


OpenAI:以后大家用AI赚的钱,我可能要抽成
OpenAI:以后大家用AI赚的钱,我可能要抽成编辑|杜伟、泽南 今天一早,OpenAI CEO 奥特曼就发推晒收入,「仅我们的 API 业务而言,上个月就增加了超过 10 亿美元的 ARR(年度经常性收入)。」 他继续说到,大多数人只看到了 Ch
来自主题:
AI资讯
9570 点击 2026-01-24 10:59
 搜索
搜索
编辑|杜伟、泽南 今天一早,OpenAI CEO 奥特曼就发推晒收入,「仅我们的 API 业务而言,上个月就增加了超过 10 亿美元的 ARR(年度经常性收入)。」 他继续说到,大多数人只看到了 Ch

AI 推理基础设施公司 Baseten 近日完成一轮 3 亿美元的成长型融资,投后估值约 50 亿美元。与不到六个月前的一轮重要融资相比,公司估值几乎翻倍。 这一交易清晰地表明,在大模型训练之外,推理
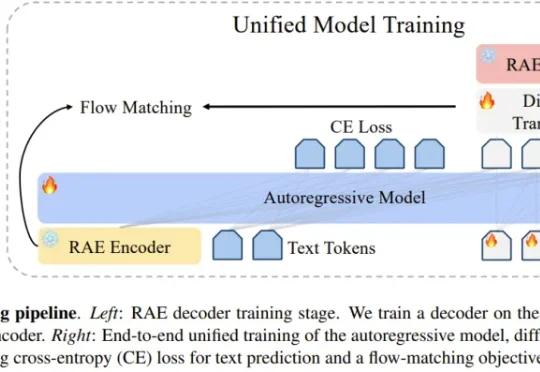
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视
1月22日,证监会官网披露,苏州AI语音交互解决方案企业思必驰科技股份有限公司在上海证监局办理上市辅导备案登记,重新启动A股IPO进程,辅导机构是东吴证券。
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。

但扣子 2.0 做的事情,不只是跟进 Skill 这个概念:它想要把 Skill 与「扣子编程」深度融合,从而打造一整套「职场 AI」解决方案。

这篇新论文提出了一种非常简单的新激活层 Derf(Dynamic erf),让「无归一化(Normalization-Free)」的 Transformer 不仅能稳定训练,还在多个设置下性能超过了带 LayerNorm 的标准 Transformer。
《晚点 LatePost》独家获悉,快手旗下视频生成大模型可灵 AI 的月活跃用户(MAU)在今年 1 月突破 1200 万。

上海交通大学、波恩大学等院校的研究团队全面总结了当前机器人技术中常用的场景表示方法。这些方法包括传统的点云、体素栅格、符号距离函数以及场景图等传统几何表示方式,同时也涵盖了最新的神经网络表示技术,如神经辐射场、3D 高斯散布模型以及新兴的 3D 基础模型。

一家线上语言学习平台Preply——在最新一轮融资中筹集了 1.5 亿美元,其估值飙升至 12 亿美元,几乎翻了三倍。本轮D 轮融资由 WestCap 领投。据彭博社获得的声明显示,此次融资使 Preply 的总融资额超过 2.99 亿美元。

新公司名为Advanced Machine Intelligence(AMI),也就是先进机器智能,法语里意为“朋友”。总部位于巴黎,并将在纽约、蒙特利尔、新加坡等地分别设立运营机构。而且和硅谷最近的闭源趋势不同,AMI all in开源。
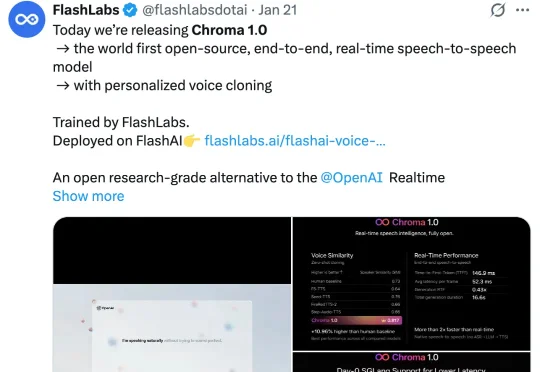
近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。
就在最近,OpenAI 终于把"丹炉"和"配方"都端出来了。OpenAI Academy 悄悄上线了一个名为 Prompt Packs(提示词包) 的资源库。
2025年,Vincent下场创立了全新的AI媒体资讯平台Ancher,决意拥抱从移动客户端到AI化浪潮的又一次媒体革命。他说他“抛弃了所有过去信息流的玩法”,要做一个完全AI Native的新闻产品。

