# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
脑机接口最新进展登上Nature子刊,深度学习三巨头之一的LeCun都来转发。
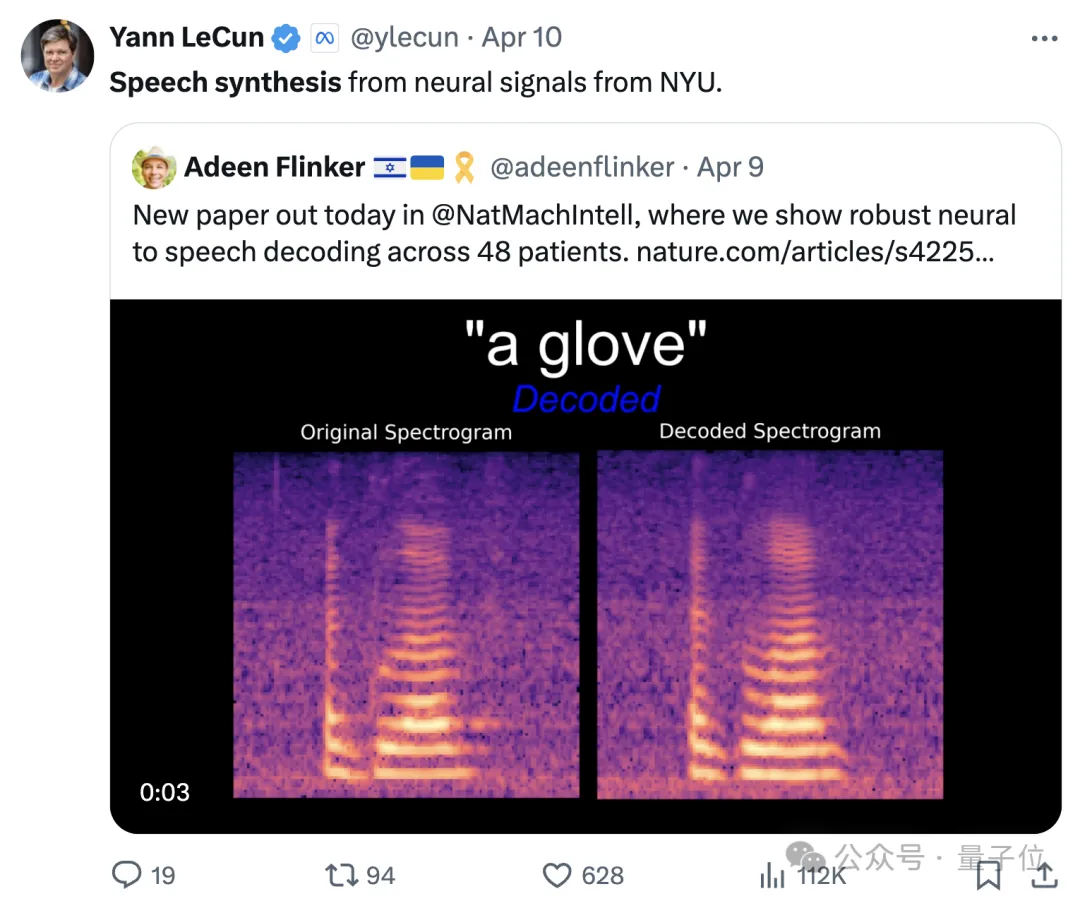
这次是用神经信号进行语音合成,帮助因神经系统缺陷导致失语的人群重新获得交流的能力。
具体来说,来自纽约大学的研究团队开发了一个新型的可微分语音合成器,可以利用一个轻型的卷积神经网络将语音编码为一系列可解释的语音参数(如音高,响度,共振峰频率等),并通过可微分语音合成器重新合成语音。
通过将神经信号映射到这些语音参数,研究者构建了一个高度可解释且可应用于小数据量情形的神经语音解码系统,可生成听起来自然的语音。
研究人员共收集了48位受试者的数据并尝试进行语音解码,对未来的高准确度的脑机接口应用提供了验证。
结果表明,该框架能够处理高低不同空间采样密度,并且可以处理左、右半球的脑电信号,显示出了强大的语音解码潜力。

此前,马斯克的Neuralink公司已经在一位受试者脑内成功植入电极,可以完成简单的光标操控以实现打字等功能。
然而,神经-语音解码通常被认为复杂度更高。
开发神经-语音解码器和其他的高精度脑机接口模型的尝试大多数依赖于一种特殊的数据:皮层电图(ECoG)记录的受试者数据,通常是从癫痫病人的治疗过程中收集。
利用患有癫痫的患者植入的电极,在发音时收集大脑皮层数据,这些数据具有高时空分辨率,已经在语音解码领域帮助研究者获得了一系列很显著的成果。
