



没有AI,大学生已经不会写论文了吗?
没有AI,大学生已经不会写论文了吗?上周三,正值许多高校期末考期间,ChatGPT突然崩溃。
来自主题:
AI资讯
7561 点击 2024-12-21 11:50
上周三,正值许多高校期末考期间,ChatGPT突然崩溃。

在社交平台分享“显眼包”的帖子中,频繁出现“出吗”、“高价收”类似的评论。“显眼包”是字节此前给客户送出去的玩具,区别传统玩具,这是一款内嵌了豆包大模型、扣子专业版、语音识别、语音合成等技术的AI玩具。
最近AI业界的观点开始产生变化,Jason Wei明确指出AI for Science蕴藏着巨大的机遇,而其中最大的场景在于AlphaFold 2掀起的蛋白质革命。

联想第六代“海神”液冷技术,已实现支持多类型GPU、CPU,散热效率可达98%,PUE最佳可降至1.1,极大降低了数据中心的能耗水平。

Tokyo Electron面向中国的营收比率在2024年4~6月的峰值时曾达到5成。由于中国经济放缓,和中国制造商的提前投资等告一段落,2025财年这一比率可能降至3成左右。该公司希望将AI营收比率提高至4成,来抵消中国影响……

北京大学等研究团队优化了Sdcpp框架,通过引入Winograd算法和多项策略,显著提升了图像生成速度和内存效率,最高可提速4.79倍。

