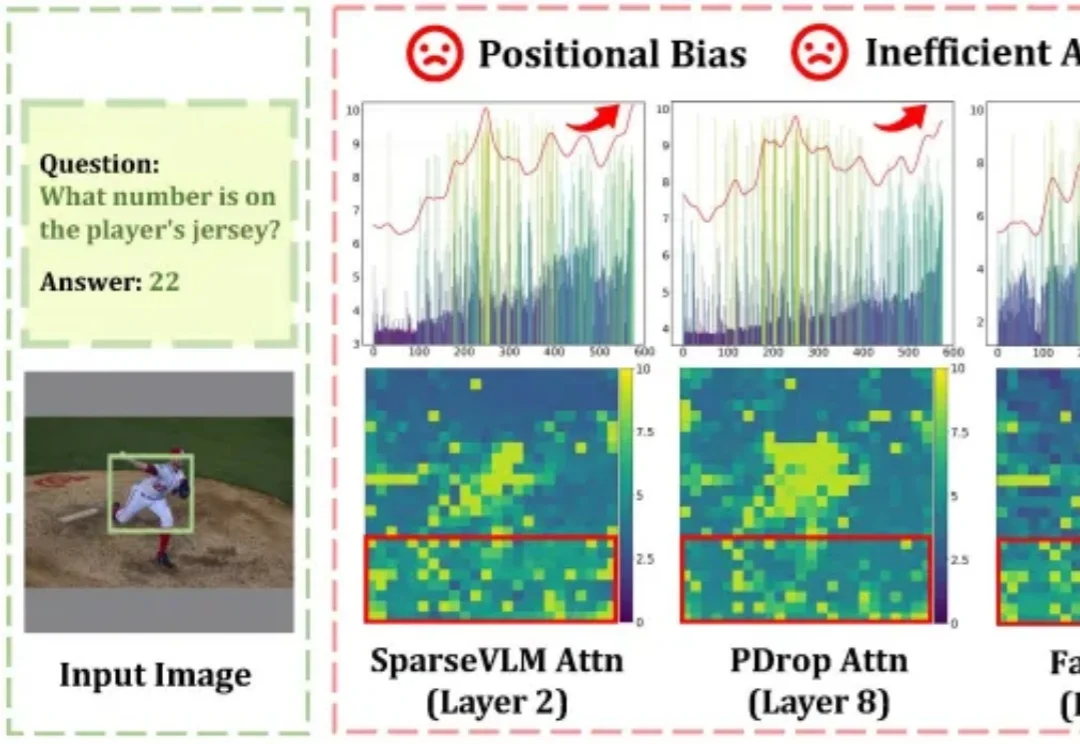
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。