


斯坦福新研究:RAG能帮助LLM更靠谱吗?
斯坦福新研究:RAG能帮助LLM更靠谱吗?斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。
来自主题:
AI技术研报
7561 点击 2024-05-29 15:49
 搜索
搜索
斯坦福大学的研究人员研究了RAG系统与无RAG的LLM (如GPT-4)相比在回答问题方面的可靠性。研究表明,RAG系统的事实准确性取决于人工智能模型预先训练的知识强度和参考信息的正确性。

就在刚刚,一份2500页的内部文档泄露,谷歌搜索算法的内幕,让不少人大跌眼镜。

出走OpenAI的超级对齐团队负责人Jan Leike,刚刚官宣了自己加入Anthropic的消息,并且开始高调招兵买马。同时,外界也开始对Ilya的去向纷纷猜测:是去Anthropic,xAI,还是自立门户?

解散Ilya的超级对齐团队之后,奥特曼再造了一个新的「安全委员会」。OpenAI称正训练离AGI更近一步的下一代前沿模型,不过在这90天评估期间,怕是看不到新模型发布了。
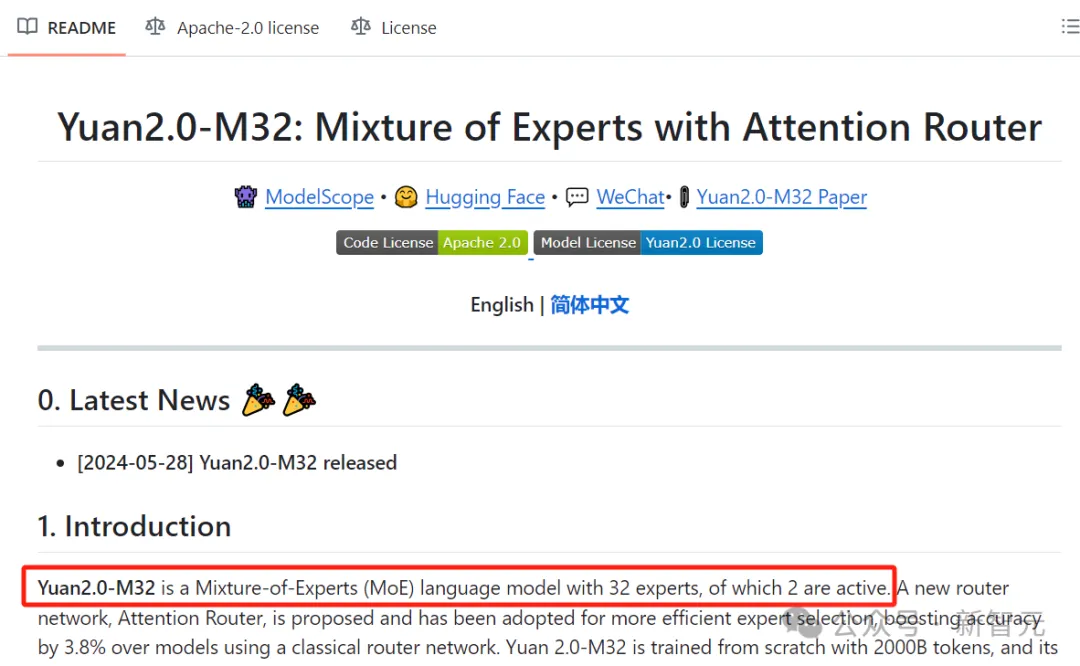
马斯克最近哭穷表示,xAI需要部署10万个H100才能训出Grok 3,影响全球的大模型算力荒怎么解?昨天开源的这款MoE大模型,只用了1/19算力、1/19激活参数,性能就直接全面对标Llama 3-70B!

新的可能性和新的难点。 大模型天天有热点。最近,字节、阿里、百度、腾讯、科大讯飞等大模型厂商纷纷宣布调整旗下大模型产品的定价策略,大模型“价格战”正式打响。

“我们对今年有更好的预期。”2024年5月,成都明途科技有限公司(以下简称“明途科技”)的“明途WorkGPT”大模型通过《生成式人工智能服务管理暂行办法》备案审批。「明途科技」创始人、董事长兼总经理肖雪松表示:“此次通过生成式人工智能服务备案,进一步肯定了明途科技在人工智能技术领域的投入与创新成果,明途也将正式展开关于明途WorkGPT的宣发、运营。”

彭博社报道,Apple 已与 OpenAI 达成协议,将由 OpenAI 为 iOS 18 提供 AI 聊天功能,此外,Apple 也在积极与 Google 进行协商,希望将 Gemini 作为另一项选择。Apple 与 OpenAI 的这一合作将在全球开发者大会(WWDC)上公布。

走慢了怕赶不及,走快了怕拉伤。
这一把火,似乎烧得有点太猛烈。

两个星期前,Google 在今年的 I/O 大会中高调介绍了自家的 AI 搜索功能 AI Overview,并在当周宣布对美国用户开放。我们尚且没能等来预热了好久的 ChatGPT Search,全球市占率超过 9 成的搜索引擎巨头 Google 却无预警地在美国开放了 AI 搜索,一副“为了提升用户体验舍我其谁”的架势。

创意为王的营销领域被AI爆改到什么程度了?