不过,神经信号的语音解码还面临着两大挑战。
早期的解码神经信号到语音的尝试主要依赖于线性模型,模型通常不需要庞大的训练数据集,可解释性强,但是准确率很低。
近期的基于深度神经网络,尤其是利用卷积和循环神经网络架构,在模拟语音的中间潜在表示和合成后语音质量两个关键维度上进行了很多的尝试。例如,有研究将大脑皮层活动解码成口型运动空间,然后再转化为语音,虽然解码性能强大,但重建的声音听起来不自然。
另一方面,一些方法通过利用wavenet声码器、生成对抗网络(GAN)等,虽然成功重建了自然听感的语音,但准确度有限。
最近一项发表在Nature的研究,在一个植入了设备的患者身上,通过使用量化的HuBERT特征作为中间表示空间和预训练的语音合成器将这些特征转换成语音,实现了既准确又自然的语音波形。
然而,HuBERT特征不能表示发音者特有的声学信息,只能生成固定统一的发音者声音,因此需要额外的模型将这种通用声音转换为特定患者的声音。此外,这项研究和大多数先前的尝试采用了非因果(non-causal)架构,这可能限制其在需要时序因果(causal)操作的脑机接口实际应用中的使用。
纽约大学Video Lab和Flinker Lab的研究团队介绍了一个新型的从脑电(ECoG)信号到语音的解码框架,构建了一个低维度的中间表示(low dimension latent representation),该表示通过仅使用语音信号的语音编解码模型生成。
