
UIUC清华微软联合提出PlugMem:当Agent记忆告别「经历」,开始存储「经验」
UIUC清华微软联合提出PlugMem:当Agent记忆告别「经历」,开始存储「经验」随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。
来自主题: AI技术研报
10646 点击 2026-03-12 09:53
 搜索
搜索
随着大语言模型 Agent 开始在对话、问答与复杂交互环境中长期运行,“记忆该如何设计” 正在成为一个绕不开的核心问题。

当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。

昨日,OpenAI 宣布收购了 Promptfoo 以保障其 AI 智能体的安全。这家成立于 2024 年的 AI 安全初创公司,专注于保护大语言模型免受网络攻击。OpenAI 在一篇博客文章中表示,交易完成后,Promptfoo 的技术将整合进 OpenAI Frontier,该平台是其近期推出的、供企业构建和管理 AI 智能体的平台。
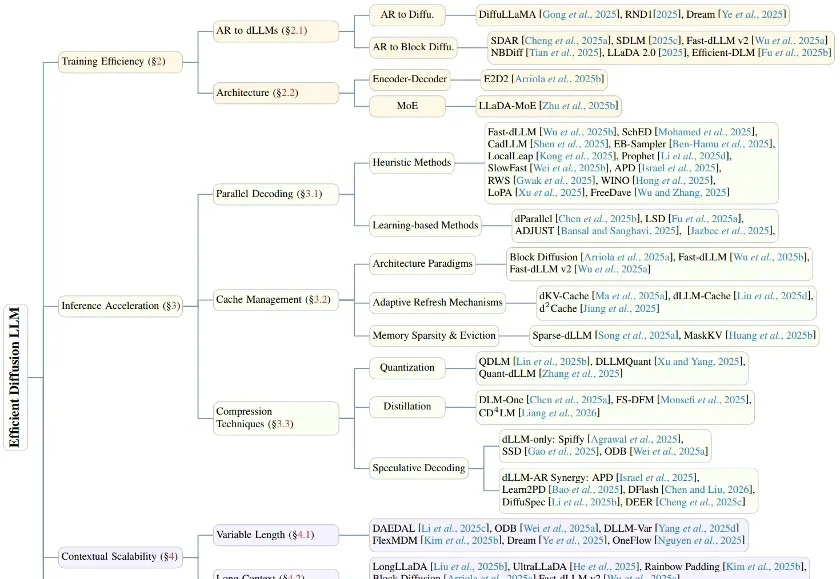
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
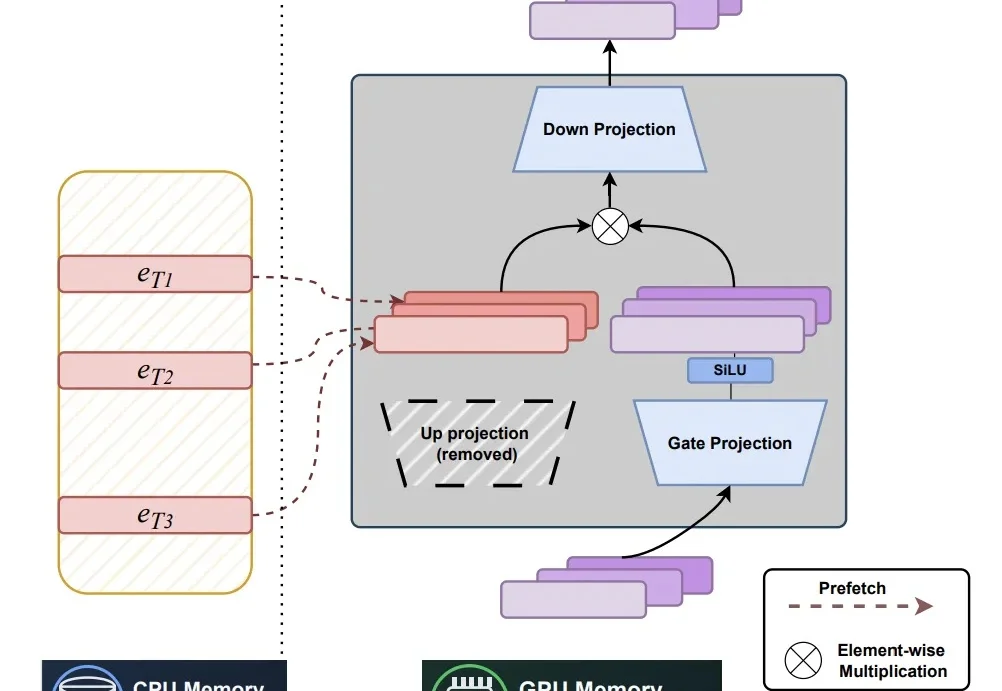
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
