# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

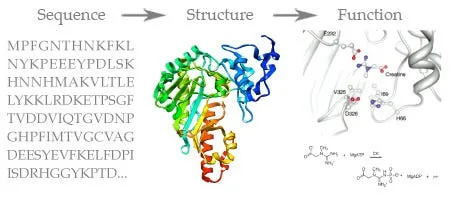
「大语言模型」不仅可以用于人类语言,也可以用于蛋白质的「语言」,而且两者之间有很多相似之处。
过去几年,Transformer架构带来了大模型在文本和图像方面的惊人进展,当应用于生命科学领域时,也取得了影响深远的的成果。
大语言模型是如何应用于蛋白质组学的?科学家们又有哪些发现?
蛋白质是一种「语言」
自然语言由单词、短语、句子等不同层次的模块组成,蛋白质的「语言」也是类似的情况。
蛋白质由基序(motif)和结构域(domain)组成,类似于蛋白质世界的「单词」和「短语」。
基序和结构域的各种组合与重复构建了更加复杂的结构,从而决定蛋白质的生物功能,类似于人类语言中句子传达的含义。
除了结构层次的相似性,蛋白质和人类语言还有另一个关键的相似点——「信息完整性」。
这意味着从信息论的角度来看,蛋白质的信息(例如其结构)完全包含在其序列中。
虽然由于环境和与其他分子的相互作用,蛋白质的行为方式可能发生变化,但它仍然由基础序列定义。
就像每个句子的含义虽然会因为语境和语气的不同发生变化,但是其信息都藏在句子本身之中。
因此,由氨基酸组成的蛋白质序列至关重要,决定了蛋白质在环境中的结构和功能,也会影响蛋白质在生物系统中的折叠和相互作用。
既然蛋白质和语言这么相似,我们是不是可以遵循「拿来主义」,把自然语言处理的方法直接照搬过来就行了?
当然不行。
问题就在于,NLP和蛋白质语言建模之间虽然可以类比,但并不完全一样。
首先,我们可以直接阅读和理解自然语言,但蛋白质不行。大多数人类语言有统一的标点符号和停顿词,由明确的词汇组成,具有明显可分的结构,而这些都是蛋白质语言没有的。
其次,对于蛋白质,我们并不总是知道氨基酸序列是否是功能单元的一部分。
而且,蛋白质在长度上也表现出高度可变性,一个序列可以包含20个或者上千个氨基酸。
蛋白质语言模型(pLM)
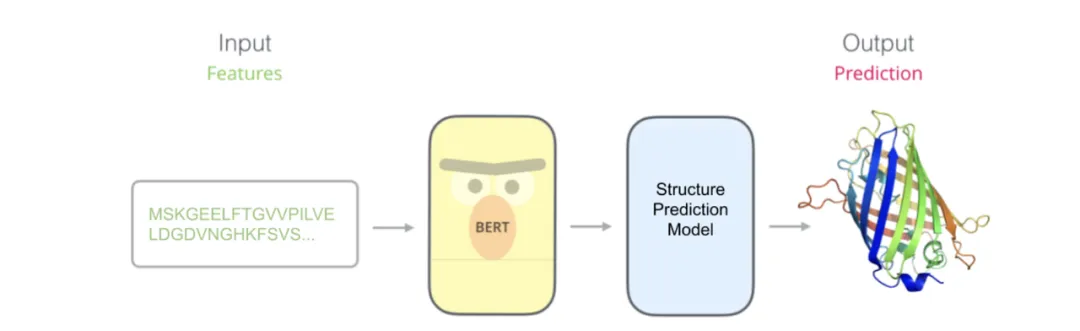
许多早期pLM都是基于Encoder-only Transformer架构,因为它们的目标是在向量空间中获得蛋白质的嵌入表示,用于下游任务。
这些模型的大多数使用类BERT架构,并将去噪自动编码作为训练目标,即通过以某种方式破坏输入token,并在预训练时让模型重建原始序列。
Facebook训练的ESM以及ProtTrans、ProteinBERT等预训练模型都属于此类。
在预训练阶段生成嵌入后,通过监督学习技术进一步完善模型,以解决蛋白质工程中的各种下游任务,比如:
与Encoder模型不同,Decoder模型采用自回归训练,训练目标是根据给定上下文,让模型预测后续单词。
听起来很熟悉吧?