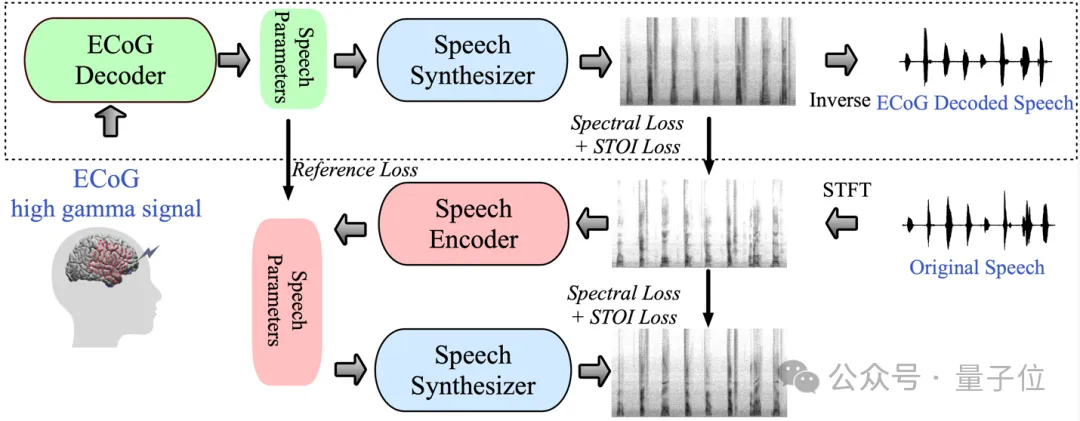
具体来说,框架由两部分组成:
一部分是ECoG解码器,它能将ECoG信号转化为我们可以理解的声学语音参数(比如音高、是否发声、响度、以及共振峰频率等);
另一部分是语音合成器,它将这些语音参数转化为频谱图。
研究人员构建了一个可微分语音合成器,这使得在训练ECoG解码器的过程中,语音合成器也可以参与训练,共同优化以减少频谱图重建的误差。
这个低维度的潜在空间具有很强的可解释性,加上轻量级的预训练语音编码器生成参考用的语音参数,帮助研究者构建了一个高效的神经语音解码框架,克服了神经语音解码领域数据非常稀缺的问题。
该框架能产生非常接近说话人自己声音的自然语音,并且ECoG解码器部分可以插入不同的深度学习模型架构,也支持因果操作(causal operations)。
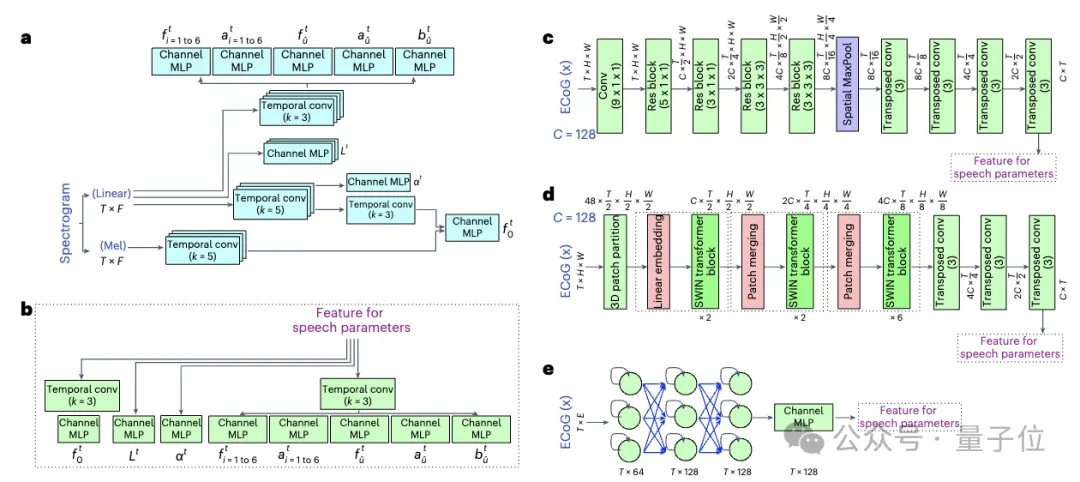
研究人员共收集并处理了48名神经外科病人的ECoG数据,使用多种深度学习架构(包括卷积、循环神经网络和Transformer)作为ECoG解码器。
该框架在各种模型上都展现出了高准确度,其中以卷积(ResNet)架构获得的性能最好。本文研究人员提出的框架仅通过因果操作和相对较低的采样率(low-density, 10mm spacing)就能实现高准确度。
他们还展示了能够从大脑的左右半球都进行有效的语音解码,将神经语音解码的应用扩展到了右脑。
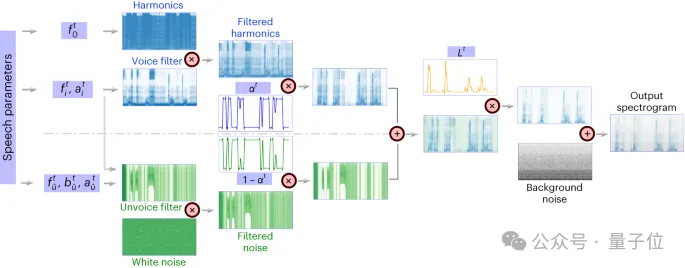
