# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着深度学习的快速发展,许多研究者们开始尝试利用深度神经网络解决多标签图像识别(Multi-label Image Recognition, MLR)任务,并已取得了不俗的进展。
但是,由于图像本身和潜在标签类别的复杂性,收集满足现有模型训练的多标签标注信息往往成本高昂且难以拓展,导致现有的大部分多标签图像识别模型难以在现实应用场景中落地。
因此,近年来许多研究者开始致力于探索标注受限情况下的多标签图像识别(Multi-label Image Recognition with Partial Label, MLR-PL)算法来解决这个问题。

图1 多标签图像识别任务中完整标注与标注受限的区别
为此,近期中山大学联合广东工业大学联手探索标注受限情况下的多标签图像识别任务,提出了两种解决方案(即,结构化语义迁移和语义感知表达混合)并发表多篇文章于顶级期刊/会议(IJCV / TMM / AAAI)。
此外,为了更好的衡量现有方法在不同标注比例下的性能,研究人员构建了一个统一且公平的评测基准,该基准复现了多个效果较好的传统多标签图像识别方法,以及数个最新发表的标注受限情况下的多标签图像识别算法,并使用统一的数据集以及标注比例,以此进行公平的比较评测。
仓库链接:https://github.com/HCPLab-SYSU/HCP-MLR-PL
具体而言,研究人员做了以下两方面的工作:
通过对多标签图像中的强语义相关性的探索研究,团队提出了一种异构语义转移(Heterogeneous Semantic Transfer, HST) 框架。
该框架探索图像内和图像间潜在的语义相关性,从而实现有效的未知标签生成。相关文章发表于 IJCV'24 & AAAI'22。

IJCV 2024:https://arxiv.org/pdf/2205.11131

AAAI 2022:https://aaai-2022.virtualchair.net/poster_aaai1133
除了正负样本标注受限情况外,正样本标注受限情况下的多标签图像识别(Multi-label Image Recognition with Partial Positive Label, MLR-PPL)对进行了额外的拓展讨论。
在该问题中,提出了一种类别自适应标签发现与噪音抑制(Category-Adaptive Label Discovery and Noise Rejection)框架。相关文章发表于 TMM'24。

TMM 2024:https://ieeexplore.ieee.org/document/10517428/
通过对多标签图像混合中的可能存在的语义/上下文混淆进行分析,团队提出了一种语义感知表达混合(Dual-Perspective Semantic-Aware Representation Blending, DSRB)框架。
该框架分别从实例和原型的角度混合特定于类别的视觉表达,以此实现多样化且稳定的混合视觉表达生成。相关文章发表于 ESWA'24 & AAAI'22。

ESWA 2024:https://www.sciencedirect.com/science/article/abs/pii/S0957417424003919