当前最成功的语言模型之一——GPT就是这样训练出来的。
pLM领域中,GPT型Decoder的一个早期例子是ProtGPT2,参数量级为738M,在5000万个蛋白质序列上训练而成。
ProtGPT2 成功生成了与天然蛋白质有相似特征的序列,比如含有的氨基酸类型以及各种氨基酸的出现频率,而且序列在有序(稳定)和无序(灵活)区域之间表现出类似的平衡。
此外,研究人员目测,ProtGPT2生成的蛋白质保留了一些结合位点,这对功能性至关重要。
尽管生成的序列看起来很靠谱,但很难说它们的功能是否真的像天然蛋白质。
而且ProtGPT2没有流行太久,很快就被更大、更好的模型所取代。
ProGPT2 利用类似于 GPT2 的结构生成蛋白质序列,而新开发的方法则在训练阶段整合了生物学中更深层次的上下文知识。
这种方法可确保模型学到的「模式」不仅在统计学上正确,而且具有生物学意义。
蛋白质模型可以通过两种主要方式进行条件化——
2019年的一篇论文提出了「Conditional Transformer Language」,简称CTRL,是一种包含条件标签的自回归模型。
CTRL的提出标志着 NLP 领域的一大进步。
这些条件标签被称为控制代码,让模型无需输入序列即可生成有针对性的文本,有效地影响输出文本的体裁、主题或风格。
基于CTRL,2023年的一篇论文就提出了ProtGen模型,在2.81亿个蛋白质序列上进行训练,并采用UniProtKB关键词作为条件标签,
这些标签涵盖 「生物过程」、「细胞成分」和 「分子功能」等十个类别,包含1100 多个术语。
ProGen达到了更好的效果,即使为未见的蛋白质家族生成序列时,也能达到与高质量英语模型相当的困惑度。
ProGen的性能表明,通过模仿天然蛋白质,我们蛋白质设计的领域取得了重大进展。
严格的测试证明,这些蛋白质的功能与天然蛋白质一样好,甚至更好。具体来说,ProtGen能够:
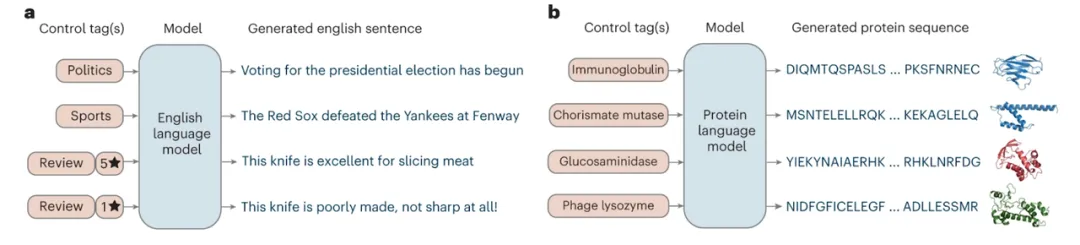
大型语言模型生成跨不同家族的功能蛋白序列
而且ProtGen的能力不局限于模仿天然蛋白质。
今年Profluent Bio发表了一篇新论文,他们使用ProGen设计的Cas9蛋白能够成功编辑人类基因,但这种蛋白质在自然界中原本并不存在。
这表明,我们现在不仅实现了模仿自然,甚至还可以超越,在天然蛋白质的基础上改进,设计出更高的合成蛋白质。
除了序列,我们还可以在训练时结合蛋白质的结构,这样模型就可以按照从结构到序列的流程学习。
这就是所谓的「反向折叠」,因为它与蛋白质从序列到结构的折叠正好相反。
这听起来可能违反直觉,但实际上是蛋白质设计中非常有用的过程,尤其是蛋白酶和治疗药物的设计。
比如,你希望设计一种酶或治疗蛋白质,完成一项特定任务,与某种分子结合或催化某种特定反应。
传统的方法通常是调整现有的蛋白质序列,然后测试新版本是否能更好地完成任务。这种方法通常很慢,而且偶然性较大,导致成功率不高。
反向折叠则从理想的结构开始,也就是你预测的最能执行目标的结构。在此基础上,反向折叠可以找出哪些序列可以折叠到该结构中。
这种方法有多个优点,一方面,反向折叠模型往往非常快速,可以在几分钟内预测出数百个潜在序列。
另一方面,与传统方法相比,这种方法还能探索更广泛的潜在序列。因为传统方法可能只会稍微改变现有序列。这种广泛探索让我们有机会找到从曾考虑过的序列,也许它们才可能具有最佳的特性。