可微分语音合成器(speech synthesizer),使得语音的重合成任务变得非常高效,可以用很小的语音合成高保真的贴合原声的音频。
可微分语音合成器的原理借鉴了人的发生系统原理,将语音分为Voice(用于建模元音)和Unvoice(用于建模辅音)两部分。
Voice部分可以首先用基频信号产生谐波,由F1-F6的共振峰组成的滤波器滤波得到元音部分的频谱特征。
对于Unvoice部分,研究人员则是将白噪声用相应的滤波器滤波得到对应的频谱,一个可学习的参数可以调控两部分在每个时刻的混合比例,在此之后通过响度信号放大,加入背景噪声来得到最终的语音频谱。
一、具有时序因果性的语音解码结果
首先,研究人员直接比较不同模型架构卷积(ResNet)、循环(LSTM)和Transformer(3D Swin)在语音解码性能上的差异。
值得注意的是,这些模型都可以执行时间上的非因果(non-causal)或因果操作。
解码模型的因果性对大脑-计算机接口(BCI)应用具有重大意义:因果模型仅利用过去和当前的神经信号生成语音,而非因果模型还会使用未来的神经信号,这在实时应用中不可行。
因此,他们专注于比较相同模型在执行非因果和因果操作时的性能。
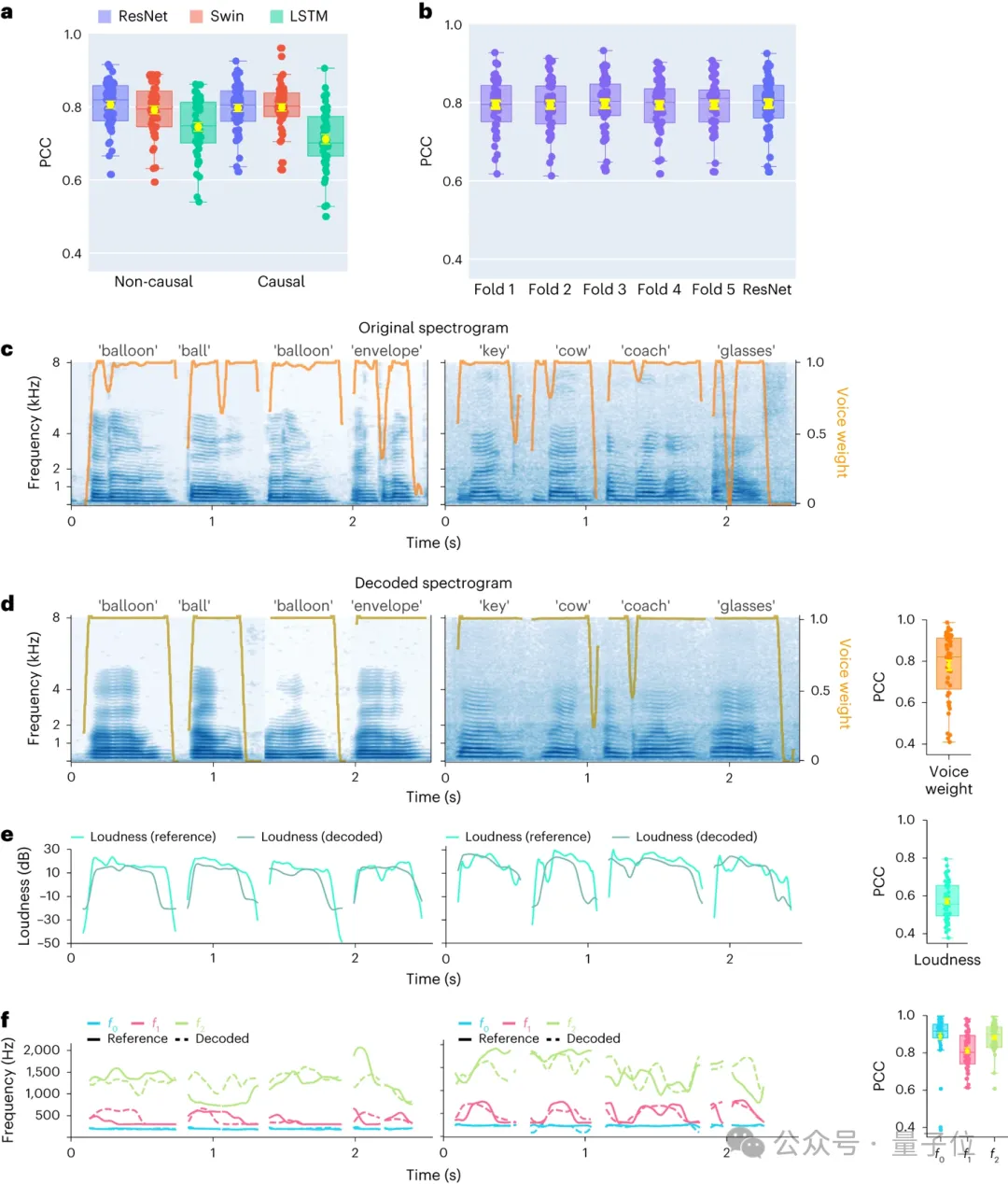
结果发现,即使是因果版本的ResNet模型也能与非因果版本媲美,二者之间没有显著差异。同样,因果和非因果版本的Swin模型性能相近,但因果版本的LSTM模型性能显著低于非因果版本。
