# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

预训练语言模型在分析核苷酸序列方面显示出了良好的前景,但使用单个预训练权重集在不同任务中表现出色的多功能模型仍然存在挑战。
百度大数据实验室(Big Data Lab,BDL)和上海交通大学团队开发了 RNAErnie,一种基于 Transformer 架构,以 RNA 为中心的预训练模型。
研究人员用七个数据集和五个任务评估了模型,证明了 RNAErnie 在监督和无监督学习方面的优越性。
RNAErnie 超越了基线,分类准确率提高了 1.8%,交互预测准确率提高了 2.2%,结构预测 F1 得分提高了 3.3%,展现了它的稳健性和适应性。
该研究以「Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning」为题,于 2024 年 5 月 13 日发布在《Nature Machine Intelligence》。

RNA 在分子生物学的中心法则中扮演着关键角色,它负责将 DNA 中的遗传信息传递给蛋白质。
RNA 分子在基因表达、调控和催化等多种细胞过程中起着至关重要的作用。鉴于 RNA 在生物体系中的重要性,对 RNA 序列进行高效、准确的分析方法需求日益增长。
传统的 RNA 序列分析依赖于如 RNA 测序和微阵列等实验技术,但这些方法通常成本高昂、耗时且需要大量的 RNA 输入。
为了应对这些挑战,百度 BDL 和上海交通大学团队开发了一种预训练的 RNA 语言模型:RNAErnie。
