

杀疯了!谷歌卷视频到语音,逼真音效让AI视频告别无声!
杀疯了!谷歌卷视频到语音,逼真音效让AI视频告别无声!AI圈这遍地开花的大好局面,让吃瓜群众们甚是惊喜。
来自主题:
AI技术研报
9783 点击 2024-06-19 23:44
 搜索
搜索
AI圈这遍地开花的大好局面,让吃瓜群众们甚是惊喜。

潞晨 Open-Sora 团队在 720p 高清文生视频质量和生成时长上实现了突破性进展,支持无缝产出任意风格的高质量短片,令人惊喜的是,他们选择再给开源社区带来亿点点震撼,继续全部开源。

基于 Transformer架构的大型语言模型在各种基准测试中展现出优异性能,但数百亿、千亿乃至万亿量级的参数规模会带来高昂的服务成本。例如GPT-3有1750亿参数,采用FP16存储,模型大小约为350GB,而即使是英伟达最新的B200 GPU 内存也只有192GB ,更不用说其他GPU和边缘设备。

通过高保真合成语音与真人语音无异。

本⽂介绍由清华等⾼校联合推出的⾸个开源的⼤模型⽔印⼯具包 MarkLLM。MarkLLM 提供了统⼀的⼤模型⽔印算法实现框架、直观的⽔印算法机制可视化⽅案以及系统性的评估模块,旨在⽀持研究⼈员⽅便地实验、理解和评估最新的⽔印技术进展。通过 MarkLLM,作者期望在给研究者提供便利的同时加深公众对⼤模型⽔印技术的认知,推动该领域的共识形成,进⽽促进相关研究的发展和推⼴应⽤。

本研究评估了先进多模态基础模型在 10 个数据集上的多样本上下文学习,揭示了持续的性能提升。批量查询显著降低了每个示例的延迟和推理成本而不牺牲性能。这些发现表明:利用大量演示示例可以快速适应新任务和新领域,而无需传统的微调。

在现实世界的机器学习应用中,随时间变化的分布偏移是常见的问题。这种情况被构建为时变域泛化(EDG),目标是通过学习跨领域的潜在演变模式,并利用这些模式,使模型能够在时间变化系统中对未见目标域进行良好的泛化。然而,由于 EDG 数据集中时间戳的数量有限,现有方法在捕获演变动态和避免对稀疏时间戳的过拟合方面遇到了挑战,这限制了它们对新任务的泛化和适应性。
OpenAI和谷歌接连两场发布会,把AI视频推理卷到新高度。 但业界还缺少可以全面评估大模型视频推理能力的基准。 终于,多模态大模型视频分析综合评估基准Video-MME,全面评估多模态大模型的综合视频理解能力,填补了这一领域的空白。
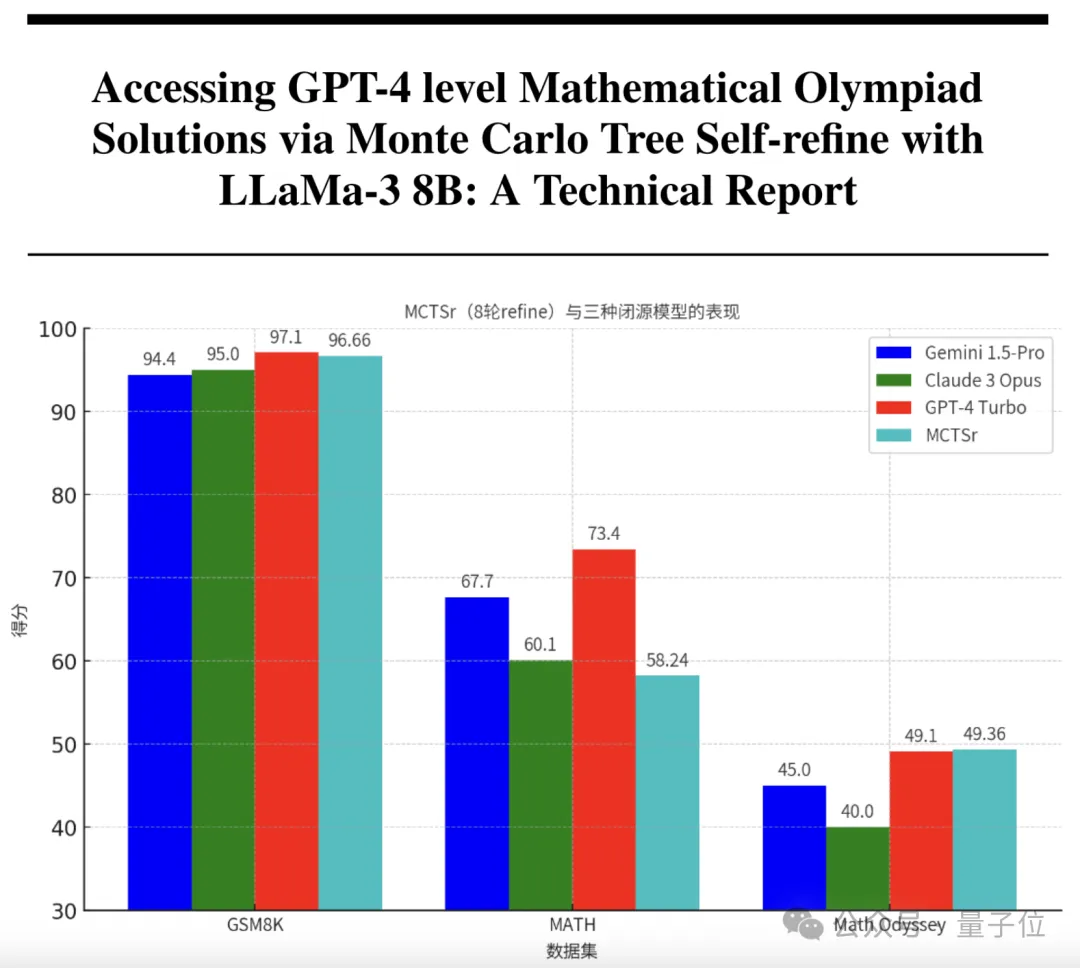
只要1/200的参数,就能让大模型拥有和GPT-4一样的数学能力? 来自复旦和上海AI实验室的研究团队,刚刚研发出了具有超强数学能力的模型。 它以Llama 3为基础,参数量只有8B,却在奥赛级别的题目上取得了比肩GPT-4的准确率。

