


企服赛道下一次爆发,离不开与AIGC碰撞的火花
企服赛道下一次爆发,离不开与AIGC碰撞的火花借助AIGC,为客户带来十倍价值。
来自主题:
AI资讯
10630 点击 2024-06-04 10:12
 搜索
搜索
借助AIGC,为客户带来十倍价值。
“一键完成”工作的AI应用近在眼前

AI时代一个海淀家长的鸡娃思考。

大模型抄袭丑闻总是不断。

一般而言,训练神经网络耗费的计算量越大,其性能就越好。在扩大计算规模时,必须要做个决定:是增多模型参数量还是提升数据集大小 —— 必须在固定的计算预算下权衡此两项因素。

如何突破 Transformer 的 Attention 机制?中国科学院大学与鹏城国家实验室提出基于热传导的视觉表征模型 vHeat。将图片特征块视为热源,并通过预测热传导率、以物理学热传导原理提取图像特征。相比于基于Attention机制的视觉模型, vHeat 同时兼顾了:计算复杂度(1.5次方)、全局感受野、物理可解释性。

黄仁勋:我家的 GPU 芯片一年一更新,其他家怎么追?
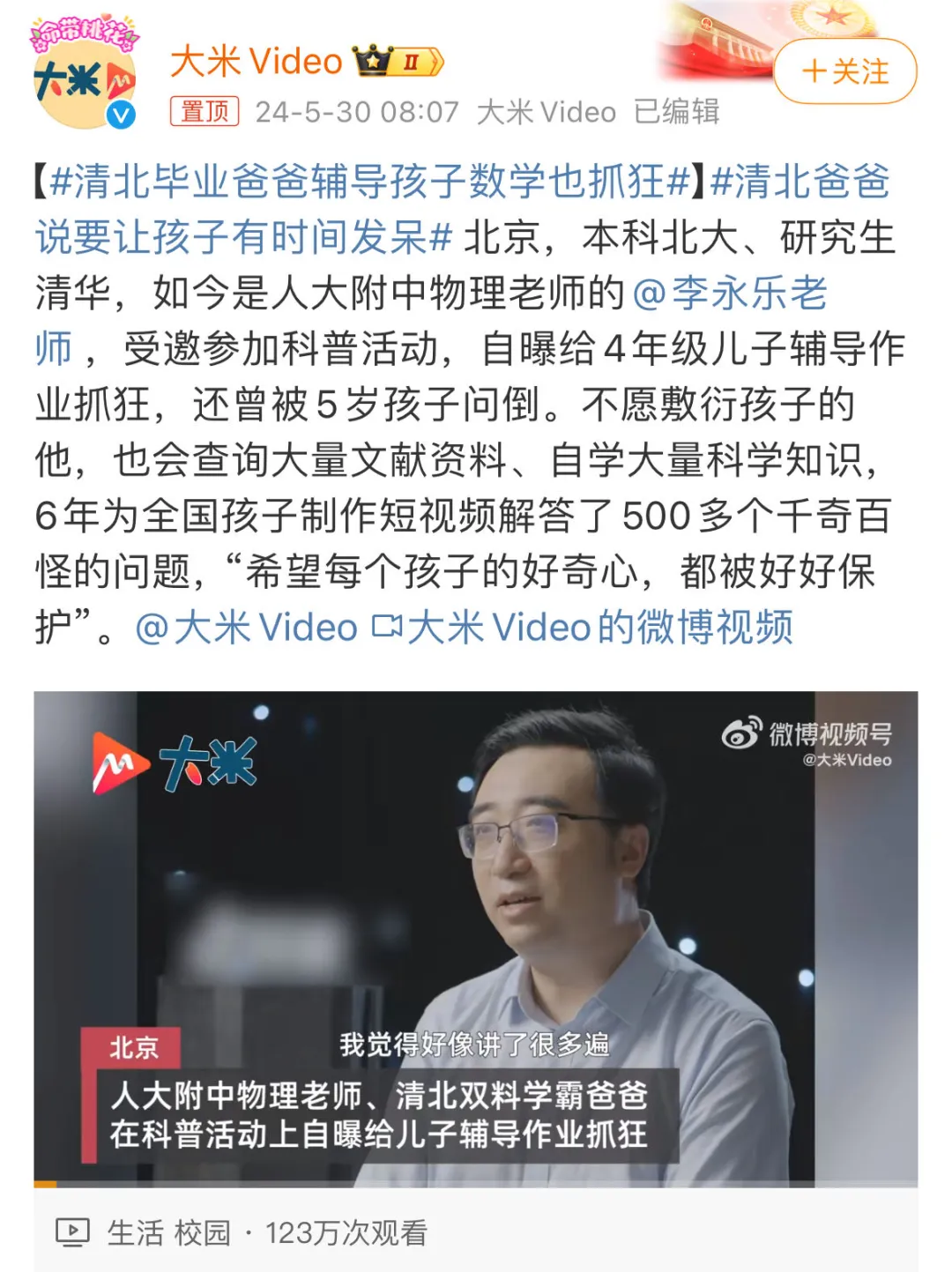
清北爸爸李永乐都搞不定的事情,这个隐身的大模型在发起挑战

