

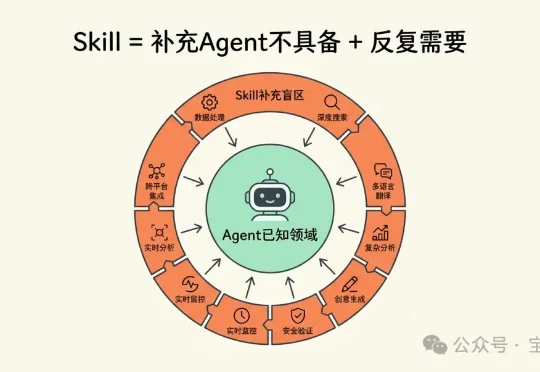
别把整个 GitHub 装进 Skills,Skills 的正确用法
别把整个 GitHub 装进 Skills,Skills 的正确用法这篇《Skills 的最正确用法,是将整个 Github 压缩成你自己的超级技能库》绝对是一篇绝佳的入门指南,但也要注意:这种用法,还当不起“最”正确用法。 我不是来抬杠的,而是想聊聊:怎么更好地使用
来自主题:
AI技术研报
8812 点击 2026-01-25 11:59
 搜索
搜索
这篇《Skills 的最正确用法,是将整个 Github 压缩成你自己的超级技能库》绝对是一篇绝佳的入门指南,但也要注意:这种用法,还当不起“最”正确用法。 我不是来抬杠的,而是想聊聊:怎么更好地使用
Claude Cowork企业版,刚刚正式上线了!而且,Claude Code之父Boris Cherny还在40分钟访谈中,大方自曝了自己的私家配置,一连串硬核干货袭来,围观网友大呼过瘾!
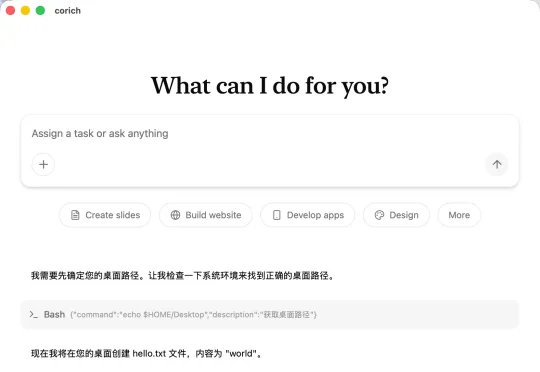
复盘一下我vibe coding 一周,开发 WorkAny 的过程,很有意思。 1. 上周三在香港办卡,临时起意想做个桌面 Agent 项目,对标 cowork,晚上回到广州开始写代码 2. 初期目标是快速发布,没时间去研究哪个 Agent 框架好用了,看很多人在用 claude agent sdk,先用这个吧

1944 年,法国诺曼底。 你是一名刚刚结束两年的训练、还没上过火线的陆军列兵,靠着无人能敌的运气和坚如磐石的八字,从清晨的抢滩登陆中活了下来,甚至连身上的装备都没怎么使用,仅仅受了一点皮外伤。 「最
真没想到,MiniMax Agent 居然赶在春节前又放了个大招!MiniMax 桌面端 + 专家模式同步上线!说实话,MiniMax 这迭代效率着实太高了,追的我测评都有点肝不动了
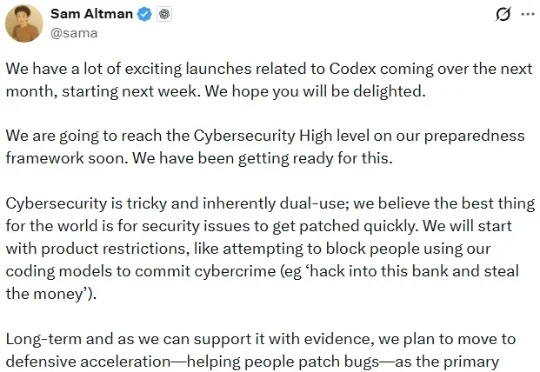
刚刚,OpenAI CEO 山姆・奥特曼发了一条推文:「从下周开始的接下来一个月,我们将会发布很多与 Codex 相关的激动人心的东西。」他尤其强调了网络安全这个主题。
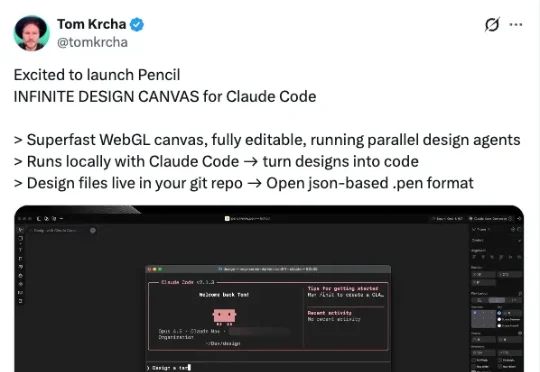
在看了Claude Code 能编码、写作、办公等等一系列操作后, 它终于还是把手伸到了设计领域。 昨天我正好刷到一个产品叫Pencil, 热度非常高。

