# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在实践中,人类预测的准确性依赖于「群体智慧」(wisdom of the crowd)效应,即通过聚集一群个体预测者,对未来事件的预测准确率会显著提高。
过去关于大型语言模型(LLMs)预测能力的工作表明,即便是最强大的LLM也仍然比不过人类的群体智慧。
最近,来自伦敦政治经济学院、MIT和宾夕法尼亚大学的研究人员做了两项研究,通过简单、实际适用的预测集成方法,表明LLMs可以实现与人类群体竞赛相当的预测准确率。

论文链接:https://arxiv.org/pdf/2402.19379.pdf
在第一个研究中,将31个二元问题由12个LLM进行集成预测,与为期三个月的预测锦标赛中925名人类预测者的预测进行了比较,主要分析结果表明,LLM群体优于单纯的无信息基线模型,并且在统计上与人类
群体没有差异。
在探索性分析中,研究人员发现这两种方法在中等效应尺寸等价界限(medium-effect-size equivalence bounds)方面是相同的;还可以观察到一种默许效应(acquiescence effect),平均模型预测显著高于
50%,但正面和负面的分辨率几乎平分秋色。
在第二项研究中,研究人员测试了LLM预测(GPT-4和Claude 2)是否可以通过利用人类认知输出来改善,结果发现,两个模型的预测准确性都可以受益于将人类预测中值作为输入信息,从而将准确性提高了
17%至28%,但仍然低于简单的预测平均方法。
研究人员从12个不同的大型语言模型中收集数据来模拟LLM群体,分别是GPT-4、GPT-4(with Bing)、Claude 2、GPT3.5-Turbo-Instruct、Solar-0-70b、Llama-2-70b、PaLM 2(Chat-Bison@002)、Coral
(Command)、Mistral-7B-Instruct、Bard(PaLM 2)、Falcon-180B和Qwen-7B-Chat
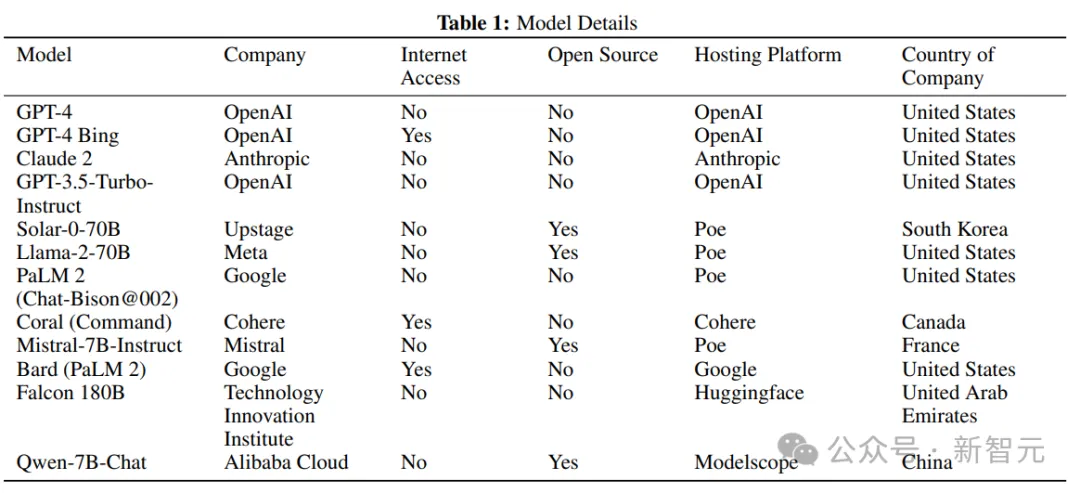
然后通过web界面访问模型,对所有模型使用默认参数(例如温度),其中web界面包括公司自行开发的界面,如OpenAI、Anthropic、Cohere和Google提供,以及其他第三方提供的界面,如Poe、
Huggingface和Modelscope,采用这种方法来最大化在收集数据的整个研究期间可以可靠查询的模型数量,同时保留模型规模的异质性。
具体选择的标准包括前沿模型(GPT-4,Claude 2)以及开源模型(例如,Llama-2-70b,Mistral 7B-Instruct),还有各种可访问互联网的型号(例如,with Bing、Bard、Coral的GPT-4),参数量从70亿到1.6万亿不等。
为了评估模型的预测能力,研究人员利用到Metaculus平台上从2023年10月到2024年1月举行的公共预测锦标赛中实时提出的预测问题,其中925名人类预测者提供了至少一个预测结果,提出的问题从中东冲
突、利率、文学奖、英国选举政治到印度空气质量、加密货币、消费技术和太空旅行。
研究人员主要关注二元概率预测,总共收集了31个问题,其中每个问题都包括一个问题描述,所提问题的背景,以及一个详细说明问题将如何解决的方案。
研究人员编写的提示词中包括如何格式化输出的说明、指示模型作为超级预测者做出响应,并按照当前的最佳提示实践逐步处理这些问题;提示中还包括了详细的问题背景、解决标准和问题文本。

