ATOM Report:中国开源模型已经全面领先,而且差距还在扩大
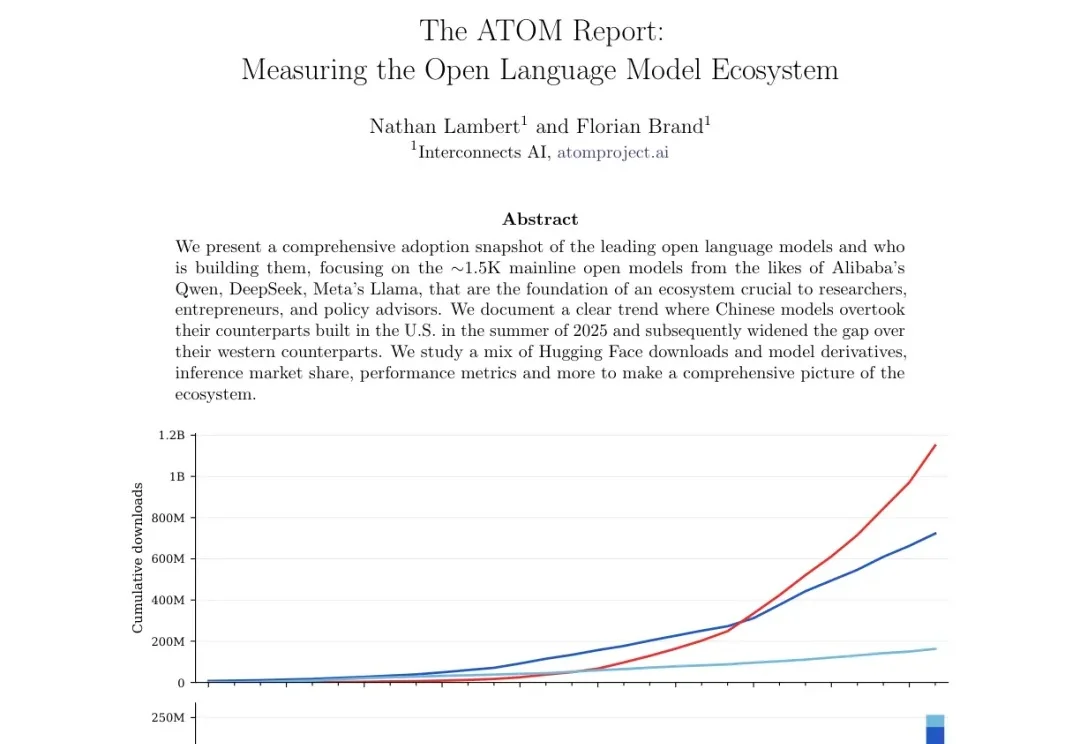
ATOM Report:中国开源模型已经全面领先,而且差距还在扩大2026 年 4 月,Nathan Lambert 和 Florian Brand 发布了 The ATOM Report,一份关于开源语言模型生态的综合采纳度快照。这份报告追踪了约 1500 个主线开源模型的下载量、衍生模型、推理市场份额和性能数据,覆盖 2023 年 11 月到 2026 年 3 月
来自主题: AI资讯
8952 点击 2026-04-09 14:47