# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当地时间5月7日,ICLR 2024颁发了自大会举办以来的首个「时间检验奖」!

荣获该奖的是由Diederik Kingma与Max Welling合著的经典论文「Auto-Encoding Variational Bayes」。
众所周知,概率建模是我们理解世界的基础方法之一。
这篇论文成功地将深度学习与可扩展的概率推断结合起来,特别是通过一种称为「重新参数化技巧」的方法实现了均值场变分推断,从而创造了变分自编码器(VAE)。
这项工作之所以具有长远的价值,不仅因为其方法上的优雅,还因为它深化了我们对深度学习和概率建模相互作用的理解,并促进了许多后续概率模型和编码策略的发展。

Max Welling教授目前担任阿姆斯特丹大学的机器学习研究主席,并在微软研究院担任杰出科学家。
他同时是加拿大先进研究所(CIFAR)和欧洲学习与智能系统实验室(ELLIS)的研究员,并在ELLIS的创始董事会中任职。

他的过往职务包括在高通科技担任副总裁、在加州大学欧文分校担任教授等等。
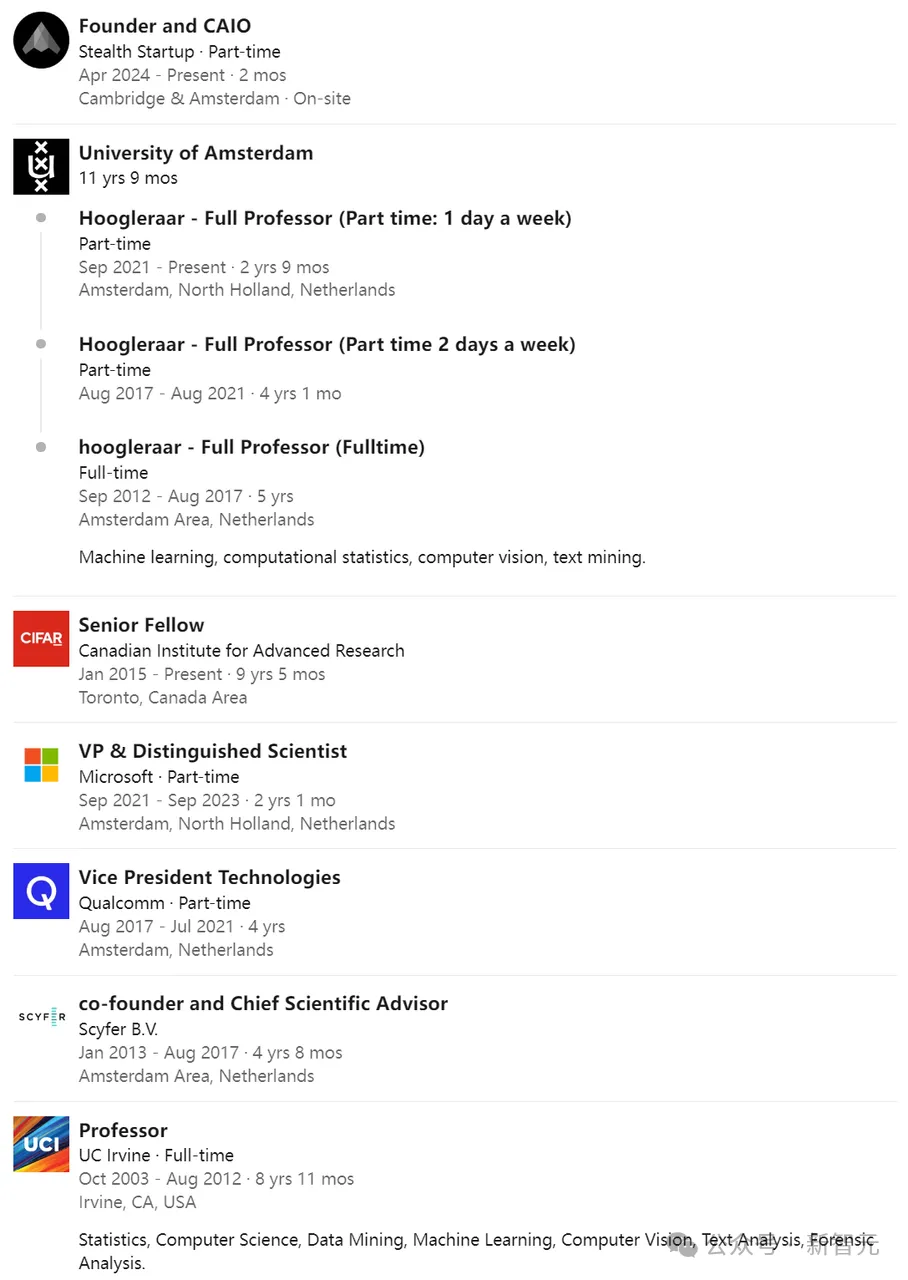
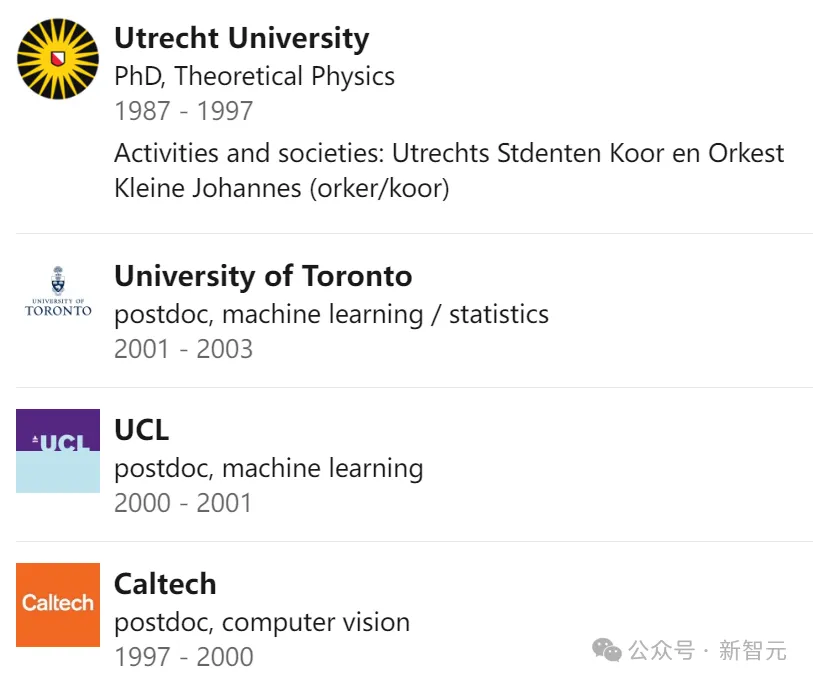
他曾在多伦多大学和伦敦大学学院从事博士后研究,师从Geoffrey Hinton教授,并且还在加州理工学院从事过博士后研究,师从Pietro Perona教授。
再之前,他则在诺贝尔奖得主Gerard ‘t Hooft教授的指导下完成了理论高能物理学博士学位。
在阿姆斯特丹大学获得机器学习博士学位后,Diederik Kingma先去OpenAI干了两年,随后又在2018年跳到了DeepMind,至今已经5年有余。