AAAI 2022:https://aaai-2022.virtualchair.net/poster_aaai1134
现有的 MLR 算法主要将多标签图像识别任务视为多个二元分类子任务,从该角度出发将未知标签视为缺失或负标签是一种直观且简单的方法,因此可以通过调整这些算法来解决 MLR-PL 任务。
然而,这种简单粗暴的处理会导致模型丢失部分标注数据,甚至产生一些噪声标签,这可能会损害模型的训练过程并不可避免地导致明显的性能下降。
幸运的是,每个多标签图像内以及不同多标签图像之间都存在很强的语义相关性。这些相关性有助于有效地迁移已知标签的语义知识来构造未知标签,从而解决上述困境。
如下图所示,语义相关性分为两种类型,即
1)图像内相关性:标签共现在现实世界的图像中广泛存在,并且具有高共现概率的标签可能共存于一幅图像中,例如,汽车 往往与 人 同时出现,而 桌子 则倾向于与 椅子 同时出现。
2)跨图像相关性:属于同一类别且来自不同图像的对象可能具有相似的视觉外观,因此具有相似视觉特征的图像可能具有相同的标签。
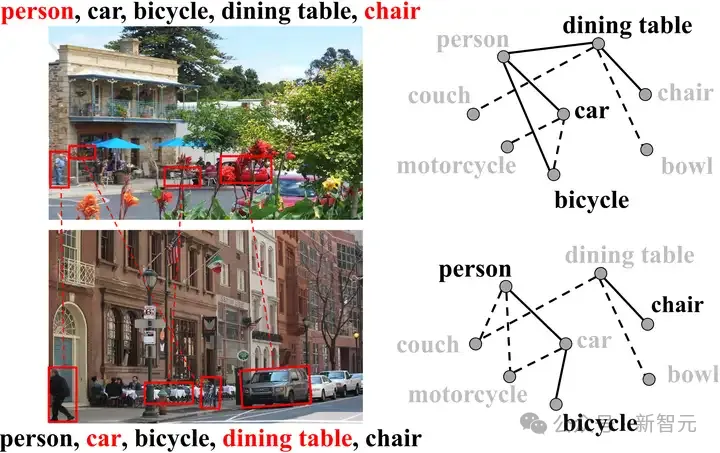
图2 多标签图像中存在强语义相关性
基于上述发现,团队开展了对于语义相关性的探索研究,以通过一种新颖的异构语义转移(Heterogeneous Semantic Transfer, HST)框架来帮助补充未知标签。
该框架由语义感知表达学习 (SARL) 模块、图像内语义转移(IST)模块和跨图像语义转移(CST)模块组成,其中 SARL 模块通过结合各个类别的语义来学习特定于类别的特征表达;IST 模块通过学习每个图像的所有类别之间的共现矩阵,以此补充与已知标签具有高共现概率的未知标签;CST 模块通过学习特定类别的表达原型以及相应的特征表达和原型之间的特定于类别的相似性,并基于此补充具有高相似性的未知标签。
最后,可以使用已知标签和补充标签来监督 MLR 模型的训练。
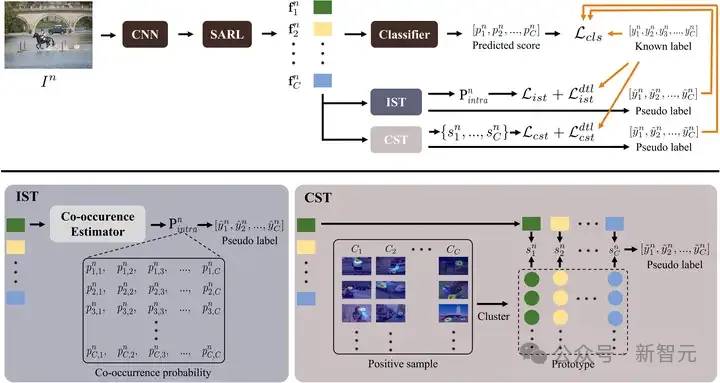
图3 HST 框架图 (发表于 IJCV 2024 & AAAI 2022)
除了上述工作外,团队也对 MLR-PL 任务本身进行了拓展讨论。为了更贴合实际应用场景,坐着建议训练具有部分正标签的 MLR 模型(MLR-PPL),即仅知道一部分正标签,而其余正标签和所有负标签缺失。
在这种情况下,可以充分利用丰富的在线用户标记图像来大幅降低标注成本。然而,团队也认识到这项任务提出了更大的挑战,主要是由于监督信号的大幅减少和负标签的缺失,这会导致模型表现出始终预测正面标签的强烈偏见。