谷歌 DeepMind 发布 D4RT,彻底颠覆了动态 4D 重建范式。它抛弃了复杂的传统流水线,用一个统一的「时空查询」接口,同时搞定全像素追踪、深度估计与相机位姿。不仅精度屠榜,速度更比现有 SOTA 快出 300 倍。这是具身智能与自动驾驶以及 AR 的新基石,AI 终于能像人类一样,实时看懂这个流动的世界。

史上最强模型Claude Opus 4.5发布后,全面碾压了人类顶尖工程师,逼得Anthropic不得不被迫放弃招聘笔试!现在,内部考题已经全面开源了。
AI 生成的句子很流畅,逻辑也没毛病,但总有一种怪怪的感觉:就像穿了一件别人挑的衣服,尺码没问题,风格也没问题,但穿在身上就是觉得不是自己。我一度以为这就是 AI 写作的天花板,直到我这两天深度用了 ima 的「AI 帮写」。
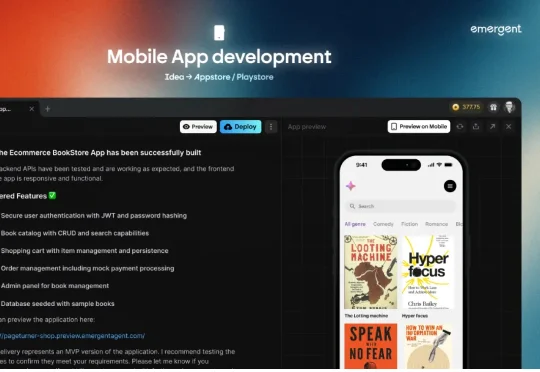
这家由双胞胎兄弟Mukund和Madhav Jha创立的印度创业公司,刚刚完成了由软银和Khosla Ventures领投的7000万美元B轮融资。更令人震撼的是,他们在推出产品后仅仅90天内,就实现了1500万美元的ARR,7个月做到了5000万美金ARR,成为全球增长最快的创业公司之一。
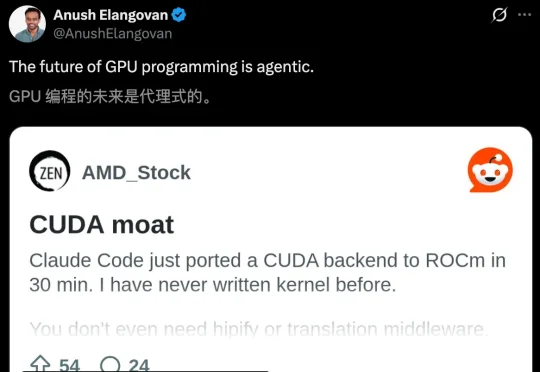