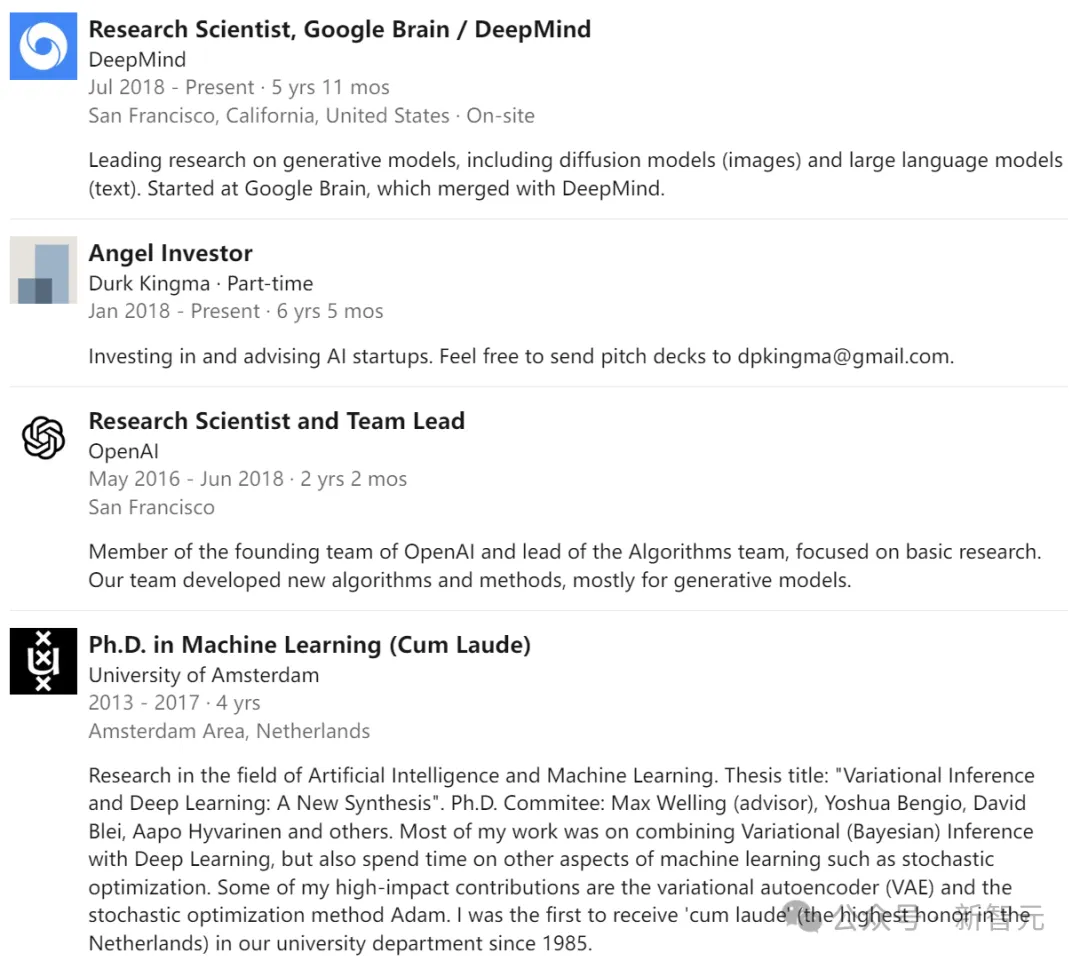
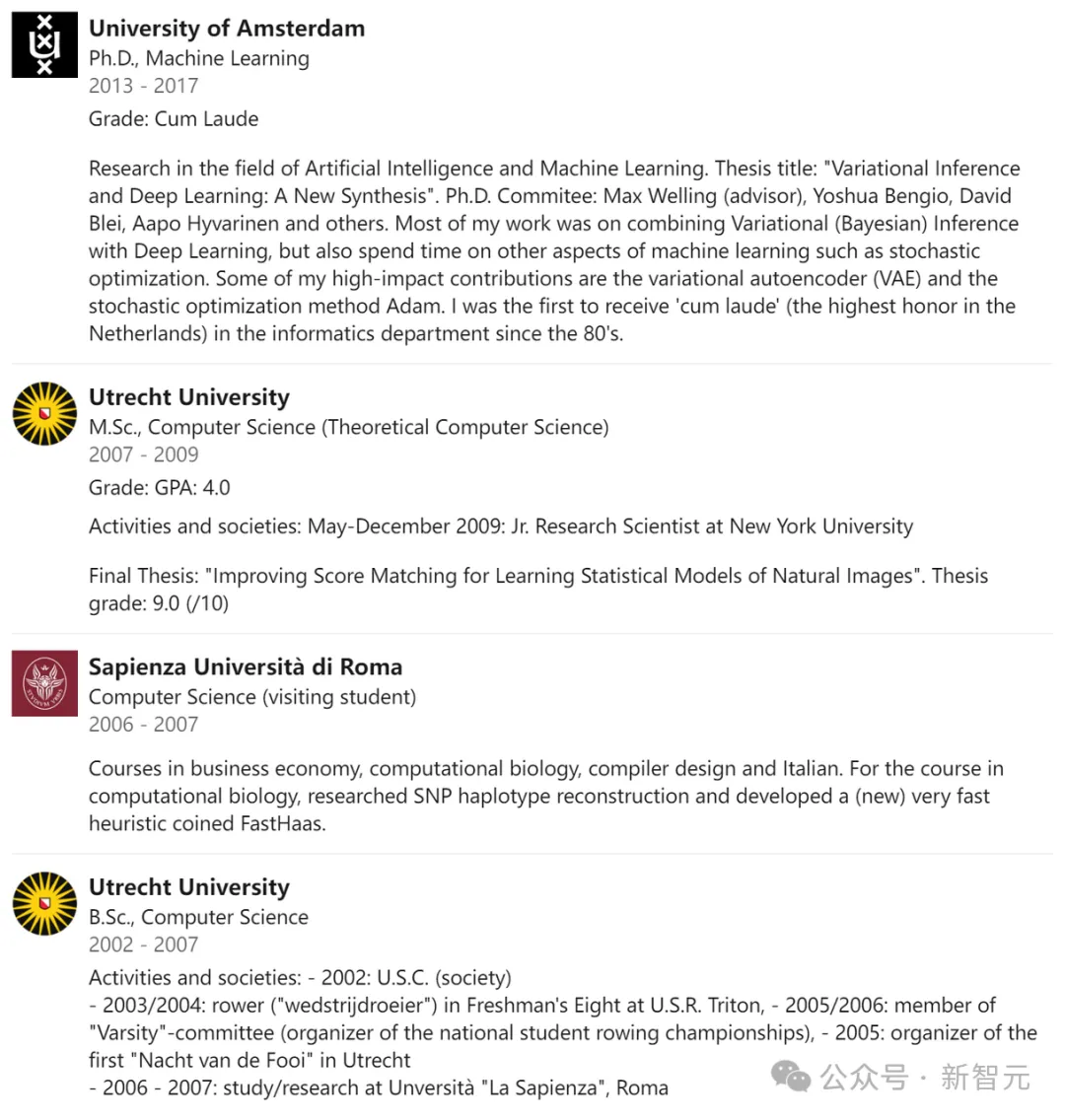
读博期间,他的指导教授正是Max Welling,其他成员包括Yoshua Bengio、David Blei、Aapo Hyvarinen等。
他的研究方向主要是将变分(贝叶斯)推断与深度学习的结合,同时也涉猎机器学习的其他领域,如随机优化。其中,变分自编码器(VAE)和随机优化方法Adam是具有重大影响的成果。
接下来,是获得第二名的论文「Intriguing properties of neural networks」。
随着深度神经网络在实际应用中的广泛使用,理解它们何时可能表现出不良行为变得尤为重要。
这篇论文指出了一个关键问题:神经网络对于输入的微小且几乎不可察觉的变动非常敏感。
而这一发现也开启了对抗性攻击(尝试欺骗神经网络)和对抗性防御(训练神经网络以抵抗欺骗)研究领域的发展。