OpenAI o1的数学推理能力是否真的那么强?近日,来自港大的研究人员对模型进行了严格的AB测试,在非公开的国家队奥数题面前,o1证明了自己的实力。
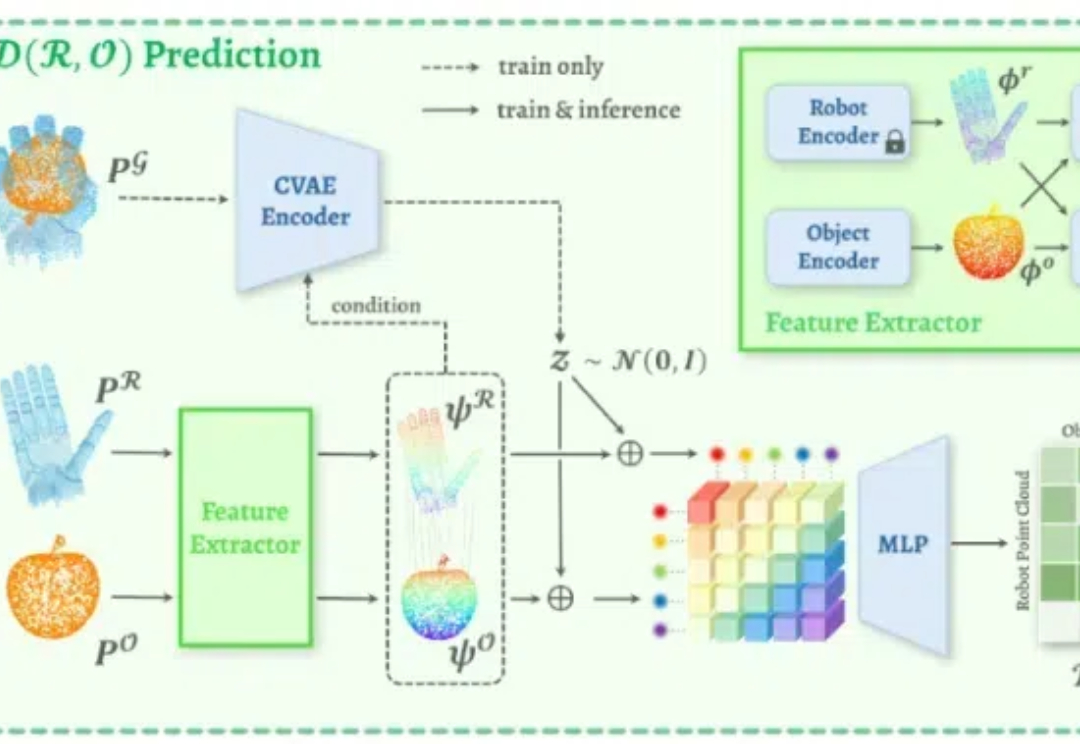
近期,新加坡国立大学计算机学院的邵林团队提出了 D(R,O) Grasp:一种面向跨智能体灵巧抓取的机器人与物体交互统一表示。该方法通过创新性地建模机器人手与物体在抓取姿态下的交互关系,成功实现了对多种机器人手型与物体几何形状的高度泛化能力,为灵巧抓取技术的未来开辟了全新的方向。
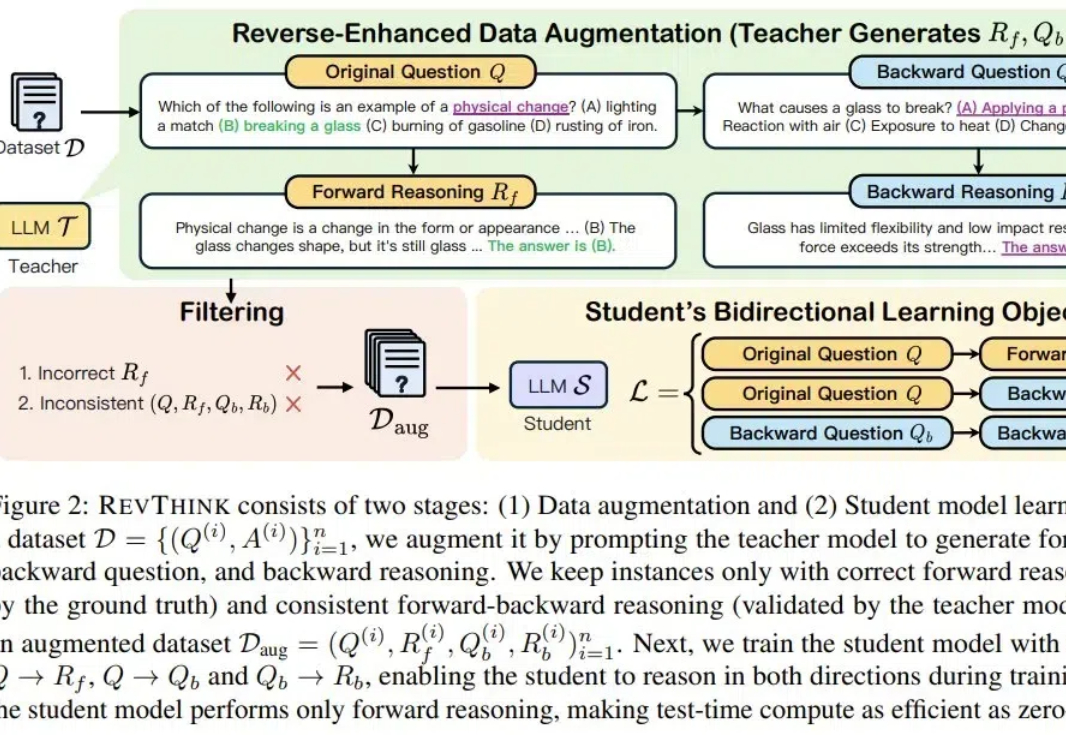
人能逆向思维,LLM 也可以吗?北卡罗来纳大学教堂山分校与谷歌最近的一项研究表明,LLM 确实可以,并且逆向思维还能帮助提升 LLM 的正向推理能力!
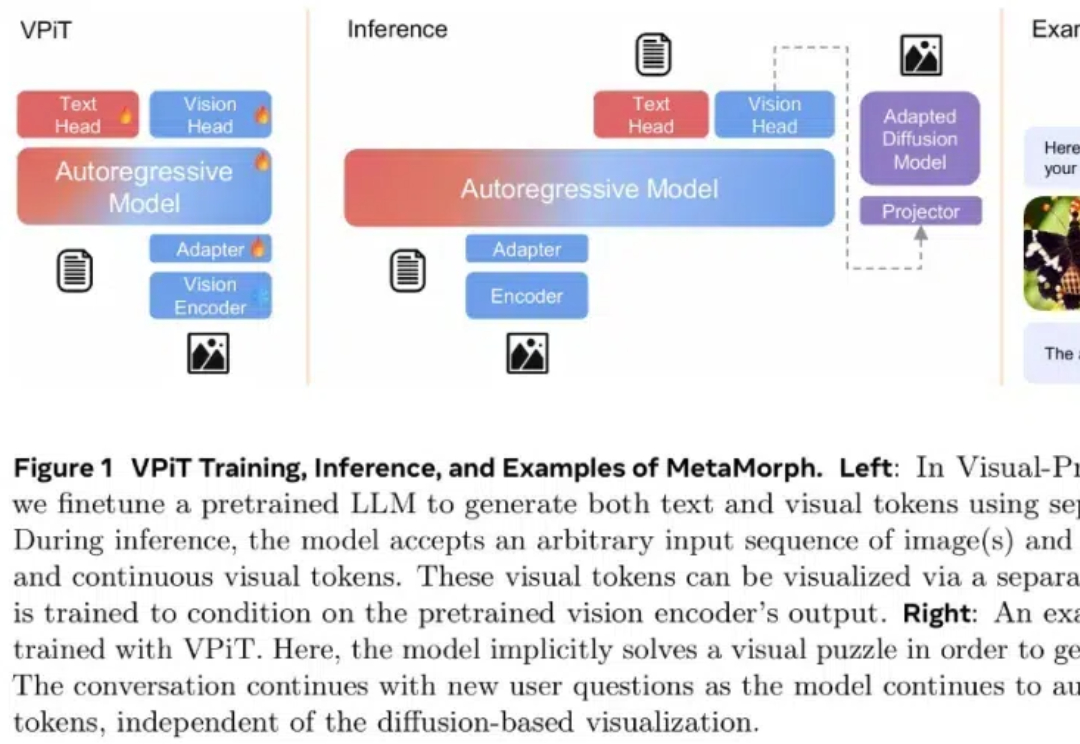
如今,多模态大模型(MLLM)已经在视觉理解领域取得了长足进步,其中视觉指令调整方法已被广泛应用。该方法是具有数据和计算效率方面的优势,其有效性表明大语言模型(LLM)拥有了大量固有的视觉知识,使得它们能够在指令调整过程中有效地学习和发展视觉理解。