研究人员展示了几个关键语音参数的平均解码准确率(N=48),包括声音权重(用于区分元音和辅音)、响度、音高f0、第一共振峰f1和第二共振峰f2。准确重建这些语音参数,尤其是音高、声音权重和前两个共振峰,对于实现精确的语音解码和自然地模仿参与者声音的重建至关重要。
结果表明,无论是非因果还是因果模型,都能得到合理的解码结果,这为未来的研究和应用提供了积极的指引。
二、对左右大脑神经信号语音解码以及空间采样率的研究
研究人员进一步对左右大脑半球的语音解码结果进行了比较。多数研究集中关注主导语音和语言功能的左脑半球,而对从右脑半球解码语言信息的关注较少。
针对这一点,他们比较了参与者左右大脑半球的解码表现,以此验证使用右脑半球进行语音恢复的可能性。
在研究收集的48位受试者中,有16位受试者的ECoG信号采集自右脑。
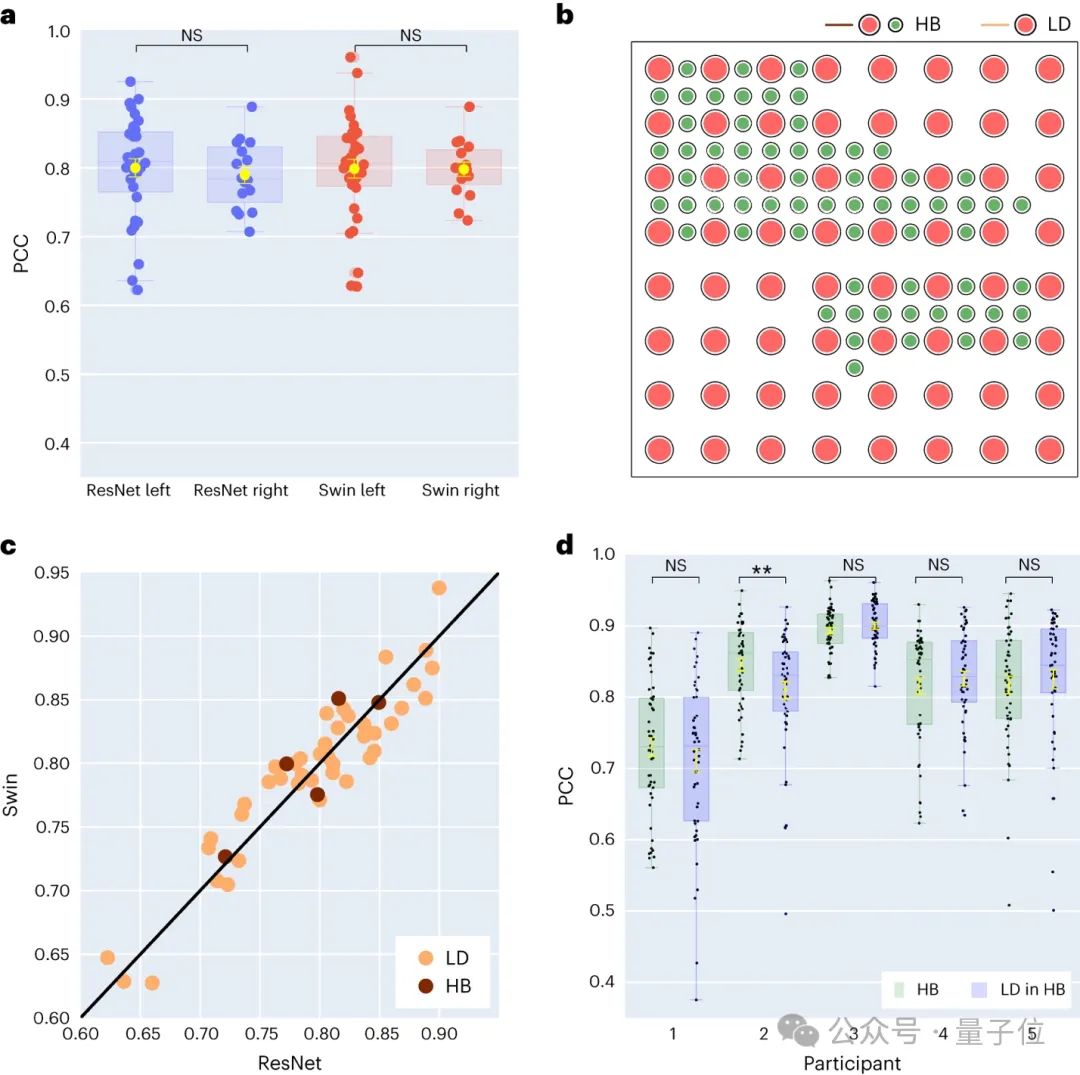
通过对比 ResNet 和 Swin 解码器的表现,发现右脑半球也能够稳定地进行语音解码,与左脑半球的解码效果相差较小。
这意味着,对于左脑半球受损、失去语言能力的患者来说,利用右脑半球的神经信号恢复语言也许是一个可行的方案。
接着,他们还探讨了电极采样密度对语音解码效果的影响。
之前的研究多采用较高密度的电极网格(0.4 mm),而临床中通常使用的电极网格密度较低(LD 1 cm)。有五位参与者使用了混合类型(HB)的电极网格,这类网格虽然主要是低密度采样,但其中加入了额外的电极。剩余的四十三位参与者都采用低密度采样。这些混合采样(HB)的解码表现与传统的低密度采样(LD)相似。