印度的AI狂想与尴尬

你真的了解你的AI助手吗? 想象一下,你和同事使用相同的AI工具,但为何他的工作效率总是高出一截?秘诀可能就藏在那些看似简单的提示词里。精准的提示词是解锁AI潜能的关键,它们能让AI更好地理解你的需求,从而提供更准确、更高效的回答。
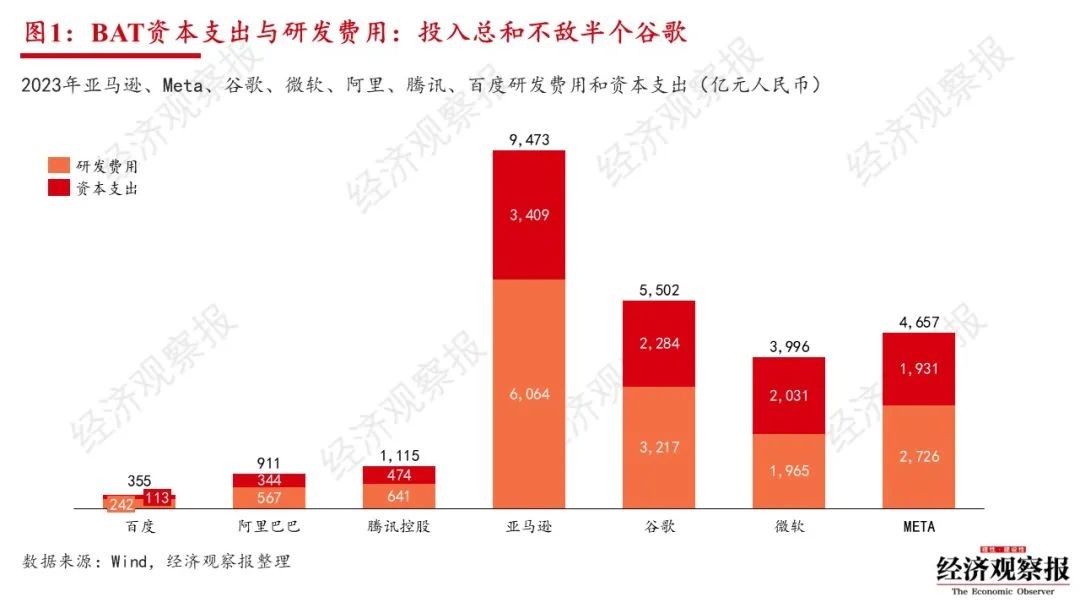
2023年,亚马逊、Meta、谷歌、微软四家公司整体投入体量更大、增速飞快,而腾讯、阿里巴巴、百度没有明显加大投入、追赶超越的动作,这一定程度说明未来在AI竞争上的差距还将扩大。

大模型每次一有突破,我们就会听到它又“摧毁了XX职业”“XX岗位要消失了”,也总能听到一些安慰,说不用担心,“AI会创造一些新职业”。

SafeBase完成B轮融资,总资超5000万美元。

北大-兔展联合发起的Sora开源复现计划Open-Sora-Plan,今起可以生成最长约21秒的视频了!

多模态大模型,也有自己的CoT思维链了! 厦门大学&腾讯优图团队提出一种名为“领唱员(Cantor)”的决策感知多模态思维链架构,无需额外训练,性能大幅提升。

3D生成也有自个儿的人工评测竞技场了~ 来自复旦大学和上海AI lab的研究人员搞了个3DGen-Arena,和大语言模型的Chatbot-Arena、GenAI-Arena等一脉相承,要让大伙儿对3D生成模型来一场公开、匿名的评测