AI 时代,大模型正在激发更多企业品牌塑造、内容生产的新解法。
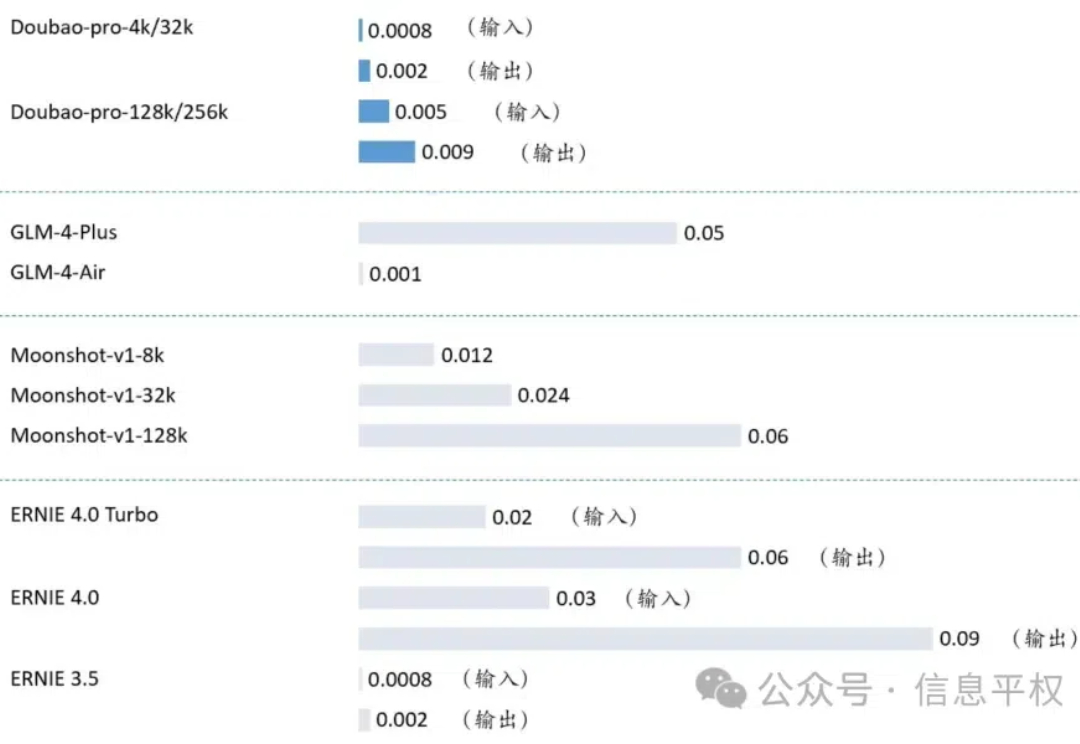
字节前几天的发布会,上线了一堆新的模型:视觉理解、3D 生成,以及全线降价

