# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
提高 GPU 利用率,就是这么简单。
AI 的快速发展,伴随而来的是大计算量。这就自然而然的引出了一个问题:如何减少 AI 对计算的需求,并提高现有 AI 计算效率。
为了回答这一问题,来自斯坦福的研究者在博客《GPUs Go Brrr》中给出了答案。

博客地址:https://hazyresearch.stanford.edu/blog/2024-05-12-tk
文章主要专注于两个问题:一是硬件真正需要什么?二是如何满足硬件需求?
文章用大量篇幅讨论了如何让 GPU 更快的运行,并发布了一个库 ThunderKittens,用户可以很容易地在 CUDA 上编写快速的深度学习内核。其具有以下特点:
GitHub 链接:https://github.com/HazyResearch/ThunderKittens
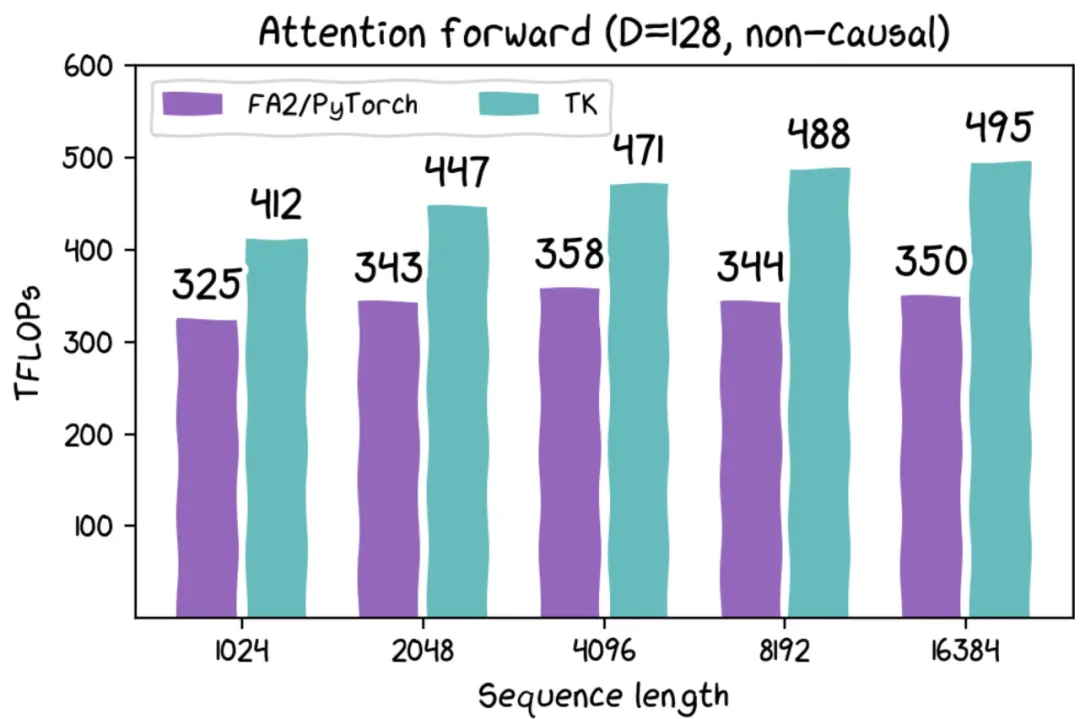
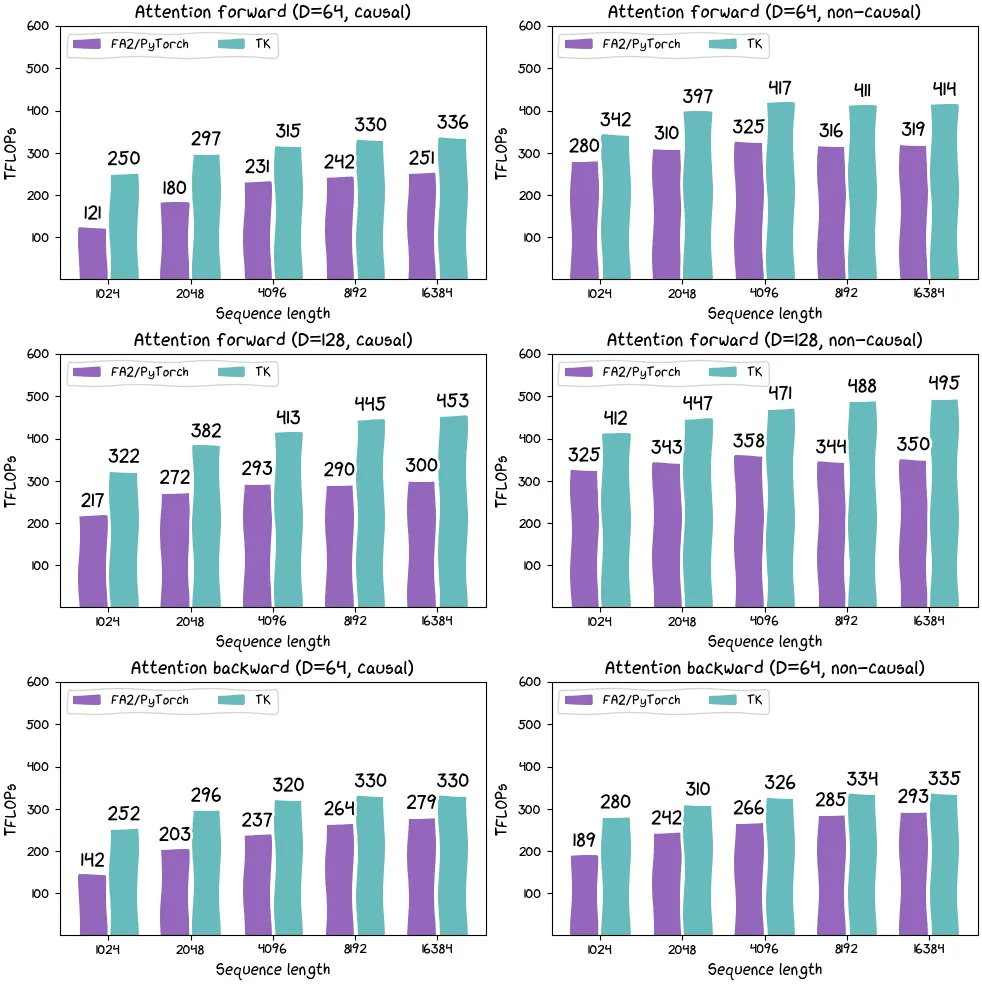
ThunderKittens 使得一些棘手的事情变得非常简单,从而在现代硬件上实现了非常高的利用率。项目中,作者用 ThunderKittens 编写了一个 RTX 4090 简单的 FlashAttention-2 内核,代码总共有 58 行代码(不包括空格),结果显示,ThunderKittens 在 RTX 4090 上实现了大约 122 TFLOP(理论最大值的 74%)。此外,内核程序只有 100 行的情况下,ThunderKittens 在 H100 上的性能比 FlashAttention-2 高出约 30%。
该研究重点关注 NVIDIA H100,不过所介绍的内容也适用于其他 GPU。

H100 SXM GPU 包含:
除了上述这些,H100 SXM GPU 还有很多可关注的东西,例如内存控制器、指令缓存等。
研究者表示保持张量核心的运行流畅并不容易。他们发现了一些 AI 硬件上的怪癖,这些怪癖中的很多内容也适用于非 H100 GPU,但 H100 尤其棘手。(相比之下,RTX 4090 则非常容易使用),这些怪癖包括:

文章进一步描述了 GPU 这些怪癖的具体内容。
