# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视制作,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。
MoMask 框架是基于多层离散化动作表示的,利用生成式掩码技术,能够生成更高质量的 3D 人体动作。如视频 1 中展示,MoMask 可以根据文本描述,精细控制生成的动作内容。在 HumanML3D 数据集上,MoMask 的生成质量可达到 FID 为 0.045,超过了现有的最优工作如 T2M-GPT(0.141)和 ReMoDiffuse(0.103)。这项研究成果已被 CVPR 2024 收录,并且其代码和模型已在 GitHub 上开源,拥有 500 + 星标。

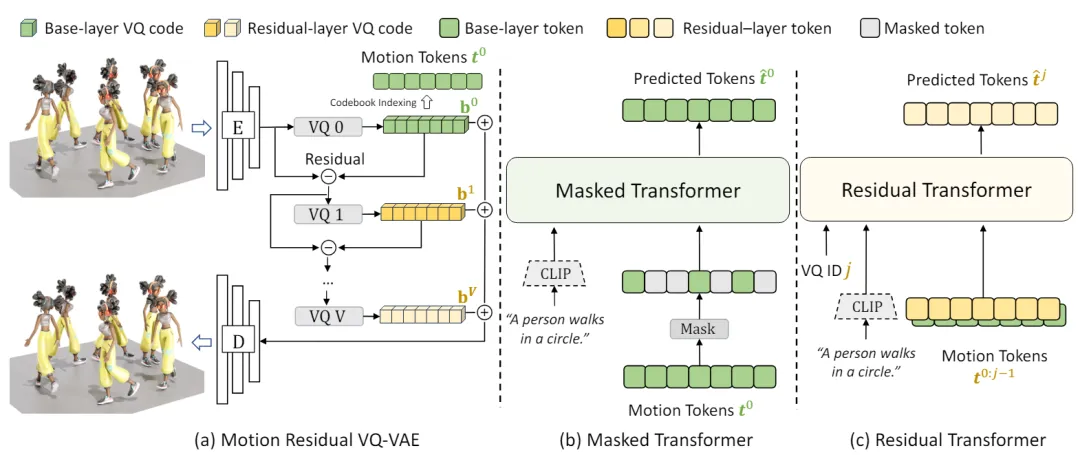
MoMask 框架主要包含三个关键的神经网络模块:
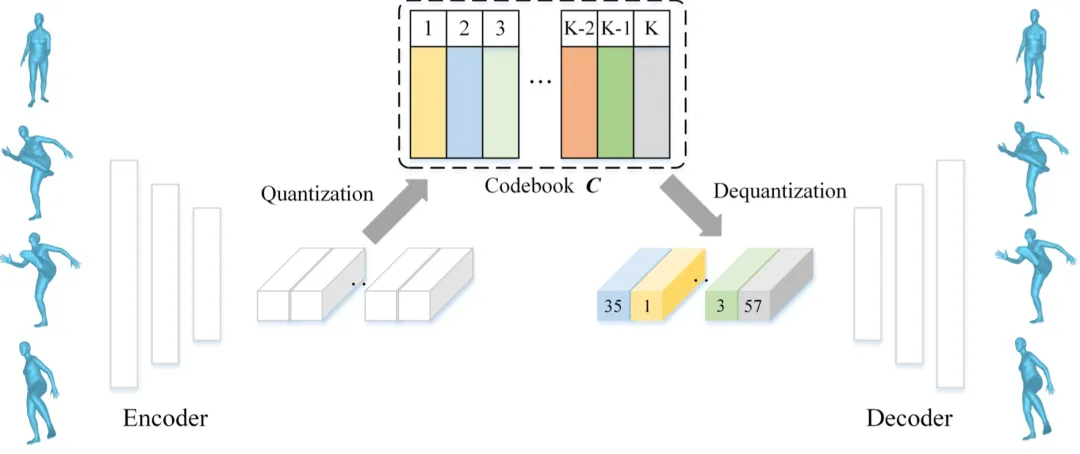
动作序列离散化。MoMask 采用基于离散表达的生成式框架,首先将连续的动作表达进行离散化。如图 3,传统的 VQ-VAE 在量化(Quantization)过程中存在信息损失问题,因为它将每个隐向量替换为码书(Codebook)中最相近的码向量,这两个向量之间的差异导致了信息的丢失。为了解决这个问题,MoMask 采用了多层量化的方法(图 2.a),逐层对隐向量和码向量之间的残差进一步量化,从而提高了隐向量的估计精度。随着层数加深,每一层所建模的信息量(即残差)也逐步减少。训练时,为了尽可能增加每一个量化层的容量,我们随机丢弃掉末尾的若干个残差层。最终,动作序列被转化为多层的离散动作标记,其中基层标记包含了动作的主要内容,而残差层则用于填补动作的细节。接下来,MoMask 使用 Masked Transformer 生成基层动作标记,并使用 Residual Transformer 逐层预测残差层的动作标记。