宣布转型AIGC的图森未来正式宣布启用全新品牌CreateAI,并公布多个业务进展

大语言模型(LLM)在自然语言处理领域取得了令人瞩目的成就,但在需要多步推理的复杂任务中仍面临严峻挑战。

12 月 19 日周四晚,有新Newin 参加了国内先锋智能硬件品牌闪极科技的发布会,创始人& CEO 张波宣布了公司首款 AI 眼镜 —— 闪极 A1「拍拍镜」,999 元共创版价格也意味着百镜大战提前进入千元以下市场的竞争。
OpenAI下一代模型——o3,重磅诞生了!陶哲轩预言难住AI好几年的数学测试,它瞬间破解,编程水平位于全球前200,在ARC-AGI基准中更是惊人,打破所有AI纪录接近人类水平,离AGI更近一步。
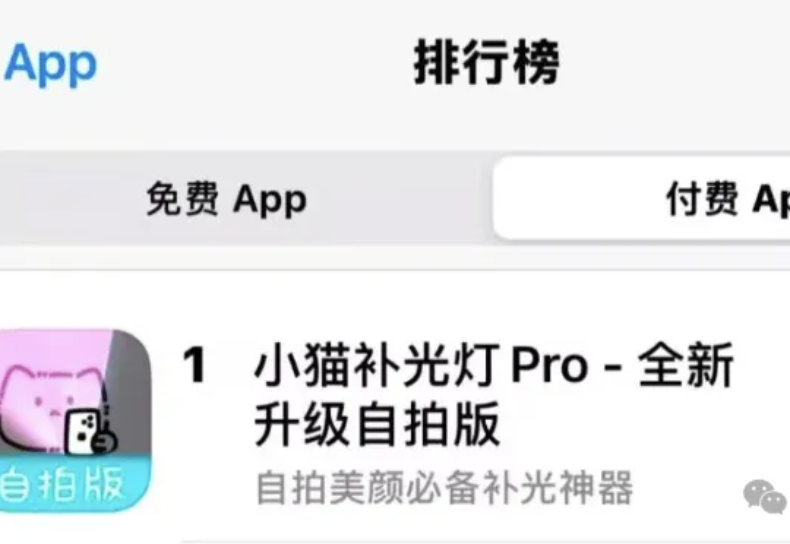
“十多年前有本书叫《人人都是产品经理》,但现在可能才真正到了「人人都是产品经理」的时刻。” 苹果商店付费榜Top1,这是一个不会代码的独立开发者用Cursor开发App的最佳战绩。

今年,生成式 AI 的炒作消息层出不穷,显然应用开发人员也一直在关注这波潮流。以 AI 为卖点的工具几乎在苹果的 App Store 排行榜上占据了每个类别的榜首,包揽了教育、生产力和照片编辑领域的前 10 名。免费图形和设计应用类别中的机遇尤其多,这个类别中充斥着 AI 内容创建工具。

近段时间,世界模型的相关研究成果正如雨后春笋版不断涌现,光是我们报道过的就已有南大周志华团队的世界模型 Whale、Yann LeCun 团队的世界模型研究、李飞飞 World Labs 的空间智能研究、谷歌的强大世界模型 Genie 2 以及刚刚开源的像是能模拟万物的生成式物理引擎 Genesis。