由于缺乏负训练样本,仅使用部分正标签训练 MLR 模型的传统做法通常会导致「始终预测正」解决方案。
为了解决这个问题,之前的研究提出了一种朴素的训练策略,假设负数(AN),其中所有缺失的标签都被视为负数。
虽然这种策略在一定程度上缓解了困境,但由于将许多积极标签错误地注释为消极标签,它可能会显着降低性能。为此,团队提出了一种新颖的框架,该框架探索各个类别的跨图像语义相关性,以此识别未知的正标签并丢弃噪声标签。
具体而言,该框架由两个互补模块组成,分别是类别自适应标签发现模块(Category-Adaptive Label Discovery, CALD)和类别自适应噪声抑制(Category-Adaptive Noise Rejection, CANR)模块。
其中,CALD 模块测量正样本队列中同一类别的特征表示之间的语义相似度,然后利用这些语义相似度来生成伪标签。
同时,CANR 模块通过评估各个样本之间的语义相似度来计算样本权重。随后,它通过识别相关权重较低的标签来消除噪声标签。与之前的工作不同,团队还设计了类别自适应阈值更新来自适应调整 CALD 和 CANR 模块中每个类别的阈值,避免了极其耗时和费力的手动调整。
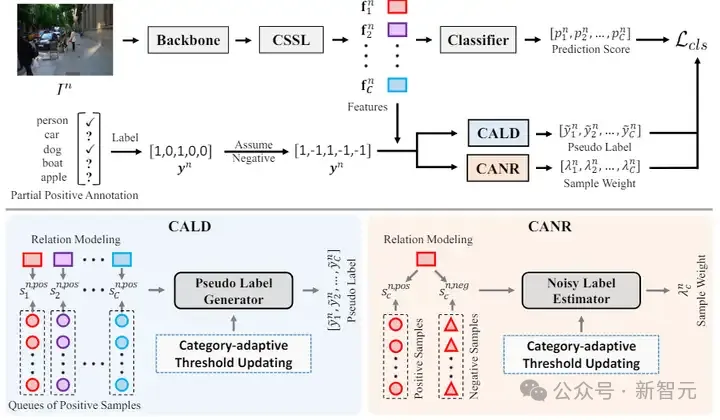
图4 所提出方法的框架图(发表于 TMM 2024)
除了语义相关性外,团队也发现在一个图像 I^n 中未知的特定标签 c 在另一图像 I^m 中可能是已知的。
因此,将图像 I^m 中已知标签 c 的信息混合到图像 I^n 可能有助于补充图像 I^n 的未知标签 c
然而,通过简单的混合操作混合两个图像几乎无法帮助促进 MLR-PL 任务,因为此类操作可能会导致语义和上下文混淆。
首先,多标签图像包含不同语义类别的多个对象,简单地混合两个图像可能会将两个具有完全不同语义的对象混合在一起,从而在训练过程中误导模型。
如下图所示,将图像 I^m 混合到图像 I^n 中,混合了 I^m 中的 人 和 I^n 中的 交通灯 在一起,这会产生令人混淆的区域,并可能会损害训练过程。
其次,许多物体类别由于数据样本数量的原因严重依赖上下文进行识别。因此, 简单地混合任意两个图像,特别是如果它们属于不同的场景,可能会破坏这些依赖性。
例如下图中在街道和浴室中捕获的两个图像,街道的场景可能会为识别 吹风机 和 牙刷 提供令人困惑的上下文信息。