实验结果
研究人员从集成的12个LLM的31个问题中收集了总共1007个单独的预测,剩余的109个预测由于模型或界面的技术问题,或是内容限制政策没有收集完成。
在所有模型和问题中,研究人员观察到最小原始预测值为0.1%,最大原始预测值为99.5%,预测中值为60%。这表明LLM模型更有可能在50%中点以上做出预测,群体的平均预测值M=57.35(SD=20.93)显著
高于50%,t(1006)=86.20,p<0.001
重要的是,整个问题集的解决方案接近平均,14/31的问题得到了正向解决,这种不平衡的现象表明,LLM预测通常倾向于正向的解决方案,超出了经验预期(只有45%以上的问题可以得到积极的解决方案)。
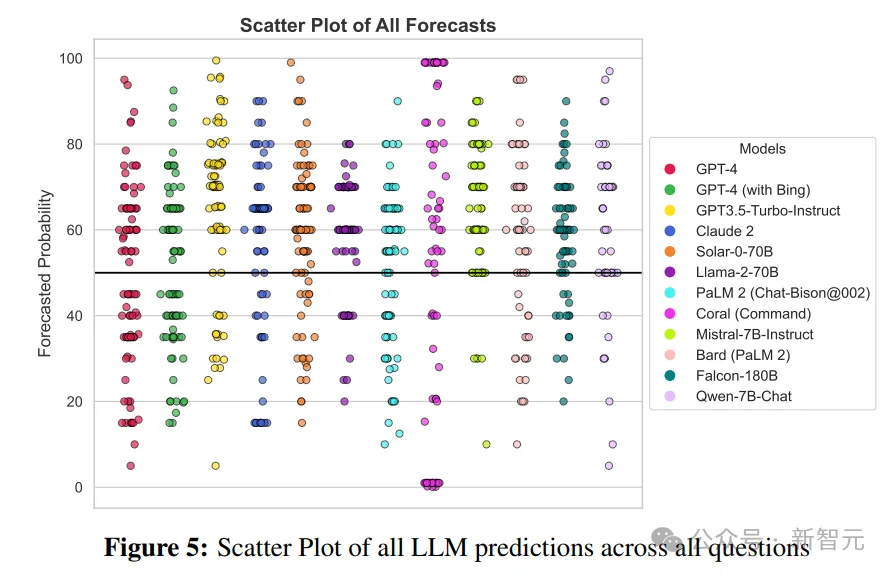
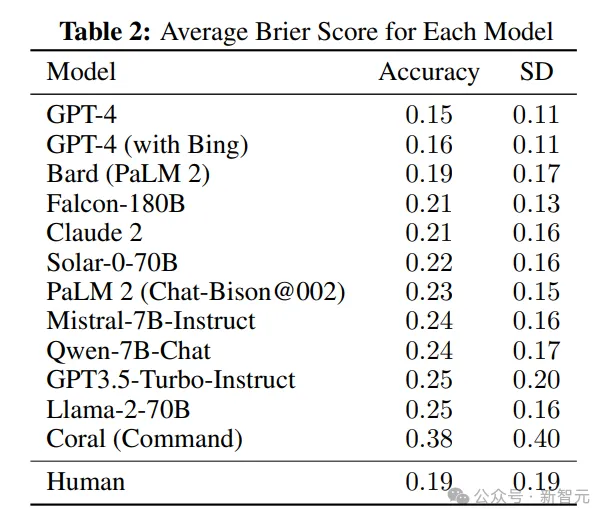
在该研究的问题集合中,LLM群体并不比人类群体更准确。
研究人员主要关注两个前沿模型,即GPT-4和Claude 2,使用与研究1中相同的真实世界预测锦标赛(real-world forecasting tournament)作为问题和人类预测的来源,分别通过OpenAI和Anthropic网站对GPT-
4和Claude 2进行查询。
针对模型内研究设计,研究人员为每个问题收集了两个预测(干预前和干预后),并在标准温度设置下重复提出三次,最后每个模型会得到六个预测结果。
最终目标是研究与人类认知输出相关的LLM更新行为,即LLM是否以及如何考虑预测锦标赛总量提供的人类预测估计。
与研究1相比,研究2使用了一组更长、更精细的提示:
第一个提示建立在「超级预测的10条戒律」以及关于预测和更新的文献基础上,指导模型仔细考虑区分不同程度的怀疑,在自信不足和过度自信之间取得正确的平衡,并将困难的问题分解为更容易解决的子问
题。