不仅能推理,还能明确展示自己「推理逻辑」的大模型出现了。 OpenAI 的 12 天连续发布已近尾声,但它的热度显然已经被谷歌夺去了许多。从 Gemini 2.0 Flash 到 Veo 2 到今天的 Gemini 2.0 Flash Thinking,谷歌端上来的菜真是一道比一道香。
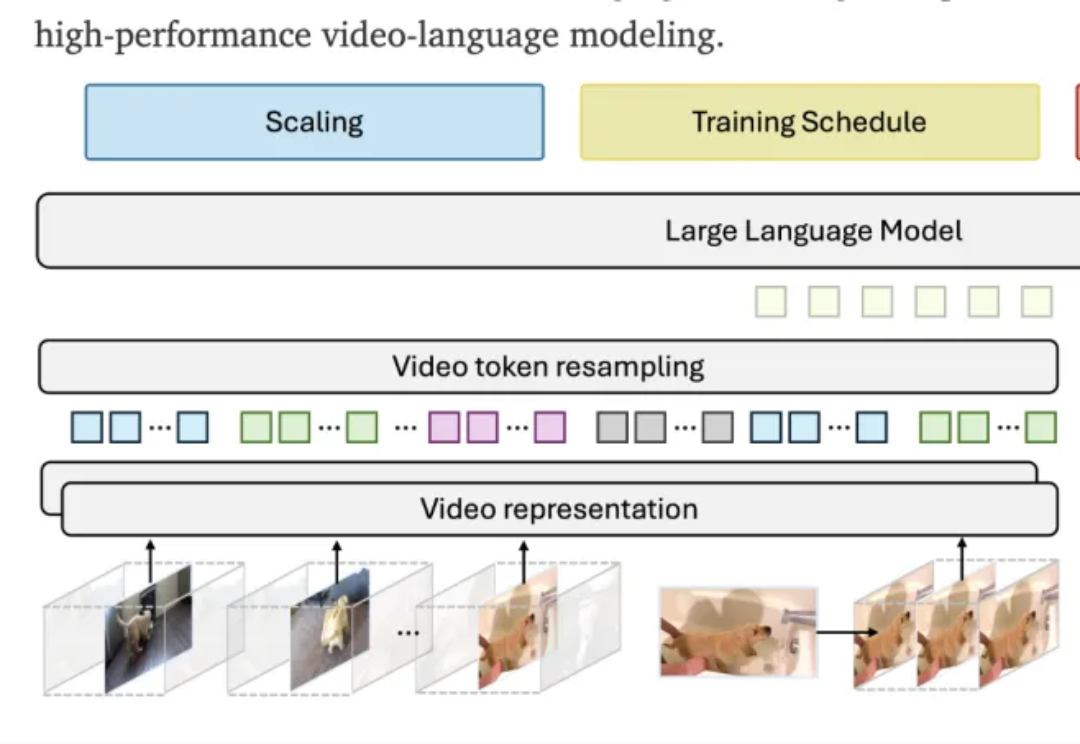
Meta斯坦福大学联合团队全面研究多模态大模型(LMM)中驱动视频理解的机制,扩展了视频多模态大模型的设计空间,提出新的训练调度和数据混合方法,并通过语言先验或单帧输入解决了已有的评价基准中的低效问题。

英伟达2025年博士奖学金名单揭晓了!今年,共有10位天才学者入选,华人比例占七成,其中不乏有中科大、浙大、上交、上科大、东南大学优秀校友。值得一提的是,5名入围学者全是华人学生。
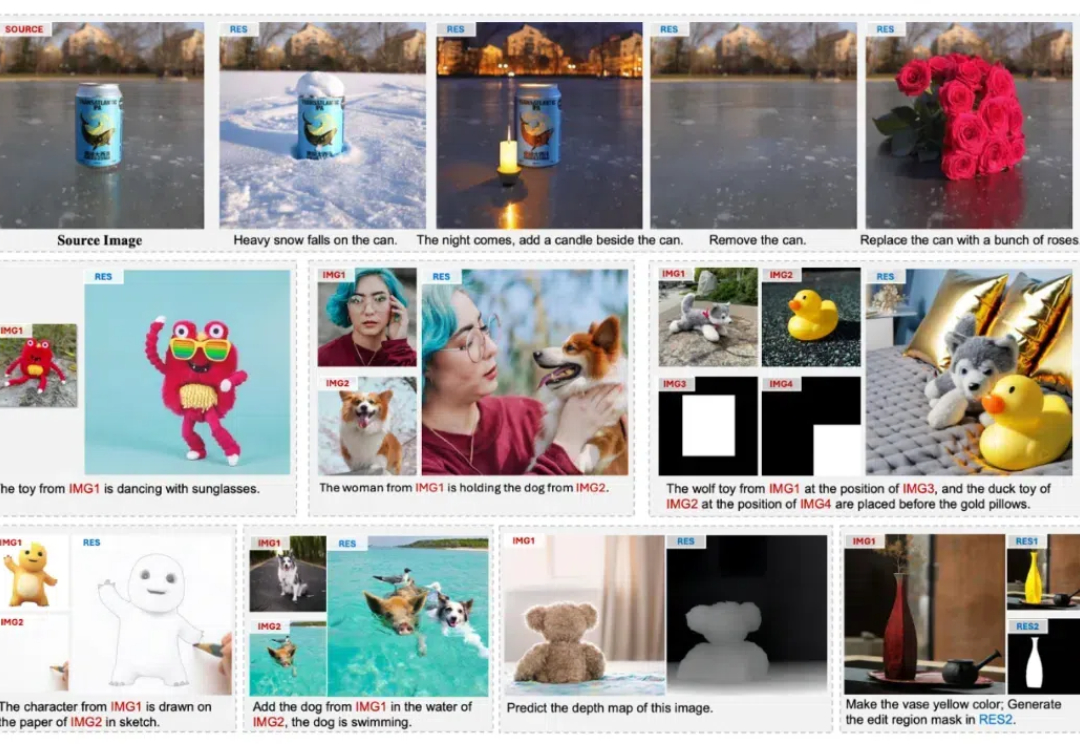
本文中,香港大学与 Adobe 联合提出名为 UniReal 的全新图像编辑与生成范式。该方法将多种图像任务统一到视频生成框架中,通过将不同类别和数量的输入/输出图像建模为视频帧,从大规模真实视频数据中学习属性、姿态、光照等多种变化规律,从而实现高保真的生成效果。