H100 有一组新指令,称为「warp group matrix multiply accumulate,WGMMA」(PTX 中的 wgmma.mma_async,或 SASS 中的 HGMMA/IGMMA/QGMMA/BGMMA)。以前的 GPU 上可用的张量核心指令是 wmma.mma.sync 和 mma.sync 。通过这些指令,SM 单个象限上的 32 个线程将同步地将其数据块馈送到张量核心并等待结果。
不同的是,wgmma.mma_async 指令并非如此,128 个连续线程(分布在 SM 的所有象限中)协作同步,并直接从共享内存(也可以选择寄存器)异步启动矩阵乘法。
在基准测试中,研究团队发现这些指令对于提取 H100 的完整计算是必要的。如果没有它们,GPU 的峰值利用率似乎只能达到峰值利用率的 63% 左右。
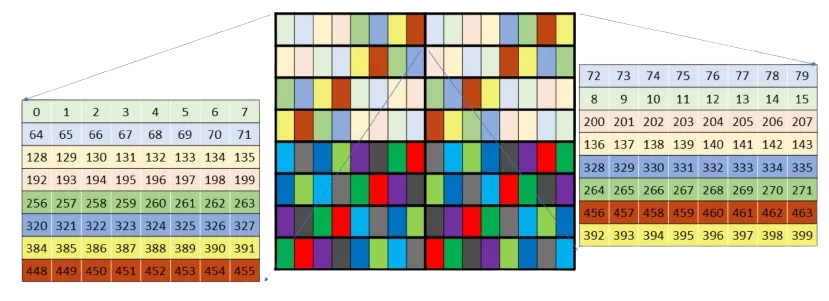
共享内存的单次访问延迟约为 30 个周期,这听起来似乎不算多,但在这段时间内,SM 的张量核心几乎可以完成两个完整的 32x32 矩阵乘法运算。
共享内存处理起来有些棘手,因为它被存储(banked)在 32 个独立的内存存储中。如果不小心,这可能会导致所谓的 bank 冲突,即同一内存 bank 被要求同时提供多个不同的内存片段,导致请求被串行化,这可能会不成比例地减慢内核的速度 - 而 wgmma 和 mma 指令所需的寄存器布局会受到这些 bank 冲突的影响。解决方法是使用各种交错模式重新排列共享内存,以避免这些冲突。
H100 其中一个特点是张量核心和内存都足够快,以至于仅仅生成用于获取数据的内存地址就占据了芯片资源的相当一部分。
NVIDIA 似乎已经意识到了这一点,因为他们赋予了 GPU 张量内存加速器(或称之为 TMA)。TMA 允许用户在全局和共享内存中指定多维张量布局,这节省了所有的地址生成成本,并且还使得构建 pipeline 更加容易。
研究团队还发现 TMA 和 wgmma.mma_async 一样,在实现 H100 的全部潜力方面是完全不可或缺的。
在某些方面,与前几代硬件相比,H100 对占用率的依赖程度较低。NVIDIA 确实在设计 GPU 时考虑了占用率。虽然对于 H100 来说,占用率只能说有用,但作用不大。研究者发现在 A100 和 RTX 4090 上它变得越来越重要。
那么,如何才能更轻松地编写内核,同时仍兼具硬件的全部功能?