论文地址:https://arxiv.org/abs/1312.6114
不得不说,这篇文章的作者阵容可谓是相当豪华:Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fergus。
没错,这段时间行踪最为神秘的Ilya Sutskever也在其中。
如今这些人所在的机构也和当时大不相同了:Christian Szegedy目前在马斯克的xAI;Wojciech Zaremba和Ilya Sutskever后来都成为了OpenAI的联合创始人;Joan Bruna依然在纽约大学不过身份已经变成了副教授;Dumitru Erhan则一直留在谷歌,目前是Google Deepmind的研究总监;Ian Goodfellow目前也在Google Deepmind做研究科学家;Rob Fergus除了还是纽约大学的教授之外,也跳到了Google Deepmind做研究科学家。
ICLR 2024
成立于2013年的ICLR全称为国际学习表征会议(International Coference on Learning Representations),由两位图灵奖获得者Yoshua Bengio和Yann LeCun牵头举办,今年已经来到了第十二届。
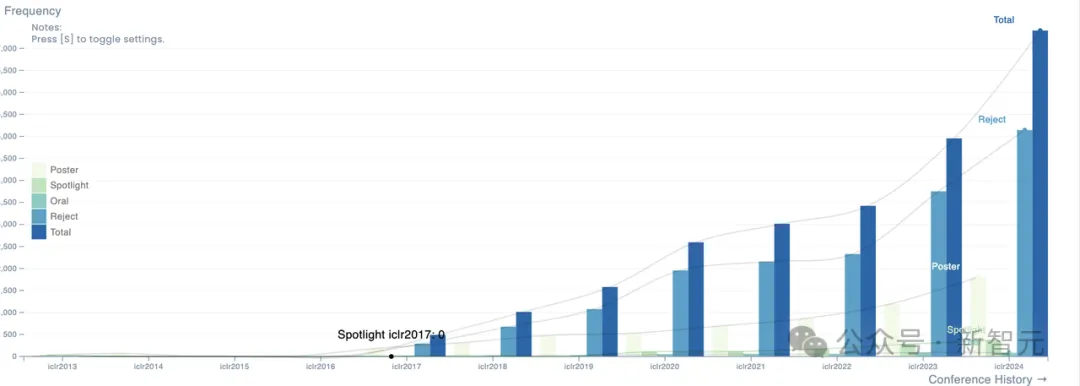
作为「年轻」的学术顶会,ICLR近年来的论文接收量持续攀升,很快获得了学界的广泛认可。

