# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
对于小型语言模型(SLM)来说,数学应用题求解是一项很复杂的任务。
比如之前有研究结果显示,在GSM 8K基准测试中实现80%以上准确度所需的最小模型尺寸为340亿个参数。
为了在较小的模型上达到这种性能水平,研究人员经常训练SLM来生成Python代码或使用外部工具作为辅助,以避免计算错误。
或是基于集成(ensembling)技术,将100多个模型生成的输出组合在一起,以获得更准确的结果,最终结果的选择需要通过共识、多数表决或与SLM结合使用的单独的验证器模型来完成,可以显著提升准确率(Phi-GSM使用top-48将性能从68.2提升到81.5),不过代价是由于多次调用模型导致的成本显著增加。
最近,微软的研究人员提出了一个基于Mistral-7B、70亿参数量的小型语言模型Orca-Math,它在GSM 8 k上实现了86.81%,不需要调用多个模型进行集成或使用验证器、代码执行或任何其他外部工具。

Orca-Math的关键特性为:
1. 使用多个智能体(agent)创建出20万个数学问题的高质量合成数据集,其中智能体合作创建数据;
2. 迭代学习技术,使SLM能够练习解决问题,接收对其解决方案的反馈,并从包含SLM解决方案和反馈的偏好数据中学习。
当单独使用有监督微调训练时,Orca-Math在GSM 8 k pass@1指标上达到81.50%。通过迭代偏好学习,Orca-Math实现了86.81%的pass@1
Orca-Math超越了LLAMA-2- 70B,WizardMath-70B,Gemini-Pro,ChatGPT-3.5等更大型号的性能,在使用小得多的数据(数十万对数百万问题)时也显著优于其他较小的模型。
种子集合
首先从现有的开源数据集中收集数学单词问题样本,即NumGLUE、AddSub、ALGES、ASDiv、DRAW、GSM8k、MATHQA、MultiArith、SingeOP、SingleEQ和SVAMP。
研究人员从Lila的训练和验证分裂中收集问题,以构建种子集,总共收集了36217个问题。
智能体 - ask me anything
通过从种子集中的问题创建多个单词问题来扩展种子集,利用后续提示来创建问题。

智能体总共生成了120445个新问题,但所有生成的问题都表现出与种子词问题相似的叙述方式,具体解决方案是使用GPT4-Trubo生成的。
智能体 - Suggester & Editor
通过解决具有挑战性的问题进一步扩大种子集合。
为了实现这一点,研究人员引入了两个新的智能体,即Suggester和Editor,可以协同工作以创建一个面向预定义目标的数据集:修改现有问题以增加其难度。
Suggester研究一个特定的问题,并提出了几种在不产生实际问题的情况下提高其复杂性的方法。
Editor采用原始单词问题和Suggester的建议,生成一个更新的、更具挑战性的问题,迭代过程可以发生在多个回合中,每一回合都会进一步增加先前生成的问题的复杂性。
眼人员利用AutoGen框架来实现多智能体工作流。

对每个问题进行两轮迭代,并过滤GPT4-Turbo生成的答案超过1800个字符的问题,最终收集了37157个问题。
有监督微调实验(第一次迭代)
在Orca-Math-200K数据集上对Mistral-7B进行了微调,没有使用packing,下面为具体的指令格式。

损失函数只基于答案token来计算。
正负信号的迭代学习
数据集构建(第二次迭代)
为了为每个问题生成额外的正样本和负样本,研究人员从第一次迭代的SFT调优模型中采样四个回复。
具体来说,使用top_p=0.95和温度=0.7,过程产生了一个数据集,其中200000个问题中的每个问题都有一个GPT4-Turbo生成的解决方案和四个学生生成的解决方法。
使用基于GPT4的精确匹配中定义的提示来评估教师(GPT4-Turbo)的答案和学生的答案之间的一致性。
对于学生生成的答案与老师的答案不匹配的所有解决方案,将其标记为负样本。
数据集构建(第三次迭代)
为了从正反馈和负反馈中学习,研究人员评估了两种算法的性能:直接偏好优化(DPO)和Kahneman-Tversky优化(KTO),还探索了KTO的功能,其区别在于只需要二进制「是」或「否」的回复来评估输出的质量。
研究人员使用精确匹配作为评估指标。
给定一个模型生成的答案,提示GPT-4来提取最终的简短答案,并将其与金标准中的简短答案进行匹配,即基于GPT4的精确匹配(GPT4-based-Exact-Match)。

