# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一直以来,LLM智能体被众多业界AI大佬看好,甚至有望成为将人类从琐碎工作中解放出来的利器。
但是,它们该如何与世界进行最佳互动?
最近,来自UIUC和苹果的华人研究员,提出了一种全新的智能体框架——CodeAct。
它通过采用可执行的Python代码,来统一LLM智能体的行动。

论文地址:https://arxiv.org/pdf/2402.01030.pdf
与多数现有的LLM智能体不同的是,CodeAct的突出之处在于:能够充分利用现有LLM对代码数据的预训练,以实现低成本高效的采用。
而且本质上可以通过控制和数据流支持复杂的操作,还可以使用广泛的软件包来扩展行动空间和自动反馈。
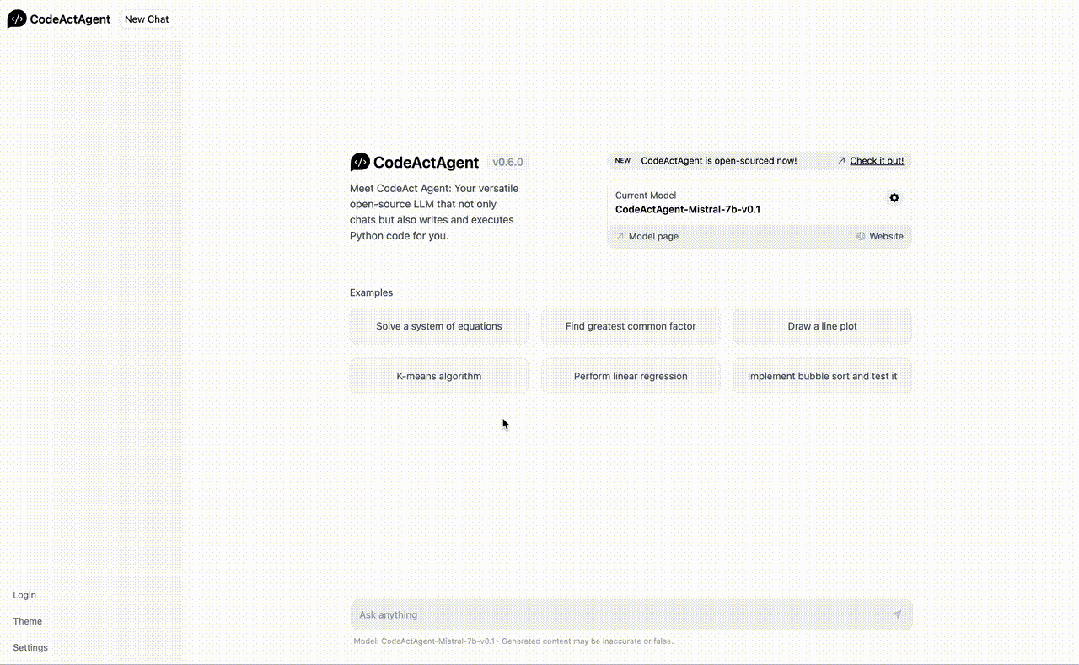
对此,作者还构建了一个CodeActAgent工具,在Mistral 7B模型之上搭建,能够通过对话完成代码任务。
比如,「你能创建100个随机数据点(每个数据点的维度为 2)并创建散点图吗?运行 k-means 对它们进行聚类并可视化」。
当允许访问API的行动模块进行增强时,LLM的行动空间可以扩展到传统的文本处理之外。
从而让LLM获得工具调用和内存管理等功能,并冒险进入现实世界的任务,例如控制机器人并进行科学实验 。
那么,如何有效拓展LLM智能体解决复杂现实问题的行动空间?