本届ICLR于1月放榜,整体接收率约为31%,基本与去年持平,但接收的论文总数为7262篇,相比2023年的4955篇有大幅提升。
5月6日,ICLR公布了2024年度的杰出论文奖项,共评选出了5篇杰出论文与11篇荣誉提名论文。

作者:Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, Stéphane Mallat

这篇论文深入分析了图像扩散模型在泛化和记忆方面的关键特性。
作者通过实际测试探究了图像生成模型从简单记忆转向泛化处理的关键时刻,并利用「几何适应性谐波表示」与和声分析的理念,对这一转变提供了清晰的解释。
这项研究解决了我们对视觉生成模型理解的一个重要缺口,预计将推动该领域未来的理论研究。
题目:Learning Interactive Real-World Simulators
作者:Sherry Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, Pieter Abbeel

聚合多个来源的数据来训练机器人基础模型是一个长远且雄心勃勃的目标。由于不同机器人拥有不同的感觉-运动接口,这在大规模数据集上的训练面临重大挑战。
UniSim在这方面取得了重要进展——它通过一个统一的接口,结合视觉感知和控制的文本描述来聚合数据,并借助视觉与语言领域的最新技术进展,从这些数据中训练出一个机器人模拟器。
对此,英伟达高级研究科学家Jim Fan表示:UniSim当之无愧是ICLR的杰出论文。
Sora从大量视频数据中学习物理模拟器,而无需动作信息。UniSim则学习了一个带有动作的物理模拟器,它可以通过主动干预来影响未来的视频帧。
几个月后,DeepMind Genie进一步发展了这一概念,它能从自然环境下的视频中推断出潜在的动作,这开辟了一条无需明确动作标注就能实现大规模学习的新途径。

题目:Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
作者:Ido Amos, Jonathan Berant, Ankit Gupta

这篇论文深入分析了最新提出的状态空间模型和Transformer架构在处理长期序列依赖性方面的效果。
研究发现,直接从零开始训练Transformer模型可能会低估其真实潜力,而采用预训练加上后续的微调则能显著提高模型性能。
文章的研究方法严谨,特别强调了简洁性和系统性见解,是该领域的一个优秀范例。
题目:Protein Discovery with Discrete Walk-Jump Sampling
作者:Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi

论文地址:https://openreview.net/forum?id=zMPHKOmQNb
这篇论文针对蛋白质序列生成模型在抗体设计中的应用,提出了一个及时且重要的解决方案
作者开发了一种新的建模方法,专为处理离散蛋白质序列数据设计,具有创新性和有效性。除了通过计算机模拟验证这一方法外,作者还进行了一系列湿实验,通过体外实验测定抗体的结合亲和力,证实了生成模型的实际效果。
题目:Vision Transformers Need Registers
作者:Timothée Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski

这篇论文在分析视觉Transformer网络时,发现了特征图中由于背景区域信息低而产生的高范数Token所引起的伪影。
作者不仅提出了一些关键性的假设解释这一现象,还设计了一个简洁而精巧的方法,通过引入额外的注册Token来消除这些伪影,显著提升了模型在多种任务上的表现。而且,这项研究的发现还可能对其他应用领域产生影响。
此外,这篇文章的结构严谨,通过识别问题、分析原因及提出解决方案,展示了科研工作的典范。
题目:Amortizing intractable inference in large language models
作者:Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, Nikolay Malkin

这篇论文表达非常清晰,有效地推动了高效且可扩展的纳什求解器开发这一重要问题的研究进展。
题目:Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
作者:Bohang Zhang, Jingchu Gai, Yiheng Du, Qiwei Ye, Di He, Liwei Wang

图神经网络(GNN)的表达性是一个关键的研究领域。然而目前的方法,如Weisfeiler-Lehman测试,却存在不少限制。对此,作者基于同态计数提出了一种新的「表达性理论」。
题目:Flow Matching on General Geometries
作者:Ricky T. Q. Chen, Yaron Lipman

这篇论文解决了在一般几何流形上进行生成建模这一复杂问题,并提出了一个既实用又高效的算法。文章结构清晰,且通过在多种任务上的广泛实验验证了其方法的有效性。
题目:Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video
作者:Shashanka Venkataramanan, Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis

论文地址:https://openreview.net/forum?id=Yen1lGns2o
这篇论文开辟了自监督图像预训练的新路径——通过分析连续视频来进行学习。作者不仅引入了新型数据,还提出了一种针对这些新数据的学习方法。
题目:Meta Continual Learning Revisited: Implicitly Enhancing Online Hessian Approximation via Variance Reduction
作者:Yichen Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng, Ying Wei

这篇论文提出了一种新的方差下降策略,适用于元连续学习领域。这种方法不仅表述明确,具有实际应用价值,而且还通过遗憾分析(regret analysis)得到了理论上的验证。
题目:Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
作者:Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao

这篇论文解决了对Transformer基础的大语言模型极为重要的KV缓存压缩问题,采用了一个简单却能显著减少内存需求的策略,且无需进行资源消耗大的微调或重训。这种方法简洁而有效,展示了出色的实用价值。
题目:Proving Test Set Contamination in Black-Box Language Models
作者:Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, Tatsunori Hashimoto

这篇论文提出了一种既简洁又精巧的方法,能够检测一个监督学习数据集是否已经被包含在了大语言模型的训练过程中。
题目:Robust agents learn causal world models
作者:Jonathan Richens, Tom Everitt

这篇论文在理论层面上取得了突破,探讨了因果推理如何影响智能体在新领域的泛化能力,可能会对一系列相关领域产生深远的影响。
题目:The mechanistic basis of data dependence and abrupt learning in an in-context classification task
作者:Gautam Reddy

这是一项及时且系统的研究,专注于探索我们刚开始了解的在上下文学习(in-context learning)与权重学习(in-weight learning)之间的机制差异。
题目:Towards a statistical theory of data selection under weak supervision
作者:Germain Kolossov, Andrea Montanari, Pulkit Tandon

论文地址:https://openreview.net/forum?id=HhfcNgQn6p
这篇论文为数据子集选择建立了统计学基础,并揭示了当前流行的数据选择方法存在的主要缺陷。
本文来自微信公众号”新智元“



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