LOOKEE口语侠以无屏陪伴形态,重点切入6-12岁儿童的口语学习场景。无屏化的优势不仅是保护视力,它更通过移除视觉依赖,迫使孩童回归“听”与“说”的语言本质,在纯粹的音频交互中理解问题并给出回应,构建内在的语言逻辑。

动点出海获悉,总部位于新加坡的AI初创公司Level3AI已宣布完成1300万美元的种子轮融资。据悉,本轮融资由Lightspeed领投,BEENEXT、500 Global、Sovereign’s Capital以及Goodwater Capital参与跟投。

扒光了这个黑客松冠军的 GitHub 仓库,我才发现自己根本不会用 Claude Code 最近很多人在后台问我 Claude Code 的使用技巧。说实话,大部分人的用法都太业余了。 如果你只是把
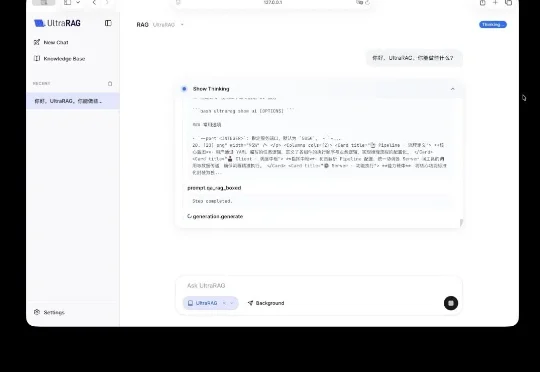
今天,清华大学 THUNLP 实验室、东北大学 NEUIR 实验室、OpenBMB 、面壁智能与 AI9Stars 联合发布 UltraRAG 3.0 ,针对上述痛点,为科研工作者与开发者打造更懂开发者的技术框架,具备 3 大核心优势:

刚刚,英伟达杰出工程师许冰(Bing Xu)在 GitHub 上开源了一个新项目 VibeTensor,让我们看到了 AI 在编程方面的强大实力。从名字也能看出来,这是 Vibe Coding 的成果。事实也确实如此,这位谷歌学术引用量超 20 万的工程师在 X 上表示:「这是第一个完全由 AI 智能体生成的深度学习系统,没有一行人类编写的代码。」

最近,移动应用数据分析商 Sensor Tower 发布了一份《State of Mobile 2026》。AI 应用的增长不但没有减速,反而更快了。AI 应用的下载量翻倍,达到 38 亿次;IAP 收入增长超过三倍,突破 50 亿美元;

近日,OpenAI一位华人研发工程师,翁家翌在一期播客采访中曝出了不少猛料。可以说是把如今的顶流OpenAI过去三年的重大转折、技术取舍、Infra、甚至包括那次各个谣传版本的“宫斗风波”。

在文心Moment大会上,文心大模型5.0正式版上线。据称,该模型参数量达2.4万亿,采用原生全模态统一建模技术,具备全模态理解与生成能力,支持文本、图像、音频、视频等多种信息的输入与输出。

编辑|杜伟、泽南 今天一早,OpenAI CEO 奥特曼就发推晒收入,「仅我们的 API 业务而言,上个月就增加了超过 10 亿美元的 ARR(年度经常性收入)。」 他继续说到,大多数人只看到了 Ch

AI 推理基础设施公司 Baseten 近日完成一轮 3 亿美元的成长型融资,投后估值约 50 亿美元。与不到六个月前的一轮重要融资相比,公司估值几乎翻倍。 这一交易清晰地表明,在大模型训练之外,推理
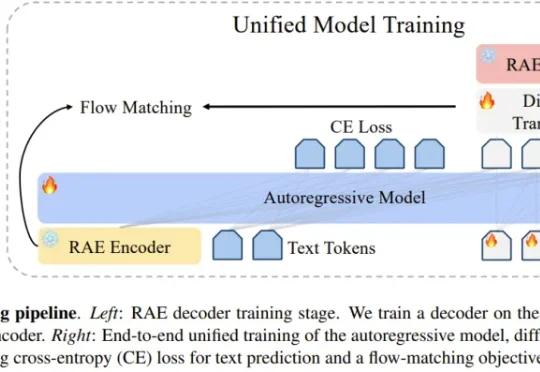
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视
1月22日,证监会官网披露,苏州AI语音交互解决方案企业思必驰科技股份有限公司在上海证监局办理上市辅导备案登记,重新启动A股IPO进程,辅导机构是东吴证券。
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。