如下图1左上,许多现有研究已经检验了使用文本,或JSON来生成行动。
然而,这两种方法通常都受到行动空间范围的限制(行动通常是针对特定任务定制的)和灵活性有限(例如无法在单个行动中组合多个工具)。
另外一些研究展示了,使用LLM生成代码来控制机器人或游戏角色的潜力。
然而,它们通常依赖于预先指定的控制原语和手工设计的提示,更重要的是,它们很难根据新的环境观察和反馈动态调整或发出行动。

对此,这项研究提出了一个通用框架CodeAct,允许LLM生成可执行的Python代码作为行动(图1右上)。
CodeAct旨在处理各种应用程序,并具有独特的优势:
(1) CodeAct与Python解释器集成,可以执行代码行动,并动态调整先前的行动,或根据通过多轮交互(代码执行)收到的观察结果发出新行动。
(2) 代码行动允许LLM利用现有软件包。CodeAct可以使用现成的Python包来扩展行动空间,而不是手工制作的特定于任务的工具。它还允许大模型使用大多数软件中实现的自动反馈(例如错误消息),通过自我调试其生成的代码来改进任务解决。
(3) 代码数据广泛应用于当今大模型的预训练中。这些模型已经熟悉结构化编程语言,因此可以经济高效地采用 CodeAct。
(4) 与JSON和预定义格式的文本相比,代码本质上支持控制和数据流,允许将中间结果存储为变量以供重用,并用一段代码允许组合多个工具来执行复杂的逻辑操作(例如,if-语句、for循环),从而释放大模型预训练的编程知识来处理复杂任务的潜力。
在图1中,使用CodeAct(右上角)的法学硕士可以通过for循环将相同的工具序列应用到所有输入,只需一个行动。而文本或JSON必须对每个输入采取行动。
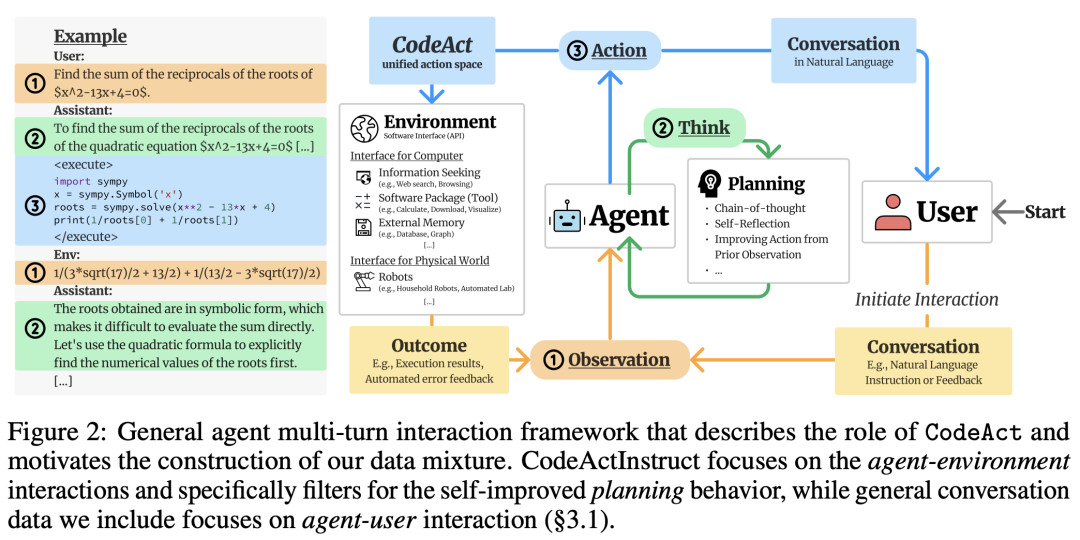
在图2中,首先介绍了LLM智能体在现实世界中使用的一般多轮交互框架,该框架考虑了三个角色:
智能体、用户、环境。
研究人员将交互定义为智能体与外部实体(用户或环境)之间的信息交换。
在每一轮交互中,智能体从用户(如自然语言指令)或环境(如代码执行结果)接收观察结果(输入),通过思维链(CoT)选择性地规划其行动,并以自然语言或环境向用户发出行动(输出)。
CodeAct采用Python代码来整合智能体与环境交互的所有操作。
在CodeAct中,向环境发出的每个动作都是一段Python代码,而智能体将收到代码执行的输出(如结果、错误)作为观察结果。