生成式掩码建模。如图 2.b,文本描述首先通过 CLIP 编码成语义向量,同时基层的动作标记序列被随机掩码。然后,这些掩码的动作标记序列和 CLIP 文本向量一起输入到 Transformer 中进行训练,其目标是准确预测被掩码掉的动作标记。与以往基于掩码的预训练模型不同的是,这里掩码标记的比例是随机的,并且可以在 0 到 1 的区间取值,这意味着掩码的程度也是随机的。最坏情况下,所有标记都被掩码,而最好情况下,所有标记都被保留。
残差层标记预测。由于残差层包含了更细粒度的动作信息,因此根据前面 j > 1 层的动作标记内容,可以基本确定第 j 层的动作标记。在训练时,随机选择一个残差层 j 进行预测,将已知的前 j 层的动作标记、CLIP 文本向量以及第 j 层的编码输入到 Transformer 中,使用交叉熵损失函数来优化模型。
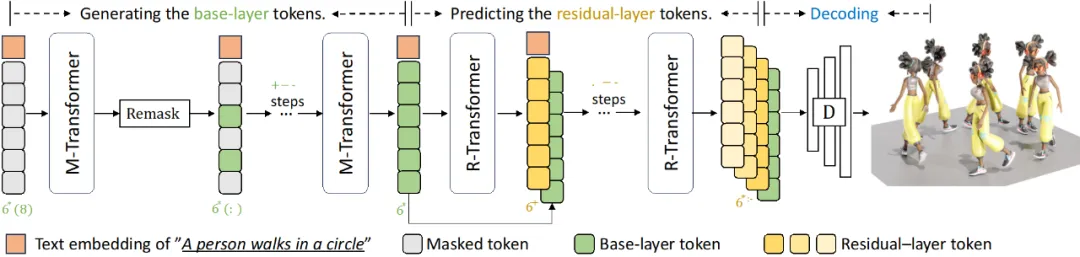
生成过程。图 4 描述了 MoMask 框架中的生成过程。从基层的动作标记序列开始,所有的动作标记都被掩码,然后通过 Masked Transformer 进行预测,得到完整的标记序列。接着,仅置信度最高的一部分标记被保留,剩下的标记将被重新掩码(Remask),并重新预测。通过一个预设的调度函数 (Schedule function),在经过一定次数的掩码与预测后,得到最终的基层动作标记序列。然后,Residual Transformer 根据基层的标记序列,逐层地预测残差层的标记序列。