英伟达护城河要守不住了?Claude Code半小时编程,直接把CUDA后端迁移到AMD ROCm上了。 一夜之间,CUDA护城河被AI终结了? 这几天,一位开发者johnnytshi在Reddit上分享了一个令人震惊的操作:
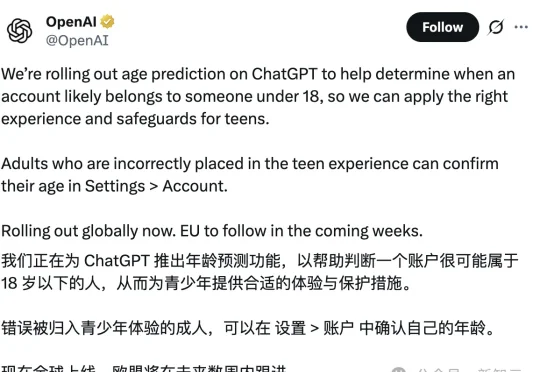
ChatGPT也推出「防沉迷系统」了?如果你习惯用缩写、语气太嫩,或者仅仅是作息不规律,都可能被判定为未成年!想恢复成人权限,代价是上传你的脸部3D扫描数据。不需要等到未来,欢迎来到2026年的「行为算命」时代。
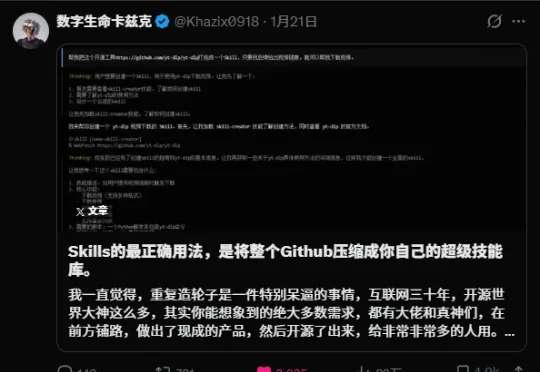
今天这篇可能会稍微硬核一点。 但是我保证,还是有蛮多干货的!也相信绝对会对大家有一点用。 SKills,从入门到现在,我已经连续写了好几篇文章了。 不为别的,我是真的觉得,这玩意不管对个人还是对团队,
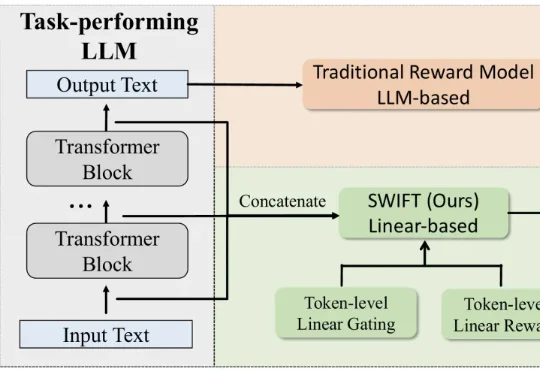
最新奖励模型SWIFT直接利用模型生成过程中的隐藏状态,参数规模极小,仅占传统模型的不到0.005%。SWIFT在多个基准测试中表现优异,推理速度提升1.7×–6.7×,且在对齐评估中稳定可靠,展现出高效、通用的奖励建模新范式。
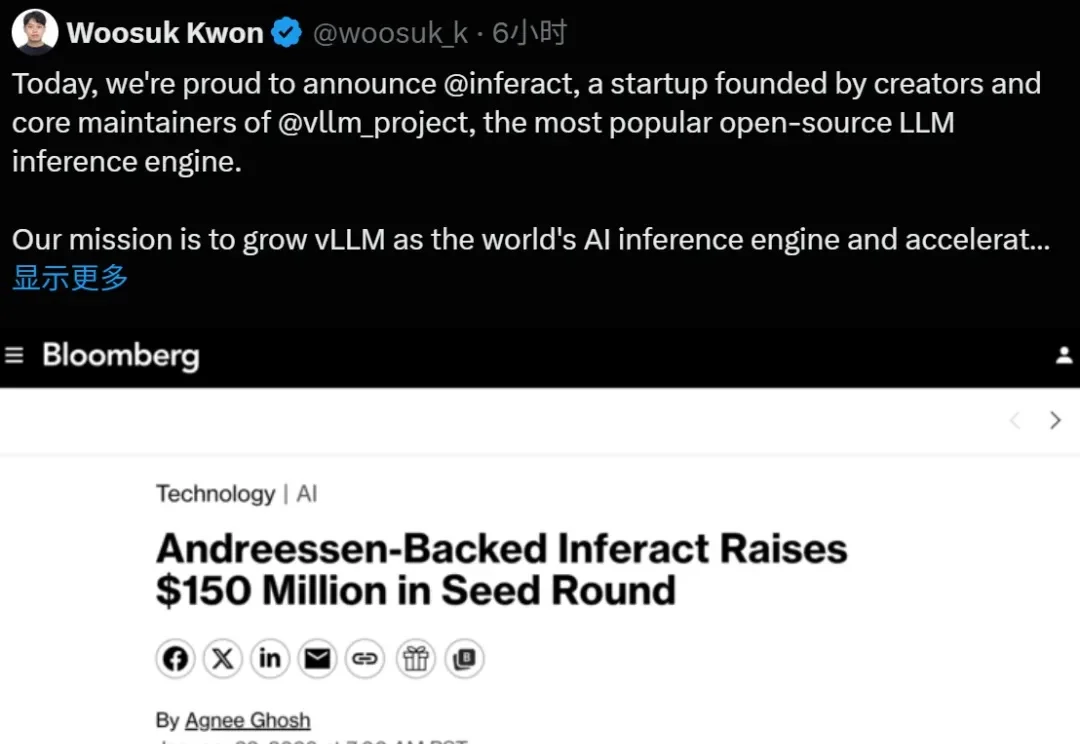
大模型推理的基石 vLLM,现在成为创业公司了。