该模型建立在知识集成增强表示(ERNIE)框架之上,并包含多层和多头 Transformer 块,每个 Transformer 块的隐藏状态维度为 768。预训练是使用一个广泛的语料库进行的,该语料库由从 RNAcentral 精心挑选的约 2300 万条 RNA 序列组成。
所提出的基序感知预训练策略涉及基础级掩蔽、子序列级掩蔽和基序级随机掩蔽,它有效地捕获了子序列和基序级知识,丰富了RNA序列的表示。
此外,RNAErnie 将粗粒度 RNA 类型标记为特殊词汇表,并在预训练期间将粗粒度 RNA 类型的标记附加在每个 RNA 序列的末尾。通过这样做,该模型有可能辨别各种 RNA 类型的独特特征,从而促进域适应各种下游任务。
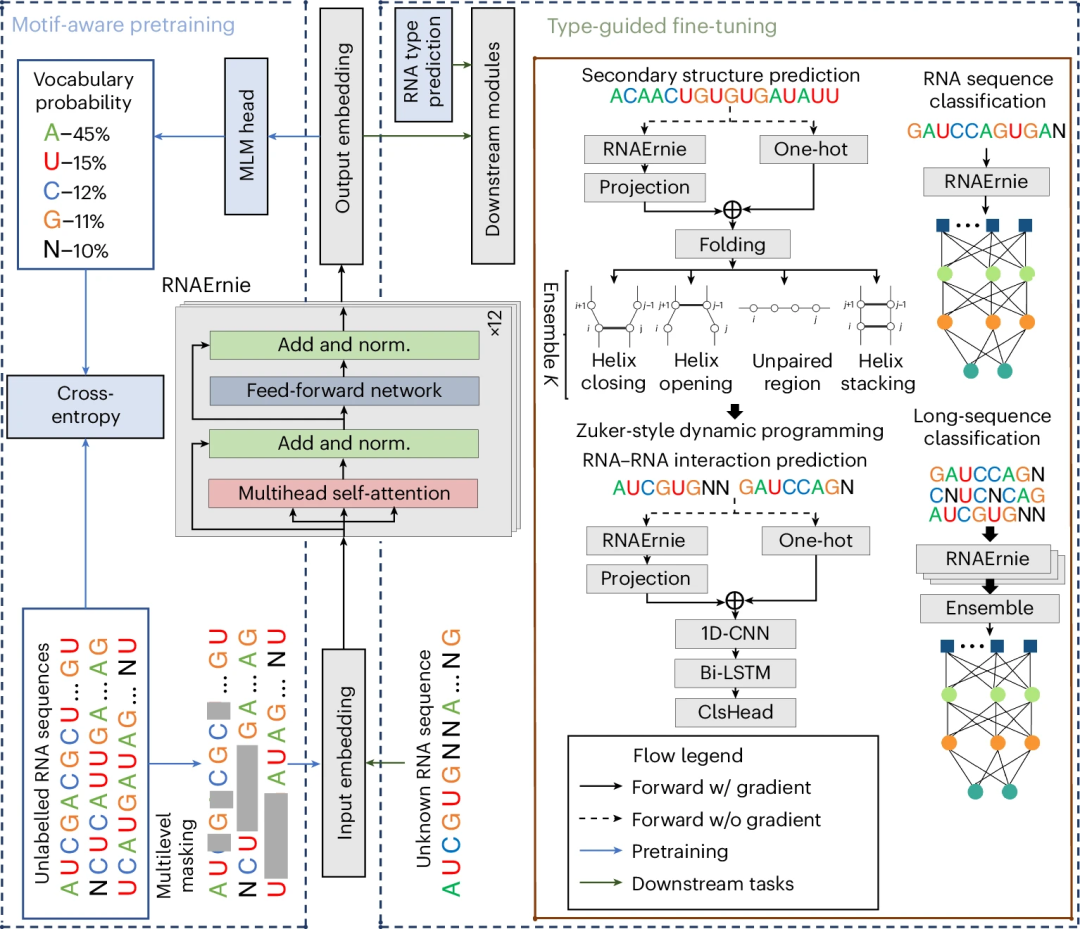
图示:模型概述。(来源:论文)
具体来说,RNAErnie 模型由 12 个 Transformer 层组成。在主题感知预训练阶段,RNAErnie 在从 RNAcentral 数据库中提取的大约 2300 万个序列的数据集上进行训练,使用自我监督学习和主题感知多级随机掩码。
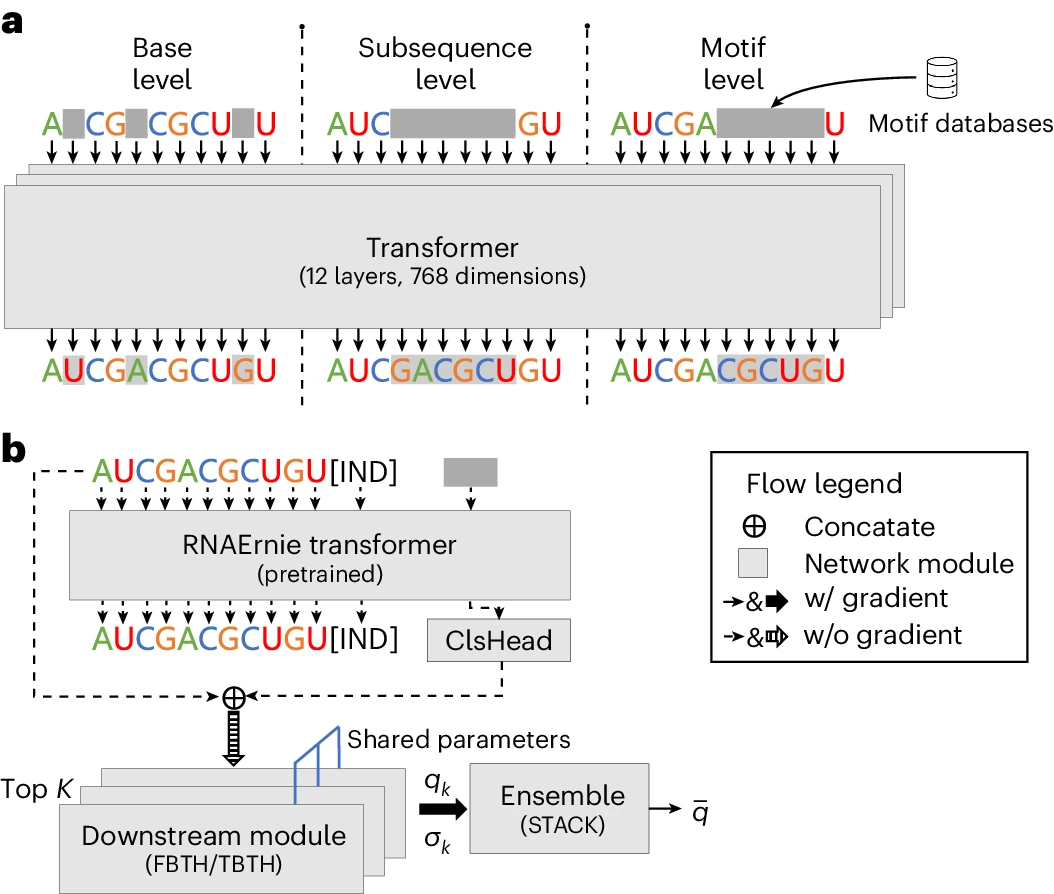
图示:主题感知预训练和类型引导微调策略。(来源:论文)
在类型引导的微调阶段,RNAErnie 首先使用输出嵌入预测可能的粗粒度 RNA 类型,然后利用预测的类型作为辅助信息,通过特定于任务的头来微调模型。
这种方法使模型能够适应各种 RNA 类型,并增强其在广泛的 RNA 分析任务中的实用性。