最典型的反向折叠模型是Facebook提出的ESM-IF,它采用encoder-decoder架构,将结构作为encoder的输入,并以结构编码为条件对序列进行自回归解码。
「规模就是一切」
我们已经看到,随着计算能力、数据和模型规模的增加,通用语言模型在复杂任务上的性能也在提高。
规模大到一定程度时,语言模型会表现出有用的能力,如少样本语言翻译、常识推理和数学推理等,这些能力是将简单的训练过程扩展到大型数据语料库的结果,
生物学中的序列推理也有类似的思路。
由于蛋白质的结构和功能制约着其序列的突变,而突变是通过进化选择出来的,因此可以从序列模式推断生物结构和功能,这将有助于深入了解生物学中的一些最基本的问题。
这正是由Meta建立的有15B参数的ESM-2所做的工作。
通过利用语言模型(ESM-2)的内在表征,ESMFold 只使用单序列作为输入就能生成结构预测,从而大大加快了结构预测的速度。
当人为地将单序列作为输入时,ESMFold还能生成比AlphaFold2或RoseTTAFold更准确的原子级预测,准确性随着语言模型规模的扩大逐渐提高。
在将完整的多序列对齐结果(MSA)作为输入的情况下,ESMFold还能获得与RoseTTAFold相当的性能。
此外,ESMFold对低困惑度序列的预测结果与SOTA模型不相上下。
而且更普遍的是,结构预测准确性与语言模型的困惑度相关,这表明当语言模型能更好地理解序列时,它也能更好地理解结构。
这意味着,通过扩大模型规模和数据集大小,我们就可以摆脱特定的归纳偏置(如 MSA),只用一个序列作为输入就能生成结构预测。
虽然ESM-2的准确性不如当时的AlphaFold,但它是一种有趣且简单的方法,可以利用不断扩大的多样化的未注释蛋白质序列数据:

为了进一步说明ESM蛋白质模型的惊人能力,研究人员用高度优化的单克隆抗体(包括针对埃博拉病毒和COVID等疾病的抗体)进行了一项了不起的实验。
他们将这些抗体的序列输入ESM模型,然后发现了实际氨基酸序列与预测之间的差异。
通过选择性地用模型预测的氨基酸取代这些差异位点上的氨基酸,研究人员大大提高了抗体的结合亲和力、热稳定性和体外效力——
成熟抗体的效力提高了7倍,而未成熟抗体的效力则提高了惊人的160倍!!
结语
尽管取得了重大进展,但我们仍处于充分掌握蛋白质序列空间复杂性的早期阶段。
长期以来,了解蛋白质之间关系的唯一方法是明确的成对或多序列比对,这种方法依赖于假定的进化联系,将一种蛋白质的残基映射到另一种蛋白质的残基上。
但最近,一种更通用的方法正在形成,它不太关注进化的谱系,而更关注蛋白质的基本功能和结构。
如果这种进展速度继续保持下去,我们就有可能获得突破性的发现——发现熟悉蛋白质的未知面,甚至合成全新的蛋白质。
这一愿景面临一个挑战——缺乏可解释性。
随着这些模型变得越来越复杂,了解它们是如何处理和表示蛋白质序列至关重要。
特别是对于药物研发等应用来说,确定模型如何预测结合位点非常关键。
蛋白质建模的下一步涉及开发更多受生物学启发的模型。这意味着我们要在已有模型的框架内加深对生物化学知识的整合,以完善其准确性和功能性。
通过在模型训练和数据处理中嵌入更深刻的生物学见解,我们才可以显著提升各种蛋白质相关任务的效果。
通过将更大更好的模型与巧妙的实验设计相结合,蛋白质组学有望取得更多突破。
LLM已经重塑了我们对于科技的想象,pLM的发展又会把我们带向何处?
文章来源于“新智元”,作者“新智元”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