AutoPatent框架能够自动化生成高质量的专利文档,大幅提高专利撰写效率,有望简化专利申请流程,降低成本,促进创新保护。
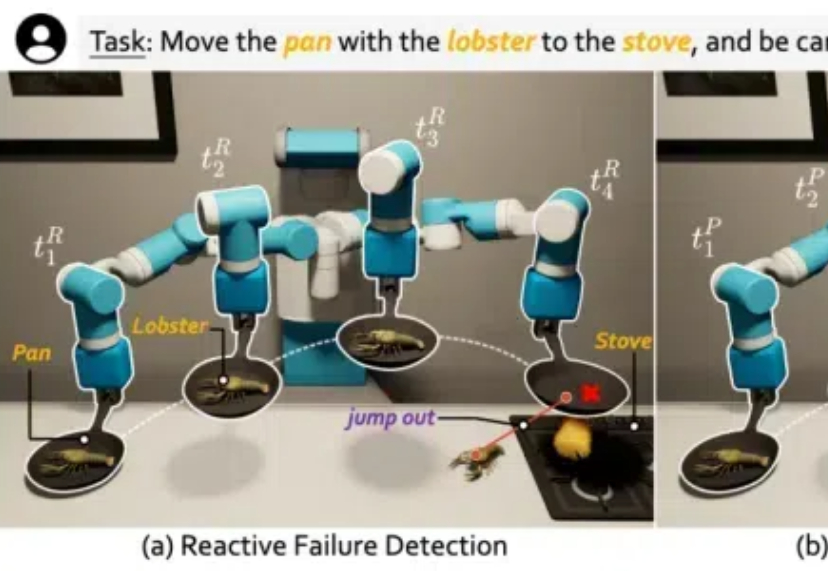
将图像中与约束相关的物体或部分提取为更简洁的几何元素(如点、线、面)。通过跟踪和评估这些几何元素在时空中的变化,可以有效地监控约束是否被满足。
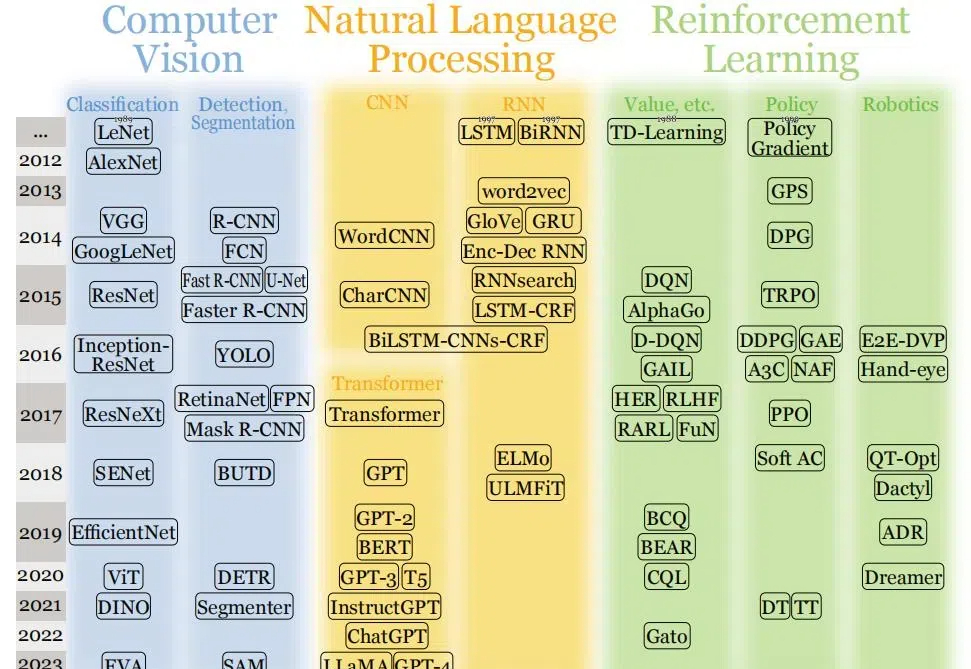
2024年,智驾领域最热的词,就是“端到端”。甚至,到了不聊端到端都没法出门的程度。