第二个提示,干预,告知模型相应人群的中值预测,并要求它在必要时更新,并概述更新的原因(如果有的话)。

对于这两个提示,研究人员收集的预测不是作为点估计,而是作为概率范围在0%和100%之间,估算到两个小数点。
提供给模型的群体中值是在社区预测被揭示的48小时内收集的,以允许人类预测者了解并相应地更新预测结果,通常会获得更好校准的预测;由于时差的原因,人类的预测比研究1中使用的预测更准确。
研究人员首先测试了暴露群体中值是否会提高模型的准确性。
对于GPT-4,暴露人类中位数前后的Brier得分存在统计学显著差异;对于Claude 2,可以发现暴露人类中位数前后的Brier得分存在具有统计学意义的差异,结果表明,以群体预测的形式提供人类认知可以提高
模型预测能力。
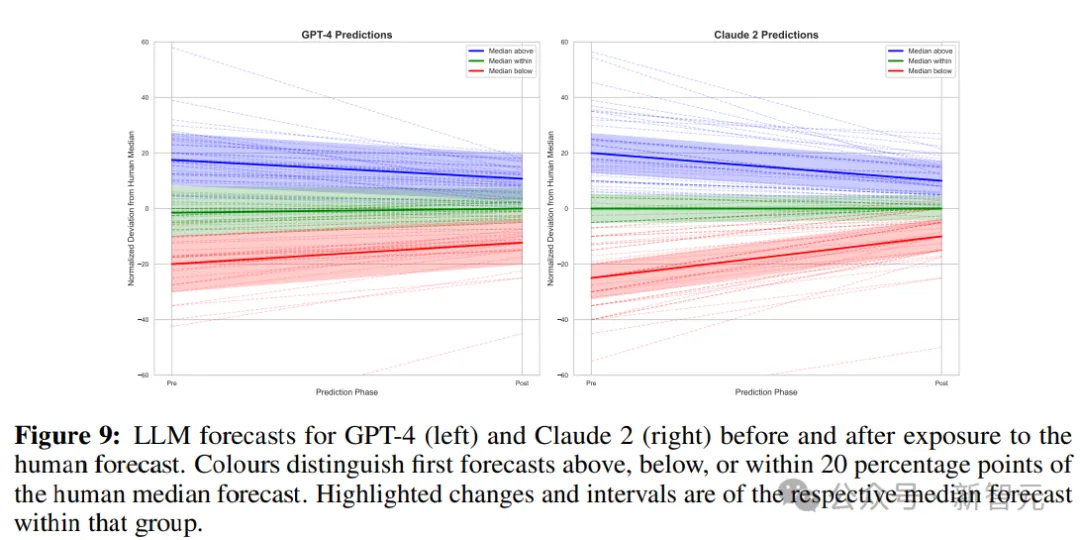
还可以发现,GPT-4的预测区间在暴露人类中位数后变得明显变窄,范围从平均区间大小17.75(SD:5.66)到14.22(SD:5.97),p<0.001;Claude 2的预测区间也显著变窄,从11.67(SD:4.201)缩小到
8.28(SD:3.63),p<0.001,结果表明,当人类预测包含在LLM中时,模型会降低了其预测的不确定性。
研究人员还分析了LLMs的更新是否与它们的点预测和人类基准之间的距离成比例,结果发现初始偏差与GPT-4预测调整幅度之间存在显著相关性,表明模型大致按照与人类的中位数之间的差异来移动预测。
文中进行的两项研究都是在「用于解决问题的答案不可能来自于训练数据」的情况下来测试LLM能力的,因为所有问题的答案在数据收集时都是未知的,甚至对作者来说也是如此,这也为LLM能力提供了一个
理想的评估标准。
实验结果以一种稳健的方式,为LLMs的高级推理能力提供了证据,因此传统基准可能提出的许多难题都不适用。
总之,这篇论文是首个表明当前LLMs能够提供关于未来现实世界事件的人类(达到群体水平的准确预测)的论文。
想要做到这一点,只用简单、实际适用的预测聚合方法就足够了:在所谓的硅环境中表现为LLM集合方法,复制了人类预测锦标赛对LLMs的「 群体智慧」效应,即「硅群体智慧」(Wisdom of the Silicon
Crowd)的现象。
实验结果的发现为进一步的研究和实际应用开辟了许多领域,因为LLM集成方法比从人群中收集数据要便宜得多,也快得多。
未来的研究可以旨在将集成方法与模型和支架进展相结合,这可能会在预测领域产生更强的能力增益。
参考资料:
https://arxiv.org/pdf/2402.19379.pdf
文章来自微信公众号“新智元”,作者:LRS




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