研究人员测试了模型在包含1319个单词问题的GSM8k测试集上几个训练过程的性能,对Mistral-7B模型进行了三次迭代的微调

在第一次迭代中,使用有监督微调来获得M1;
第二次迭代中,对比了SFT、DPO和KTO,其中KTO训练的模型在这一组中表现更好,获得M2后,并使用M2生成迭代#3的数据集;
第三次迭代中,对比了DPO和KTO方法,使用M2作为模型起点。
研究人员还将这些模型与Orca-Math-200K数据集上经过三个epoch的SFT训练进行了对比。
Model Generated Positives
通过将限制为仅包含教师生成的解决方案来研究影响模型生成的正向因素(positives),换言之,研究人员移除在为迭代#2创建数据集时模型生成的所有

结果显示,不管训练算法如何,都会看到显著的性能下降。
Synthetic Negatives
数据集的创建包括在M1或M2生成的所有四个回复都是positive的情况下的合成负样本(negative creation)。

通过忽略问题qi来研究这些合成负样本的影响,结果将第二次迭代的问题数量减少了约80k,将第三次迭代的问题数量增加了约104k
研究人员还使用Orca Math其他几个单词问题数据集上进行了实验,并且为了便于评估,最终选择了问题答案都是单个数字的数据集。
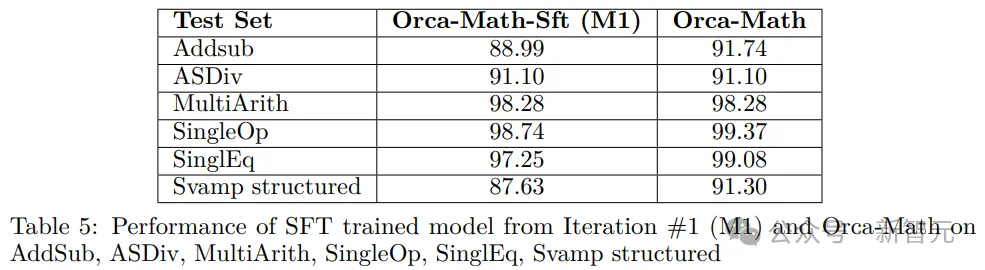
评估指标为基于GPT4的精确匹配度量,并使用贪婪解码生成模型回复。
沾染检查(Contamination Check)
为了确保实验的公正性,研究人员在文中表示:在训练过程中,从未使用GSM8K或任何其他数据集的测试分割集,也从未将其用作合成问题生成的种子。
尽管如此,研究人员还是采用以下方法来检测任何潜在的文本沾染(text contamination)问题:
1. 对文本进行预处理,包括将所有字符转换为小写、删除标点符号、对文本进行分词,以及删除常见的英语停止词,以确保数据的一致性。
2. 使用逆文档频率(TF-IDF)方法对文本语料库进行矢量化,并确定测试集和训练集之间的余弦相似性,从中为每个测试查询选择前k个(k=10)最相似的问题。
3. 通过计算在预设阈值0.5以上具有最高n-gram重叠的试题数量及其相应的训练集匹配来评估文本污染的程度。
研究人员使用Jaccard相似度来计算文本对之间的n-gram重叠,并且为了进行严格的污染检查,n设置为1。
需要注意的是,当使用Jaccard相似性测量时,n-gram重叠是n的非递增函数。
4. 在执行算法时,确定表现出显著的n-gram重叠的试题数量为8,因此根据定义的阈值,表明测试集中的文本污染可以忽略不计。
当将训练集限制为仅包含种子问题时,表现出显著n-gram重叠的测试问题的数量为7;并且在n≥2的情况下,表现出显著的n-gram重叠的试题数为零。
本文来自微信公众号”新智元“




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