自动驾驶行业正经历新一轮洗牌。其中,全球自动驾驶第一股图森未来的沉浮,折射出整个行业的阵痛:从 2021 年 IPO 时 85 亿美元的估值,到 2024 年初退市,短短三年间历经管理层动荡、美国监管调查、业务收缩及大幅裁员等一系列剧变。

2024年快要结束了,世界大模型究竟孰强孰弱?刚刚,智源研究院发布了下半年大模型综合评测结果,涵盖了开源闭源100+模型,横跨文本、语音、图像和视频等多个领域。
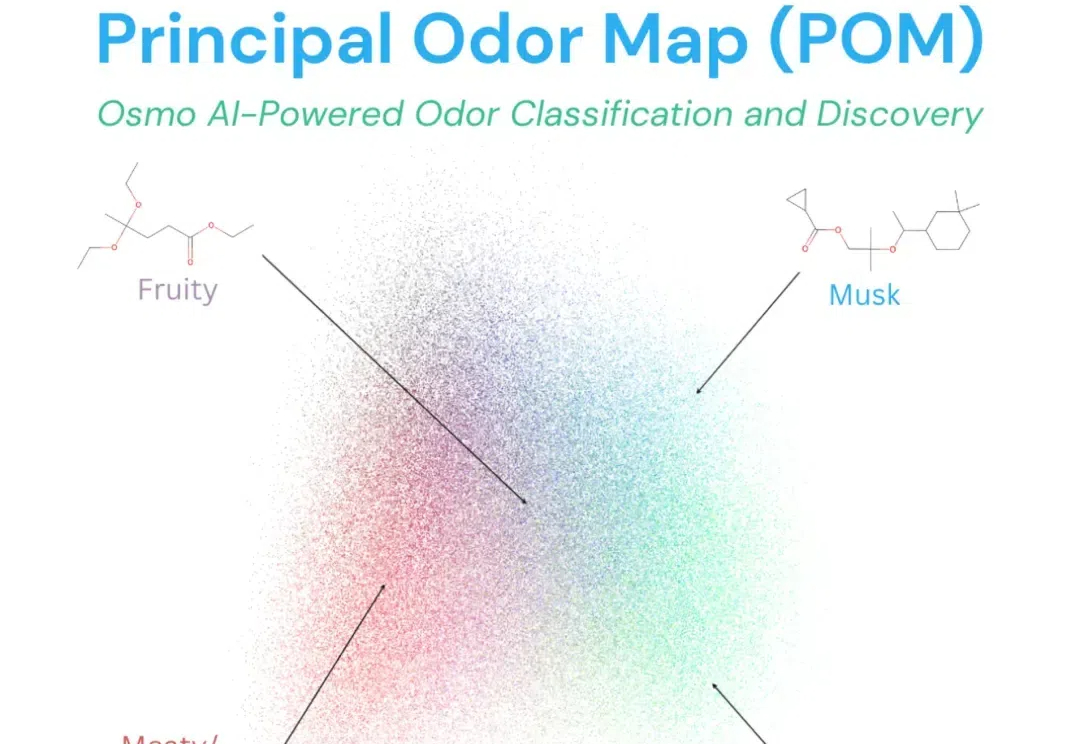
继视觉和听觉之后,AI已经进化到拥有嗅觉了?? 你没听错,这是来自Osmo公司的最新技术,它们刚刚首次实现了由AI生成的李子味道。 而且生成味道的过程几乎是全自动的——除了放入水果和取出生成结果,全程都不需要人工干预。

AI重构一切,已经实实在在开始在直播间里分一杯羹了。