都在说大模型,都不会用大模型。

无论从合作级别还是金额来说,这一交易都是AI行业发展的里程碑事件。

Scaling law发展到最后,可能每个人都站在一个数据孤岛上。

媒体与科技平台所谓的第三次大战里,OpenAI几乎已经不战而胜。

英伟达是今天生成式AI浪潮里最大的赢家,而黄仁勋要告诉世界,这一切跟运气无关,是英伟达预见并用实力创造了今天的一切。

除了OpenAI自己,居然还有别人能用上GPT-4-Base版??
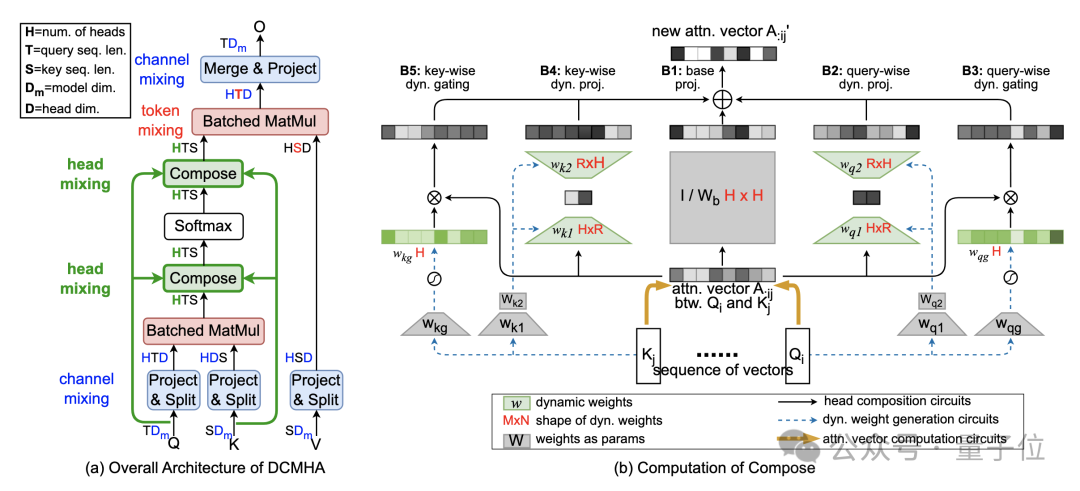
改进Transformer核心机制注意力,让小模型能打两倍大的模型!
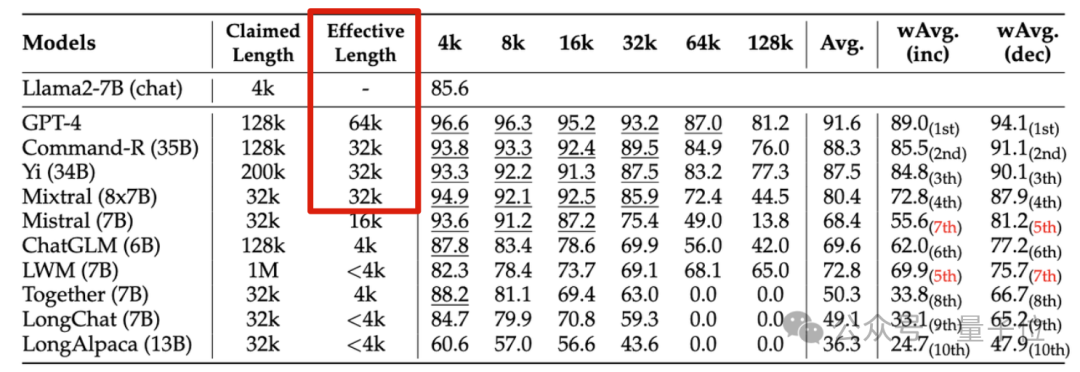
无情戳穿“长上下文”大模型的虚标现象
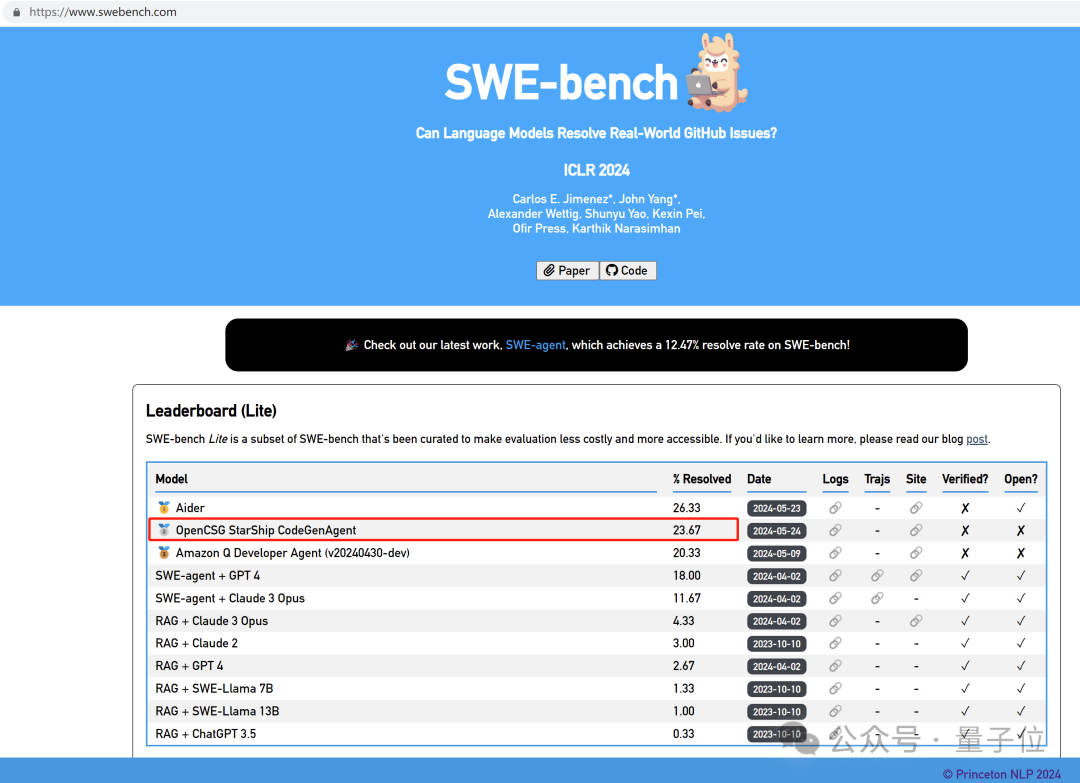
超越Devin!SWEBench排行榜上迎来了新玩家
我是万万没想到,现在的AI内容生态,居然也活成了一种“赛博投喂”的无限循环。