这表明模型能够从不同空间采样密度的大脑皮层中学习到语音信息,这也暗示临床通常使用的采样密度对于未来的脑机接口应用也许是足够的。
三、对于左右脑不同脑区对语音解码贡献度的研究
研究人员也考察了大脑的语音相关区域在语音解码过程中的贡献程度,这对于未来在左右脑半球植入语音恢复设备提供了重要的参考。
采用了遮挡技术(occlusion analysis)来评估不同大脑区域对语音解码的贡献度。
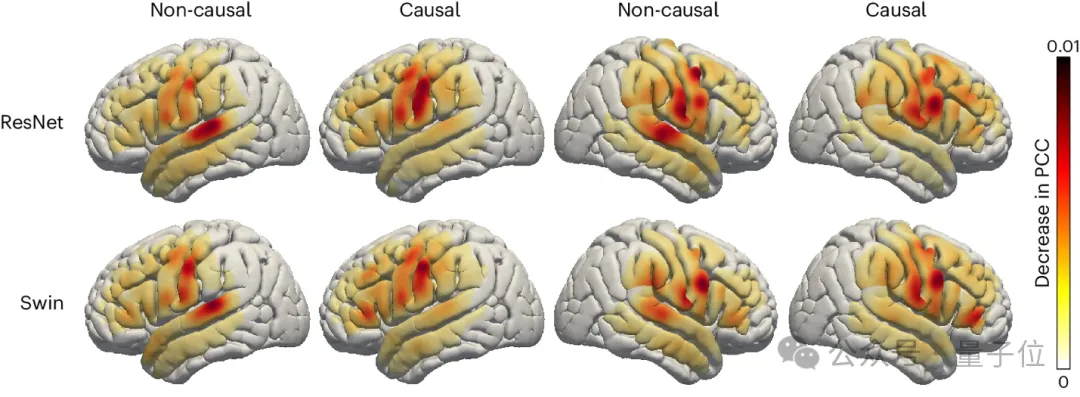
通过对比 ResNet 和 Swin 解码器的因果与非因果模型,发现听觉皮层在非因果模型中的贡献更大,这侧面佐证了在实时语音解码应用中,必须使用因果模型,因为在实时语音解码中,我们无法利用神经反馈信号。
此外,无论是在右脑还是左脑半球,传感运动皮层尤其是腹部区域的贡献度相似,这暗示在右半球植入神经假肢也许是一个可行的方案。
最后总结来说,该研究在脑机接口上面取得了一系列的进展,不过研究人员也提到了目前模型的一些限制,比如解码流程需要有与ECoG记录配对的语音训练数据,这对失语患者可能不适用。
未来他们希望开发能处理非网格数据的模型架构,以及更好地利用多病人、多模态脑电数据。
本文来自微信公众号“QbitAI”,作者 量子位



【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
