# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在复杂的物理世界中,人型机器人的全身控制一直是个难题,现有的强化学习做出的效果有时会比较抽象。近日,LeCun参与的一项工作给出了基于数据驱动的全新解决方案。
有了大模型作为智能上的加持,人型机器人已然成为新的风口。
科幻电影中「安能辨我不是人」的机器人似乎已经越来越近了。
不过,要想像人类一样思考和行动,对于机器人,特别是人型机器人来说,仍是个艰巨的工程问题。
就拿简单的学走路来说,利用强化学习来训练可能会演变成下面这样:

道理上没什么问题(遵循奖励机制),上楼梯的目标也达到了,除了过程比较抽象,跟大部分人类的行为模式可能不太一样。
机器人之所以很难像人一样「自然」行动,原因在于观察和行动空间的高维性质,以及双足动物形态固有的不稳定性。
对此,LeCun参与的一项工作给出了基于数据驱动的全新解决方案。

论文地址:https://arxiv.org/pdf/2405.18418
项目介绍:https://nicklashansen.com/rlpuppeteer
先看疗效:

对比右边的效果,新的方法训练出了更接近于人类的行为,虽然有点「丧尸」的意味,但抽象度降低了不少,至少在大部分人类的能力范围之内。
当然了,也有来捣乱的网友表示,「还是之前那个看着更有意思」。

在这项工作中,研究人员探索了基于强化学习的、高度数据驱动的、视觉全身人形控制方法,没有任何简化的假设、奖励设计或技能原语。
作者提出了一个分层世界模型,训练高级和低级两个智能体,高级智能体根据视觉观察生成命令,供低级智能体执行。
开源代码:https://github.com/nicklashansen/puppeteer
这个模型被命名为Puppeteer,利用一个模拟的56-DoF人形机器人,在8个任务中生成了高性能的控制策略,同时合成了自然的类似人类的动作,并具有穿越挑战性地形的能力。

在物理世界中学习训练出通用的智能体,一直是AI领域研究的目标之一。
而人形机器人通过集成全身控制和感知,能够执行各种任务,于是作为多功能平台脱颖而出。
不过要模仿咱们这种高级动物,代价还是很大的。
比如下图中,人型机器人为了不踩坑,就需要准确地感知迎面而来的地板缝隙的位置和长度,同时仔细协调全身运动,使其有足够的动量和范围来跨越每个缝隙。