工业革命就注定会有钢铁、石油、铁路巨头。互联网也注定会有搜索、电商、即时通讯。历史性变革催生历史性机会,而这种历史性机会往往内置技术的特征。技术特征决定了机会是什么,甚至也决定了机会的先后。

多模态,已经成为大模型最重要的发展方向之一。

首个“脑PU”来了!由“16核”类人脑器官(human brain organoids)组成。

刚刚,中国台湾大学体育场,欢呼阵阵如同演唱会,但这次“摇滚巨星”,其实是英伟达创始人黄仁勋,再次回到学校,带来Computex重磅演讲,以及英伟达的新一代GPU。

研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。

在脑机接口领域取得突破性进展的公司不止Neuralink一家。Precision Neuroscience发布公告称,他们采用与Neuralink不同的技术路径,在人脑上成功放置了4096个电极,打破了去年2048个电极的最高纪录。

在以英语为主的语料库上训练的多语言LLM,是否使用英语作为内部语言?对此,来自EPFL的研究人员针对Llama 2家族进行了一系列实验。

刚刚,老黄又高调向全世界秀了一把:已经量产的Blackwell,8年内将把1.8万亿参数GPT-4的训练能耗狂砍到1/350;英伟达惊人的产品迭代,直接原地冲破摩尔定律;Blackwell的后三代路线图,也一口气被放出。

不卖模型卖算力

为了让更多用户先人一步体验AI,京东联合产业上下游企业乘胜追击,定下了618期间让300万人换新AI硬件的“小目标”。

英伟达创始人黄仁勋把HBM(高带宽存储器)称为“技术奇迹”,认为它是AI革命的重要因素。在这一领域SK海力士处于优势,占有全球过半份额。这种状况让三星无法接受……

生成式AI时代,Arm要做计算“基石”。