更具体地说,为了适应预训练数据集和目标域之间的分布变化,RNAErnie 利用域适应将预训练主干与三种神经架构中的下游模块组合在一起:具有可训练头的冻结骨干网(FBTH)、具有可训练头的可训练骨干网(TBTH)和用于类型引导微调的堆叠(STACK)。
通过这种方式,所提出的方法可以端到端优化主干和特定于任务的头,或者使用从冻结主干中提取的嵌入来微调特定于任务的头,具体取决于下游应用。
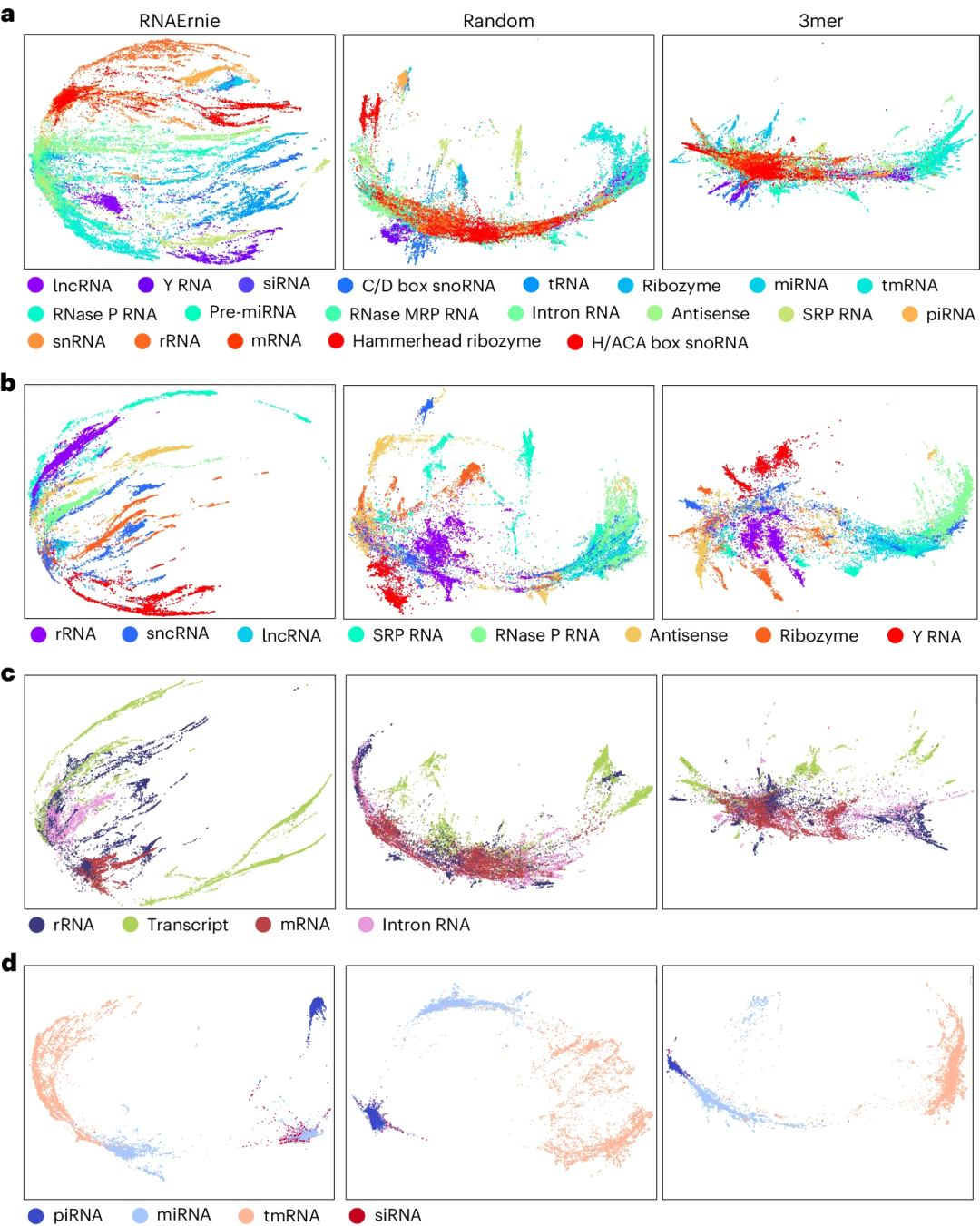
图示:RNAErnie 捕获多级本体模式。(来源:论文)
研究人员评估了该方法,结果显示 RNAErnie 在七个 RNA 序列数据集(涵盖超过 17,000 个主要 RNA 基序、20 个 RNA 类型和 50,000 个 RNA 序列)中优于现有先进技术。
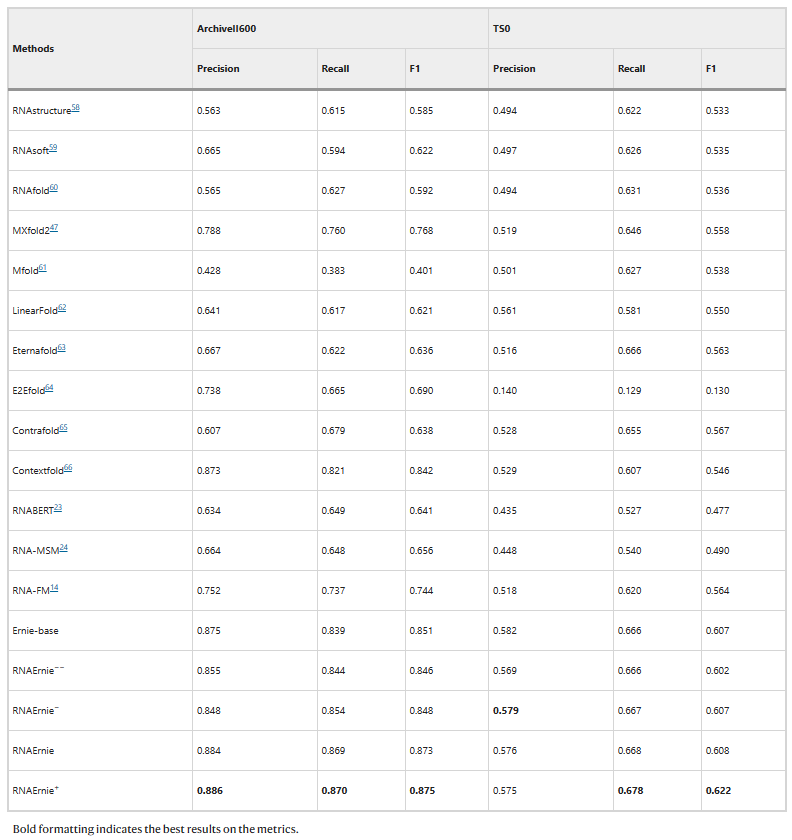
图示:RNAErnie 使用 ArchiveII600 和 TS0 数据集在 RNA 二级结构预测任务上的性能。(来源:论文)
使用 30 种主流 RNA 测序技术进行评估,证明了 RNAErnie 的泛化性和稳健性。该团队采用准确度、精确度、召回率、F1 分数、MCC 和 AUC 作为评估指标,从而确保 RNA 序列分析方法的公平比较。
目前,将具有增强外部知识的 Transformer 架构应用于 RNA 序列数据分析的研究很少。从头开始的 RNAErnie 框架集成了 RNA 序列嵌入和自我监督学习策略,从而为下游 RNA 任务带来卓越的性能、可解释性和泛化潜力。