一张人像、一段音频参考,就能让霉霉在你面前唱碧昂丝的《Halo》。
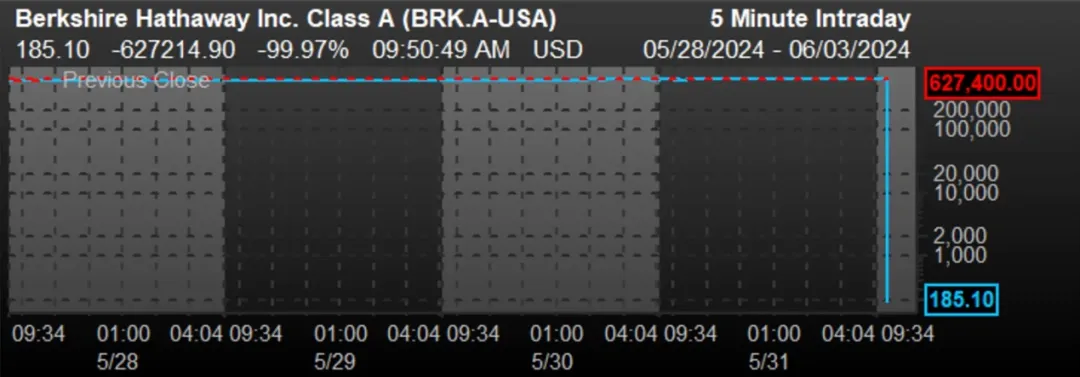
一个“技术问题”,导致巴菲特的伯克希尔-哈撒韦公司股价暴跌近100%。 想必很多小伙伴已经感受过了这则铺天盖地的消息,所带来的亿点点震撼。

一周前,苹果在WWDC上发布了自己的AI功能Apple Intelligence,包括直接集成OpenAI的ChatGPT,自那以来,股价上涨逾7%,重夺全球市值第一宝座。
AI在科技界的发展类似于一场“卖拐”行为,需回归到现实场景中去感受新技术的实际应用。 • ???? 元宇宙、AI发布会等科技狂欢背后的思考模式和现实应用之间的落差 • ???? AI产品需要以角色为中心,寻找智能的价值密度,避免“似懂非懂”的迷信现象 • ???? AI发展需要结合自下而上的实践和自上而下的战略思考,重点在于角色重组和感受落地化

Alembic首次推出用于企业数据分析和决策支持的无「幻觉」人工智能。
Build大会召开两周之后,微软更新了Phi-3系列模型的技术报告。不仅加入最新的基准测试结果,而且对小模型、高性能的实现机制做出了适当的揭示。

雷·库兹韦尔即将出版《奇点临近》的全新续作——《奇点更近》。在书中,他更加大胆地承诺,人类可以获得「永生」,库兹韦尔认为在本世纪40-50年代,人类将重建自己的身体和大脑,使其远远超出我们生物体的能力。

大语言模型提示中,竟有不少「怪癖」:重复某些内容,准确性就大大提高;人名变匿名,准确性就大大下降。最近,马里兰OpenAI等机构的30多位研究者,首次对LLM的提示技术进行了大规模系统研究,并发布75页详尽报告。

DeepMind最近发表的一篇论文提出用混合架构的方法解决Transformer模型的推理缺陷。将Transformer的NLU技能与基于GNN的神经算法推理器(NAR)的强大算法推理能力相结合,可以实现更加泛化、稳健、准确的LLM推理。

大语言模型(LLM)的迅速发展,引发了关于如何评估其公平性和可靠性的热议。

当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。

通过算法层面的创新,未来大语言模型做数学题的水平会不断地提高。

AI 研究发展的主要推动力是什么?在最近的一次演讲中,OpenAI 研究科学家 Hyung Won Chung 给出了自己的答案。

2024 年 5 月,DreamTech 官宣了其高质量 3D 生成大模型 Direct3D,并公开了相关学术论文 Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer。

语言将是获得更智能系统的重要组成部分。

苹果讲了一个按Query难度分发模型的模式:B小模型:大多数场景,包括自动回复、改写、语法检查、Summary都用端侧的小模型跑。

过去一年人工智能研究取得了重大突破

马斯克禁用苹果设备是出于数据安全考虑,其实背后依旧暗藏着马斯克和OpenAI的纷争
在面对广阔的市场时,既不断进化自身的优势,又力求实现“小而美”的精致与专注

有大视角,才不会被细节迷惑。
文章讲述了彩云科技团队在改进Transformer架构方面的努力,尤其是推出的全新通用模型架构DCFormer,以及团队面临的种种挑战和突破。