研究中,作者进行了一项对照实验,以了解哪种格式(文本、JSON、CodeAct)更有可能引导LLM生成正确的原子工具调用。
本实验的表现,反映了LLM对相应格式的熟悉程度。
研究人员假设使用CodeAct调用工具是为模型使用工具的更自然的方式,模型通常在训练期间广泛接触代码数据。
对于大多数LLM,即使在其控制和数据流强度被削弱的原子操作(简单化的工具使用场景)中,CodeAc也能实现相当或更好的性能。
与闭源LLM相比,CodeAct的改进在开源模型中更为突出。
此外,对于微调开源LLM来说,代码数据通常比专门JSON或文本工具调用格式更容易访问。尽管JSON始终弱于其他开源模型方法,但它在闭源LLM中实现了不错的性能,这表明这些闭源模型可能已经针对其JSON功能进行了有针对性的微调。
这些结果表明,对于开源大模型来说,针对CodeAct进行优化是比其他方法更好的途径来提高其工具使用能力,因为由于在预训练期间广泛接触代码数据,它们已经表现出了良好的初始CodeAct能力。
除此之外,作者研究了LLM智能体是否可以,从需要复杂工具使用模式的问题上的代码控制和数据流中受益。
这里,研究人员策划了一个基准图片来评估LLM解决通常需要多次调用多个工具的复杂任务的能力。
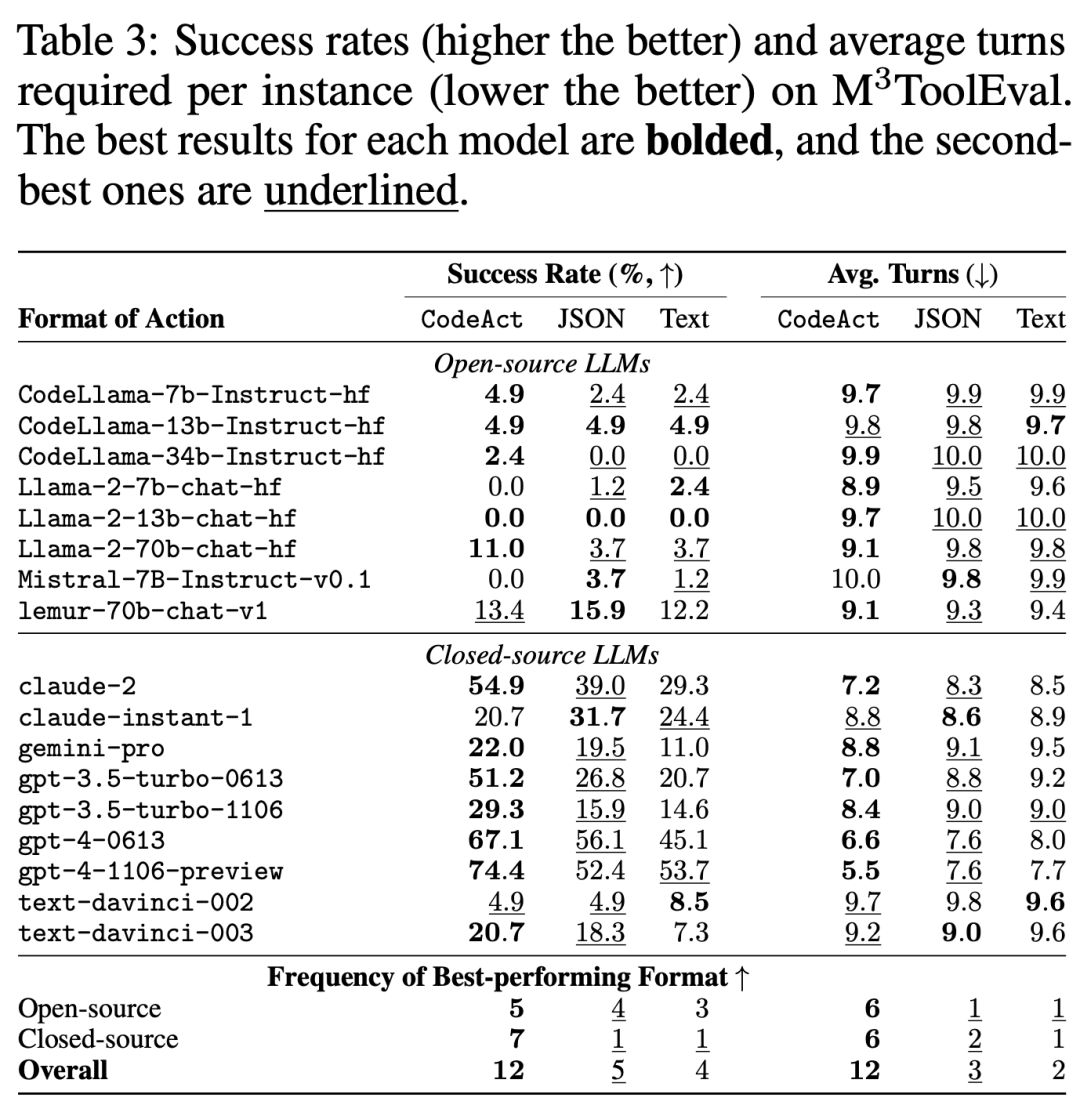
作者在表3中列出了全部结果,在图1中列出了可视化结果子集。
CodeAct通常具有更高的任务成功率(17个已评估LLM中有12个)。此外,使用CodeAct执行任务所需的平均交互轮数也较低。
比如,与次佳操作格式(文本)相比,最佳模型gpt-4-1106-preview实现了20.7%的绝对改进,同时平均减少了2.1个交互回合。
然而,就CodeAct的绝对性能而言,开源和闭源LLM之间仍存在显著差距,最佳开源模型的绝对性能提高了13.4%,而最佳闭源模型gpt-4-1106-preview的绝对性能提高了74.4%。
这可能是由于开源模型的任务解决能力较弱,无法在没有演示的情况下遵循复杂指令,这表明迫切需要改进开源 LLM,以在零样本设置下完成实际任务。
研究人员还展示了LLM智能体如何与Python集成,并使用现有软件在多轮交互中执行复杂的任务。
得益于在预训练期间学到的丰富的Python知识,LLM智能体可以自动导入正确的Python库来解决任务,而不需要用户提供的工具或演示。
如图3所示,CodeActAgent可以使用Pandas下载和处理表格数据,使用Scikit-Learn进行机器学习训练-测试数据分割和回归模型训练,并使用Matplotlib用于数据可视化。