此外,RNAErnie 还可以通过修改输出和监控信号来适应其他任务。RNAErnie 是公开可用的,是理解类型引导 RNA 分析和高级应用的有效工具。
虽然 RNAErnie 模型在 RNA 序列分析方面有所创新,但仍面临一些挑战。
首先,该模型受到它可以分析的 RNA 序列大小的限制,因为长度超过 512 个核苷酸的序列会被丢弃,可能会忽略重要的结构和功能信息。为处理较长序列而开发的分块方法可能会导致有关远程相互作用的信息进一步丢失。
其次,这项研究的重点很窄,仅集中在 RNA 结构域上,没有扩展到 RNA 蛋白质预测或结合位点识别等任务。此外,该模型在考虑 RNA 的三维结构基序(例如环和连接点)时遇到了困难,而这对于理解 RNA 功能至关重要。
更重要的是,现有的事后架构设计也有潜在的局限性。
尽管如此,RNAErnie 在推进 RNA 分析方面拥有巨大潜力。该模型在不同的下游任务中展示了其作为通用解决方案的多功能性和有效性。
此外,RNAErnie 采用的创新策略有望增强其他预训练模型在 RNA 分析中的性能。这些发现使 RNAErnie 成为一项宝贵的资产,为研究人员提供了一个强大的工具来解开 RNA 相关研究的复杂性。
论文链接:https://www.nature.com/articles/s42256-024-00836-4
文章来源于“机器之心”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