图5 图像混合中的语义/上下文混淆
基于上述发现,团队提出了一种语义感知表达混合(Dual-Perspective Semantic-Aware Representation Blending, DSRB)框架,该框架学习每个图像的特定于类别的表达,然后执行特定于类别的表达混合以补充未知标签。
它由两个关键模块组成,分别从实例和原型的角度混合特定于类别的视觉表达。具体而言,DSRB 框架建立在特定类别表达学习 (CSRL) 模块的基础上,该模块合并类别语义来指导学习特定类别语义表达。
然后,团队设计了一个实例视角表达混合(IPRB)模块,即将一幅图像 I^m 中已知标签 c 的表达与另一幅图像 I^n 中相应未知标签 c 的表达混合,因此它可以补充图像 I^n 的未知标签 c。
同时,提出了原型视角表达混合(PPRB)模块来学习每个类别的更鲁棒的表达原型,并以位置敏感的方式将未知标签的表达与相应标签的原型混合以补充这些未知标签。通过这种方式,可以同时生成多样化且稳定的混合视觉表达来补充未知标签,从而促进 MLR-PL 任务。
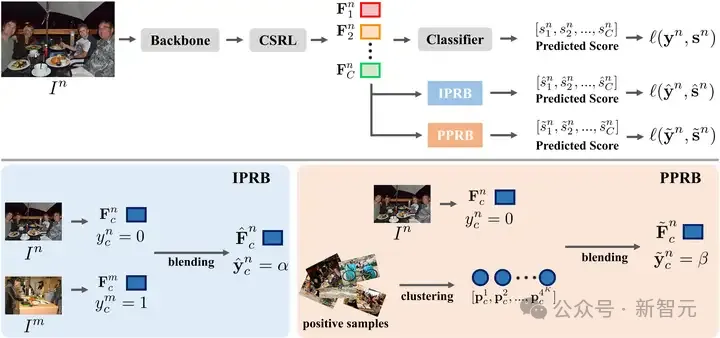
图6 DSRB 框架图(发表于 ESWA 2024 & AAAI 2022)
为了解决不同标注比例下对比不公平的问题,团队构建了一个统一且公平的评测基准。该评测基准复现了多个效果较好的传统多标签图像识别方法,以及数个最新发表的标签受限下多标签图像识别算法,并使用统一的数据集以及标注比例,以此进行公平的比较评测。与其他工作相比,该评测基准有多个优点:
标注比例选取一致:该评测基准统一了多种标注比例下的数据设置,以此确保对各个方法进行统一且公平的对比。
对比方法涵盖范围广:该评测基准对比了多样化的不同方法:1)效果较好的传统多标签图像识别方法,包括 SSGRL [1],GCN-ML [2],KGGR [3],P-GCN [4],ASL [5];2)最新发表的标签受限下多标签图像识别算法,包括 CL [6],Partial BCE [6]。
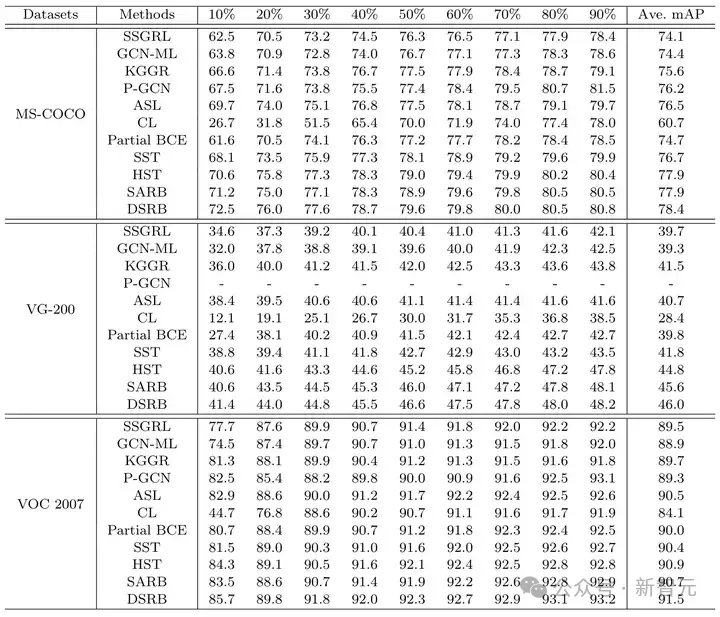
图7 在不同标注比例下的实验结果
参考资料:
[1] T. Chen, M. Xu, X. Hui, H. Wu, L. Lin, "Learning semantic-specific graph representation for multi-label image recognition", in ICCV 2019.
[2] Z. Chen, X. Wei, P. Wang, Y. Guo, "Multi-label image recognition with graph convolutional networks", in CVPR 2019.
[3] T. Chen, L. Lin, X. Hui, R. Chen, H. Wu, "Knowledge-Guided Multi-Label Few-Shot Learning for General Image Recognition", in TPAMI 2022.
[4] Z. Chen, X. Wei, P. Wang, Y. Guo, "Learning graph convolutional networks for multi-label recognition and applications", in TPAMI 2021.
[5] T. Ridnik, E. Ben-Baruch, N. Zamir, A. Noy, I. Friedman,M. Protter, L. Zelnik-Manor, "Asymmetric loss for multi-label classification", in ICCV 2021.
[6] T. Durand, N. Mehrasa, G. Mori, "Learning a deep convnet for multi-label classification with partial labels", in CVPR 2019.
文章来源于:微信公众号新智元