最终,所有标记序列被输入到 RVQ-VAE 的解码器中,并解码获得对应的动作序列。因此,无论动作序列的长度为多少,MoMask 只需要固定步数去生成该序列。通常情况下,MoMask 仅需要进行不超过 20 步的迭代,包括基础与残差层的生成。
在视频 2 中,MoMask 与其他三个基线方法进行了对比,包括主流的扩散模型(MDM、MLD)和 GPT 模型(T2M-GPT)。MoMask 在应对挑战性动作(如绊脚和抱脚)以及更精细的文本控制方面表现更出色。
在下表中,我们对 MoMask 在 HumanML3D 和 KIT-ML 数据集上的性能进行了更全面的分析。可以看出,MoMask 框架在 R-Precision 和 FID 等指标上始终表现最优,在 HumanML3D 数据集上,生成质量达到了 FID 为 0.045。
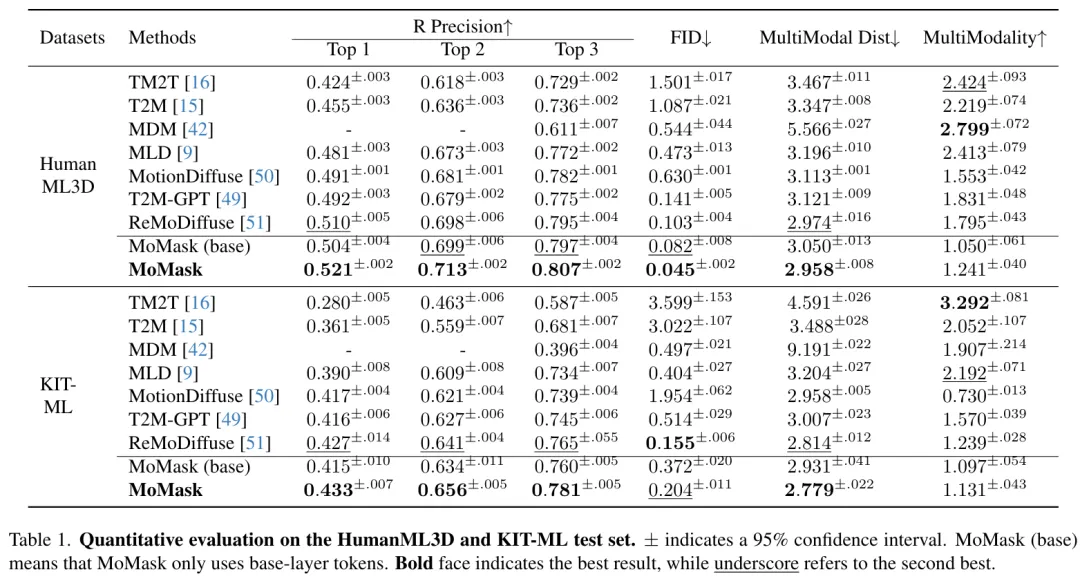
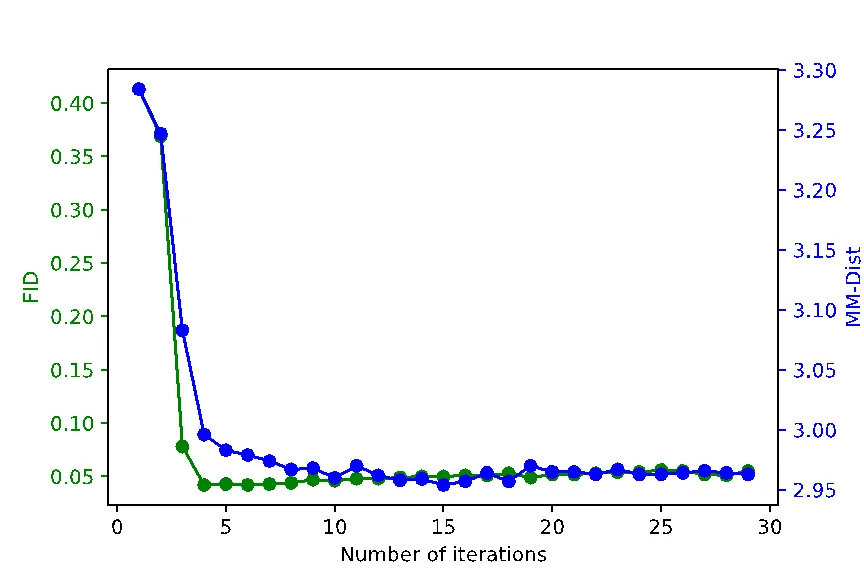
图 5 展示了 Masked Transformer 推断步数对生成动作的整体质量影响,其中 FID 和 MM-Dist 分别指示了动作生成质量以及动作与文本内容的匹配程度,值越低代表性能越好。从图中可以看出,仅需要进行 10 步推断,生成质量就可以收敛到最优水平。
MoMask 还可用于动作序列的时序补齐,即根据文本对动作序列指定的区间进行编辑或修改。在视频 3 中,展示了基于 MoMask 对动作序列的前缀、中间部分和后缀,根据给定的文本进行内容补齐。
本文来自微信公众号”机器之心“



【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