此外,使用交互式Python解释器执行代码可以自动显示错误消息,帮助LLM智能体在多轮交互中「自我调试」其操作,并最终正确完成人类用户的请求。

CodeAct所展示潜力的结果,激励研究人员构建一个开源的LLM智能体,可以通过CodeAct与环境交互,又可以使用语言与人类进行交流。
为了提高开源LLM的CodeAct能力,作者介绍了CodeActInstruct,这是一个包含智能体与环境交互轨迹的指令微调数据集。
如表4,是CodeActInstruct的数据组成,以及与先前工作的对比。

接下来,研究人员对Llama-2 7B和Mistral 7B的CodeActInstruct和一般对话进行了微调,进而获得CodeActAgent
CodeActAgent在CodeAct任务中表现出色。
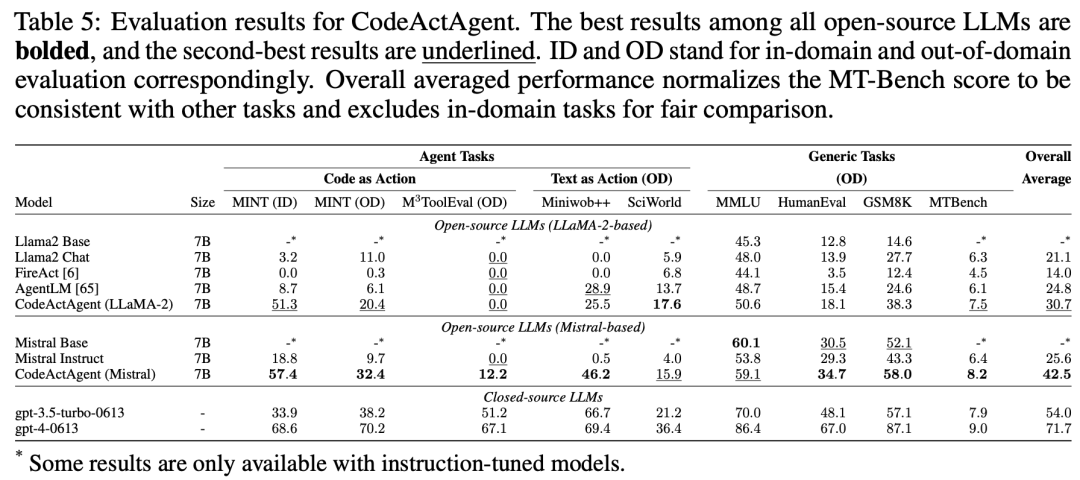
如表5所示,CodeActAgent(两种变体)在MINT的域内和域外子集上都比所有评估的开源LLM表现更好。
在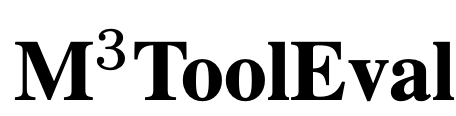 上,作者发现CodeActAgent(Mistral)的性能优于类似规模(7B和13B)的开源LLM,甚至达到了与70B模型相似的性能。
上,作者发现CodeActAgent(Mistral)的性能优于类似规模(7B和13B)的开源LLM,甚至达到了与70B模型相似的性能。
令人惊讶的是,Llama-2变体没有观察到任何改进。
CodeActAgent概括为文本操作。
当对域外文本操作进行评估时,从未针对文本操作进行过优化的CodeActAgent (LLaMA2, 7B) 实现了与对文本操作进行显式调整的AgentLM-7B相当的性能。
在表5中,还发现CodeActAgent保持或提高了一般LLM任务的性能。
在表 5 中,研究人员还发现CodeActAgent(两个变体)在测试的一般LLM任务中表现更好,除了CodeActAgent(Mistral-7B)在MMLU上略有下降。
参考资料:
https://twitter.com/xingyaow_/status/1754556835703751087
文章来自微信公众号 “ 新智元 ”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