AI爬取数据规模可提升5000倍。

腾讯持股20%,年销3.9万张AI加速卡及模组。

AI 创业两年,我们在一直思考一个问题:到底 AI 能够给现实生活中的普通人带来什么? 一方面新概念层出不穷,但大部分概念身边没有几个人能听懂。另一方面,AI 的叙事都在讲替代人工、降本增效——似乎

全新的产品形态有多大空间?

最近 AI 编程界最火的事情,就是怎么把各种 coding 模型卷到极致了。
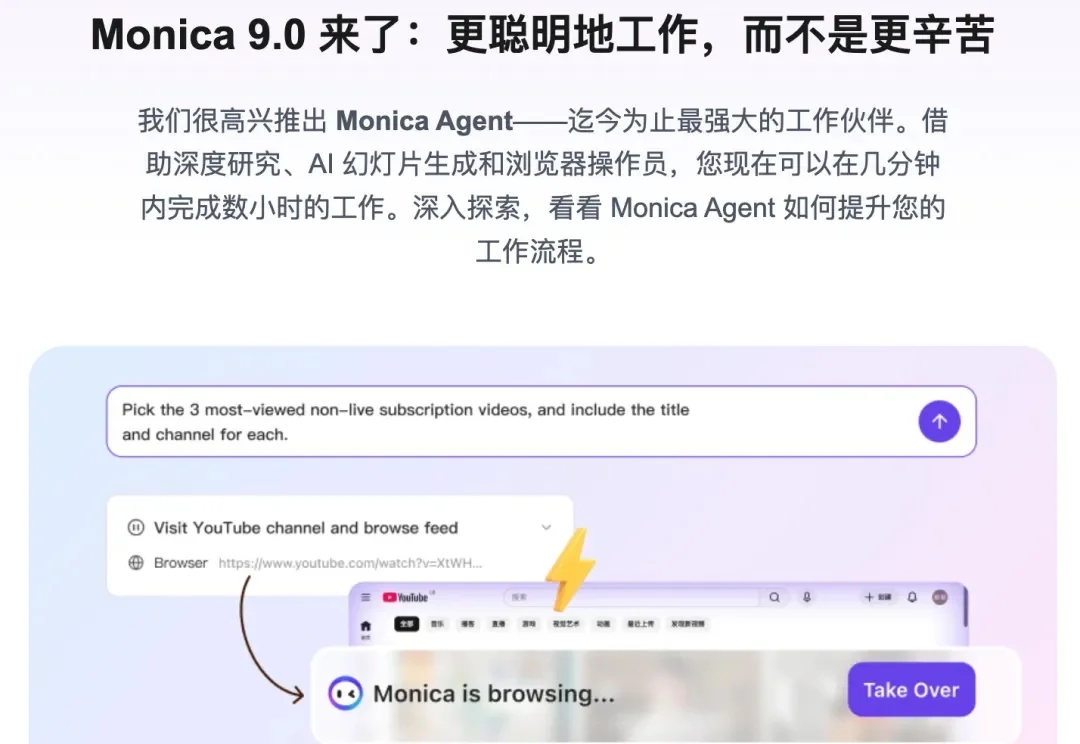
Monica 终于更新了!他是之前卖了几十亿的 Manus 母公司的起家产品。

OpenAI 收购 Torch Health 这件事,这两天我看到很多解读,基本都落在两个方向。一个是人才收购,四个人的小团队,买回去做 ChatGPT Health 的一块拼图。另一个是医疗布局,OpenAI 终于开始认真做垂直行业了。