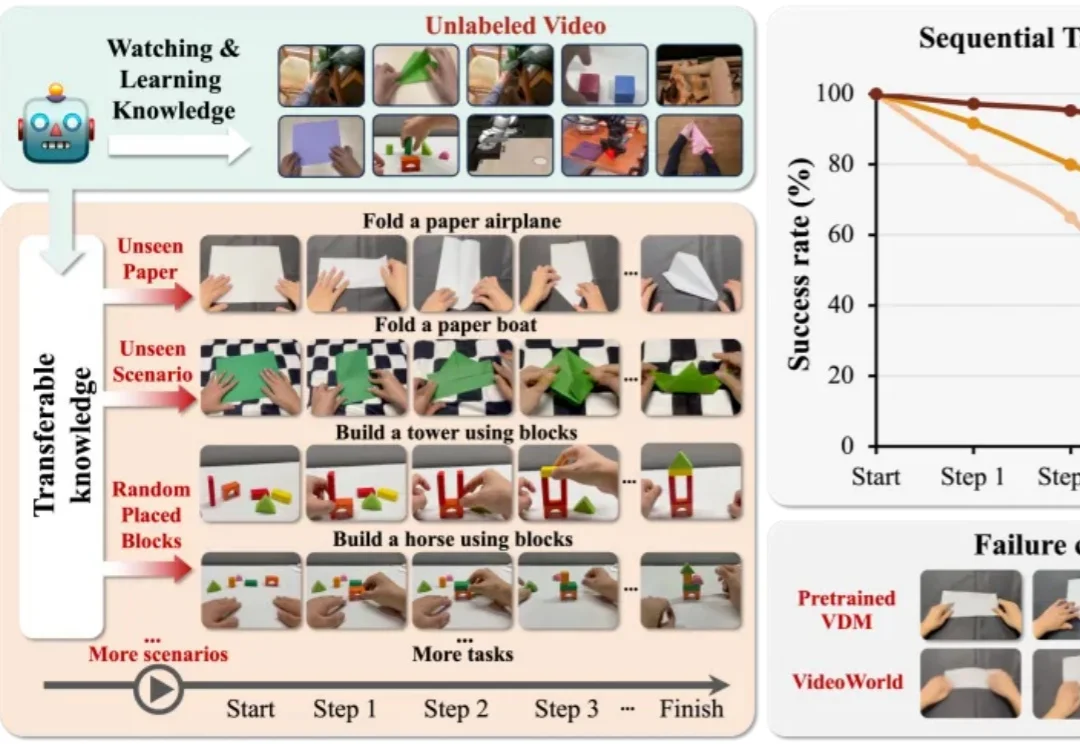
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
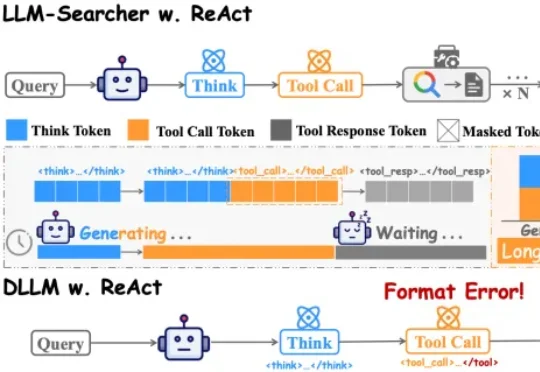
中国人民大学团队在论文DLLM-Searcher中,第一次让扩散大语言模型(dLLM)学会了这种“一心二用”的本事。目前主流的搜索Agent,不管是Search-R1还是R1Searcher,用的都是ReAct框架。这个框架的执行流程是严格串行的:
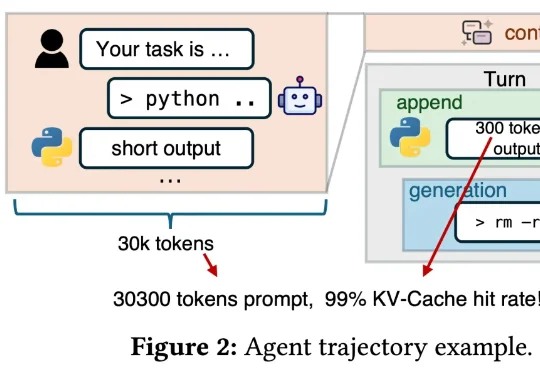
「DeepSeek V4 来了!」这样的消息是不是已经听烦了?总结来说,这篇新论文介绍了一个名为「DualPath」的创新推理系统,专门针对智能体工作负载下的大语言模型(LLM)推理性能进行优化。具体来讲,通过引入「双路径 KV-Cache 加载」机制,解决了在预填充 - 解码(PD)分离架构下,KV-Cache 读取负载不平衡的问题。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。

没有让我们等待多久,阿里刚刚正式发布并开源了 Qwen3.5 系列模型,页面显示有两款模型,分别为最新大语言模型的 Qwen3.5-Plus,以及定位为开源系列旗舰的 Qwen3.5-397B-A17B。两者均支持文本处理与多模态任务。