但扣子 2.0 做的事情,不只是跟进 Skill 这个概念:它想要把 Skill 与「扣子编程」深度融合,从而打造一整套「职场 AI」解决方案。

这篇新论文提出了一种非常简单的新激活层 Derf(Dynamic erf),让「无归一化(Normalization-Free)」的 Transformer 不仅能稳定训练,还在多个设置下性能超过了带 LayerNorm 的标准 Transformer。
《晚点 LatePost》独家获悉,快手旗下视频生成大模型可灵 AI 的月活跃用户(MAU)在今年 1 月突破 1200 万。

上海交通大学、波恩大学等院校的研究团队全面总结了当前机器人技术中常用的场景表示方法。这些方法包括传统的点云、体素栅格、符号距离函数以及场景图等传统几何表示方式,同时也涵盖了最新的神经网络表示技术,如神经辐射场、3D 高斯散布模型以及新兴的 3D 基础模型。

一家线上语言学习平台Preply——在最新一轮融资中筹集了 1.5 亿美元,其估值飙升至 12 亿美元,几乎翻了三倍。本轮D 轮融资由 WestCap 领投。据彭博社获得的声明显示,此次融资使 Preply 的总融资额超过 2.99 亿美元。

新公司名为Advanced Machine Intelligence(AMI),也就是先进机器智能,法语里意为“朋友”。总部位于巴黎,并将在纽约、蒙特利尔、新加坡等地分别设立运营机构。而且和硅谷最近的闭源趋势不同,AMI all in开源。
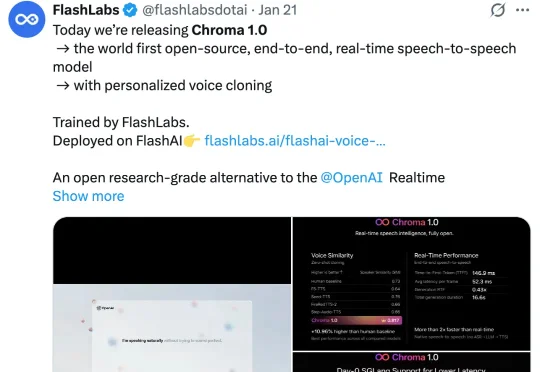
近期,FlashLabs 发布并开源了其实时语音模型 Chroma 1.0,其定位为全球首个开源的端到端语音到语音模型。Chroma 1.0 发布之后,便在社媒爆火,吸引了大量的关注。X 上的官推帖子已经突破了百万浏览量。
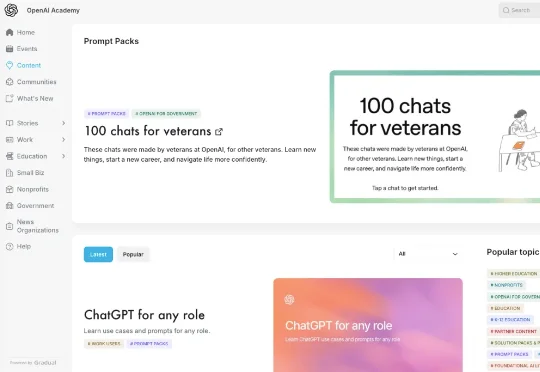
就在最近,OpenAI 终于把"丹炉"和"配方"都端出来了。OpenAI Academy 悄悄上线了一个名为 Prompt Packs(提示词包) 的资源库。
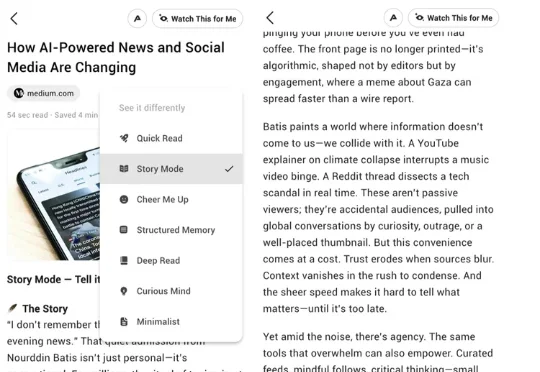
2025年,Vincent下场创立了全新的AI媒体资讯平台Ancher,决意拥抱从移动客户端到AI化浪潮的又一次媒体革命。他说他“抛弃了所有过去信息流的玩法”,要做一个完全AI Native的新闻产品。

谷歌 DeepMind 发布 D4RT,彻底颠覆了动态 4D 重建范式。它抛弃了复杂的传统流水线,用一个统一的「时空查询」接口,同时搞定全像素追踪、深度估计与相机位姿。不仅精度屠榜,速度更比现有 SOTA 快出 300 倍。这是具身智能与自动驾驶以及 AR 的新基石,AI 终于能像人类一样,实时看懂这个流动的世界。