研究团队设计了一个嵌入 CUDA 中的 DSL,被命名为 ThunderKittens。

ThunderKittens 旨在尽可能简单,并包含四种模板类型:
tile 通过高度、宽度和布局进行参数化,寄存器向量由长度和布局参数化,共享向量仅由长度参数化。这样通常不会遭受 bank 冲突的困扰。
研究团队还提供了一些必要操作:
初始化,如将共享向量清零
该研究给出了一个用 ThunderKittens 编写的,用于 RTX 4090 的简单前向 flash attention 内核:
总共大约有 60 行 CUDA 代码,硬件利用率为 75%,虽然非常密集,但大部分复杂性在于算法,而不是混合模式或寄存器布局。
TMA、WGMMA、swizzling 模式和描述符的复杂度又如何呢?如下是用 ThunderKittens 编写的, H100 的 FlashAttention-2 前向传递:
这个内核只有 100 行代码,它在 H100 上的性能比 FlashAttention-2 高出约 30%。ThunderKittens 负责 wrap up 布局和指令,并提供一个可以在 GPU 上使用的 mini-pytorch。
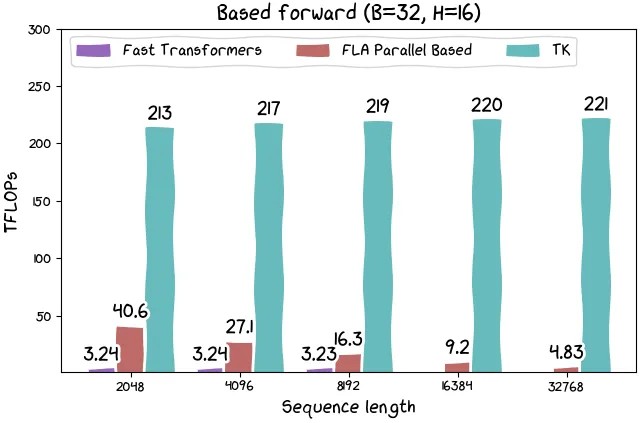
此外,研究团队还发布了基于线性注意力的内核和其他架构。基于线性注意力内核的运行速度为 215 TFLOP(如果考虑算法中固有的重计算,则运行速度超过 300 TFLOP)。
虽然理论上线性注意力更高效,但从实践经验来看,线性注意力在硬件上的效率大大降低。因此,ThunderKittens 有望开辟广泛的高吞吐量应用。
在研究团队看来,ThunderKittens 之所以运行良好,是因为它不会试图做所有事情。CUDA 确实比 ThunderKittens 更有表现力,而 ThunderKittens 又小又简单。
不过,ThunderKittens 具有很好的抽象能力,它具有小的 tile,这与 AI 和硬件的发展相匹配。ThunderKittens 不支持任何少于 16 的维数。但在研究团队看来,这一点并不重要,尤其对于硬件而言。如果你的矩阵乘法小于 16x16,你确定自己做的还是 AI 吗?
从哲学的视角来看,研究团队认为框架迁移是合理的。「寄存器」当然不应该像旧 CPU 那样的 32 位。CUDA 使用的 1024 位宽向量寄存器无疑朝着正确方向迈出了一步。但对研究团队而言,「寄存器」是 16x16 的数据 tile。他们认为 AI 想要这样,它仍然只是矩阵乘法、规约和重塑。当然硬件也想要这样,小的矩阵乘法寻求硬件支持,而不仅仅是 systolic mma。
实际上,从更广泛的视角来看,研究团队认为应该围绕硬件的良好映射来重新调整 AI 思路。比如,循环状态应该有多大?SM 能够容纳多大尺寸?计算密度是多少?这些都不亚于硬件的要求。
研究团队表示,这项工作未来的一个重要方向是利用他们对硬件的了解来帮助设计与硬件相匹配的 AI。
最后,AMD 硬件上适配的 ThunderKittens 也将很快推出。
本文来自微信公众号“机器之心”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