AGI发展观点多元,技术风险需警惕管理。
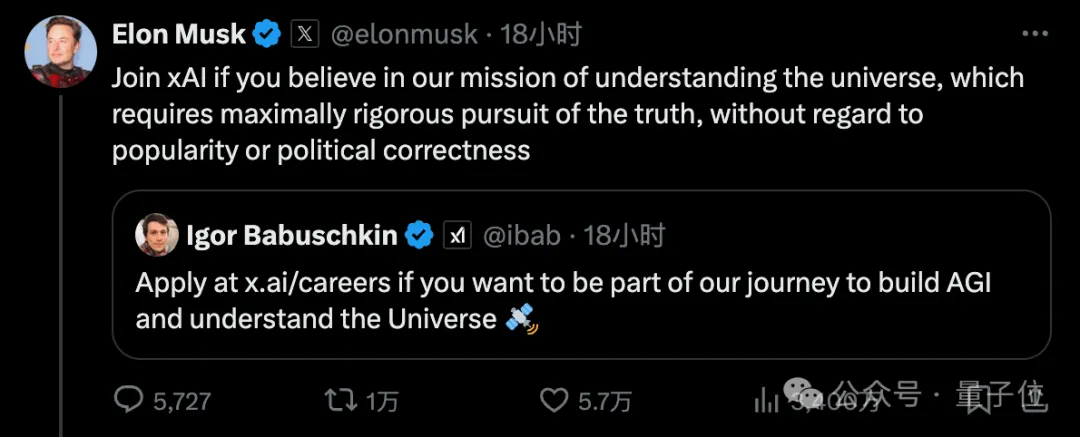
马斯克搞大模型又融到60亿美元(约435亿元)! 这是xAI最大的一轮融资,目前估值已来到240亿美元(约1738亿元),一举超过Anthropic,成为OpenAI之下第二位。 借着这个势头,老马也亲自下场发起招聘广告: 如果你相信我们理解宇宙的使命,需要最大限度地严格追求真理,而不考虑受欢迎程度或政治正确性,欢迎加入xAI。

人人都知大模型时代具身智能大有可为。 但这座连接起大模型和现实物理世界的桥梁,究竟应该如何搭建? 逐际动力联合创始人兼首席运营官张力,在中国AIGC产业峰会上给出思考: AI代替人去决策,人形机器人代替人去劳动。

更适配中文的语音大模型来了—— 来自中国电信人工智能研究院,AI领域Fellow大满贯科学家李学龙带队,发布首个能听懂30多种多方言混说的大模型。 号称最难方言、“魔鬼的语言”的温州话,也不在话下。
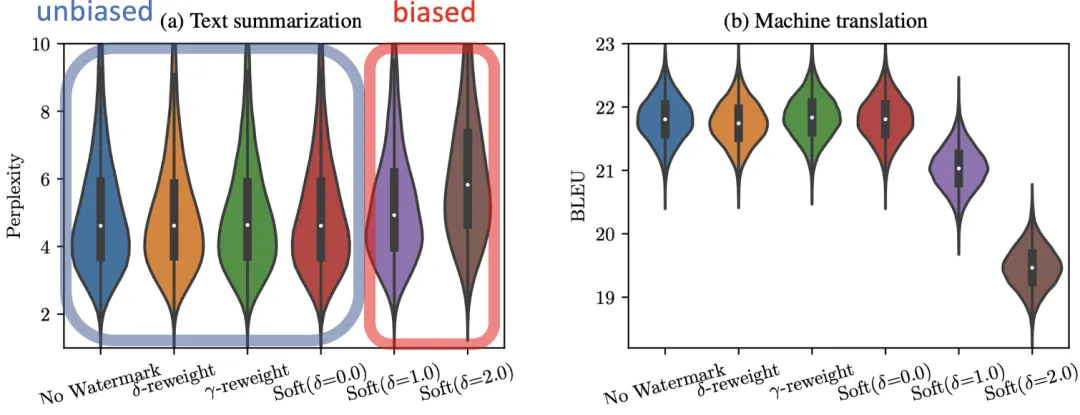
随着大语言模型(LLM)的快速发展,其在文本生成、翻译、总结等任务中的应用日益广泛。如微软前段时间发布的Copilot+PC允许使用者利用生成式AI进行团队内部实时协同合作,通过内嵌大模型应用,文本内容可能会在多个专业团队内部快速流转,对此,为保证内容的高度专业性和传达效率,同时平衡内容追溯、保证文本质量的LLM水印方法显得极为重要。

一位优秀的相声演员需要吹拉弹唱样样在行,类似地,一个优秀的机器人模型也应能适应多样化的机器人形态和不同的任务,但目前大多数机器人模型都只能控制一种形态的机器人执行一类任务。现在 Octo(八爪鱼)来了!这个基于 Transformer 的模型堪称当前最强大的开源机器人学习系统,无需额外训练就能完成多样化的机器人操控任务并能在一定程度适应新机器人形态和新任务,就像肢体灵活的八爪鱼。

AI 智能体的宣传很好,现实不太妙。

iVideoGPT,满足世界模型高交互性需求。
相同性能情况下,延迟减少 46%,参数减少 25%。

通过提示查询生成模块和任务感知适配器,大一统框架VimTS在不同任务间实现更好的协同作用,显著提升了模型的泛化能力。该方法在多个跨域基准测试中表现优异,尤其在视频级跨域自适应方面,仅使用图像数据就实现了比现有端到端视频识别方法更高的性能。