Puppeteer基于LeCun在2022年提出的分层JEPA世界模型,是一种数据驱动的RL方法。
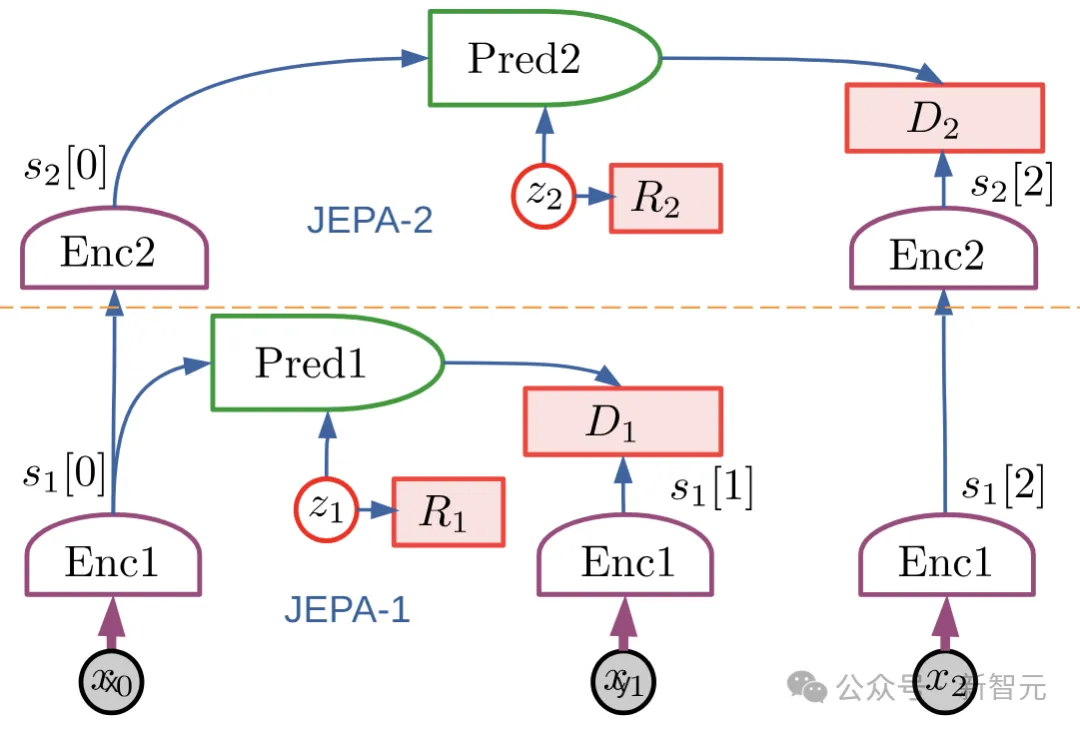
它由两个不同的智能体组成:一个负责感知和跟踪,通过关节级控制跟踪参考运动;另一个「视觉木偶」(puppeteer),通过合成低维参考运动来学习执行下游任务,为前者的跟踪提供支持。
Puppeteer使用基于模型的RL算法——TD-MPC2,在两个不同的阶段独立训练两个智能体。
(ps:这个TD-MPC2就是文章开篇用来比较的那个动图,别看有点抽象,那实际上是之前的SOTA,发表在今年的ICLR,一作同样也是本文的一作。)

第一阶段,首先对用于跟踪的世界模型进行预训练,使用预先存在的人类动作捕捉数据作为参考,将运动转换为物理上可执行的动作。这个智能体可以保存起来,在所有下游任务中重复使用。
在第二阶段,训练一个木偶世界模型,该模型以视觉观察为输入,并根据指定的下游任务,整合另一个智能体提供的参考运动作为输出。
这个框架看上去大道至简:两个世界模型在算法上是相同的,只是在输入/输出上不同,并且使用RL进行训练,无需其他任何花里胡哨的东西。
与传统的分层RL设置不同的是,「木偶」输出的是末端执行器关节的几何位置,而不是目标的嵌入。
这使得负责跟踪的智能体易于在任务之间共享和泛化,节省整体计算占用的空间。
研究人员将视觉全身人形控制,建模为一个由马尔可夫决策过程(MDP)控制的强化学习问题,该过程以元组(S,A,T,R,γ,∆)为特征,
其中S是状态,A是动作,T是环境转换函数, R是标量奖励函数, γ是折扣因子,∆是终止条件。
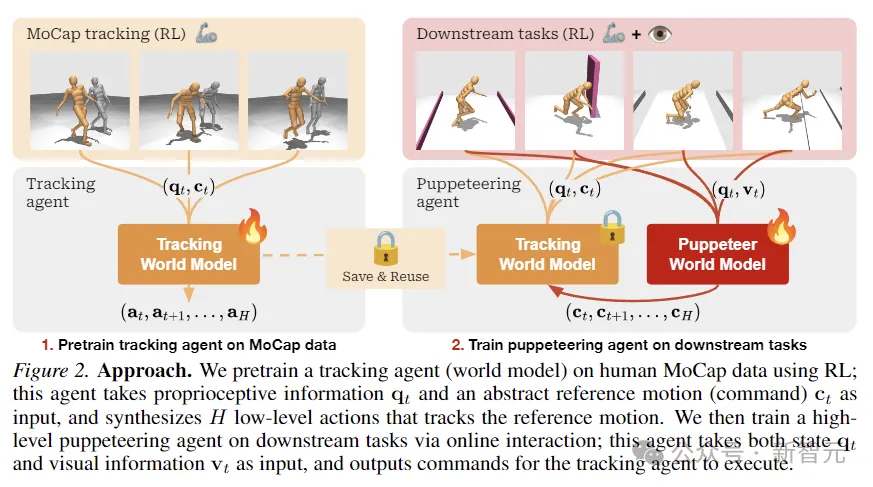
如上图所示,研究人员使用RL在人类MoCap数据上预训练跟踪智能体,用于获取本体感觉信息和抽象参考运动输入,并合成跟踪参考运动的低级动作。
然后通过在线互动,对负责下游任务的高级木偶智能体进行训练,木偶接受状态和视觉信息输入,并输出命令供跟踪智能体执行。
TD-MPC2从环境交互中学习一个潜在的无解码器世界模型,并使用学习到的模型进行规划。
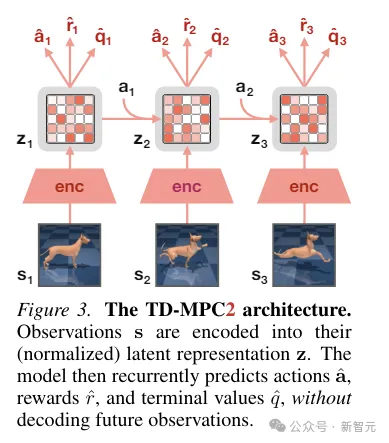
世界模型的所有组件都是使用联合嵌入预测、奖励预测和时间差异 损失的组合端到端学习的,而无需解码原始观察结果。
在推理过程中,TD-MPC2遵循模型预测控制(MPC)框架,使用模型预测路径积分(MPPI)作为无导数(基于采样)的优化器进行局部轨迹优化。
为了加快规划速度,TD-MPC2还事先学习了一个无模型策略,用于预启动采样程序。
两个智能体在算法上是相同的,都由以下6个组件组成:

为了评估方法的有效性,研究人员提出了一种新的任务套件,使用模拟的56自由度人形机器人进行视觉全身控制,总共包含8个具有挑战性的任务,用于对比的方法包括SAC、DreamerV3以及TD-MPC2。
8个任务如下图所示,包括5个视觉条件全身运动任务,以及另外3个没有视觉输入的任务。
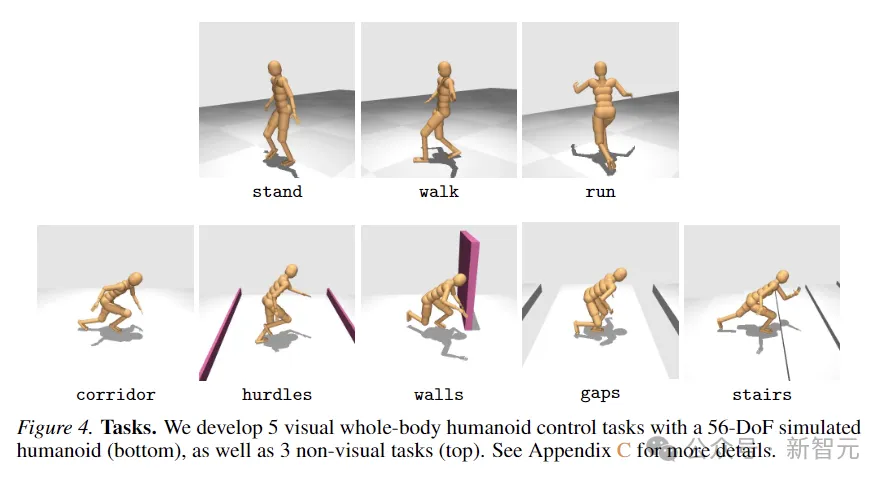
任务的设计具有高度的随机性,包括沿着走廊奔跑、跳过障碍物和缝隙、走上楼梯以及绕过墙壁。
5个视觉控制任务都使用与线性前进速度成正比的奖励函数,而非视觉任务则奖励任何方向的位移。
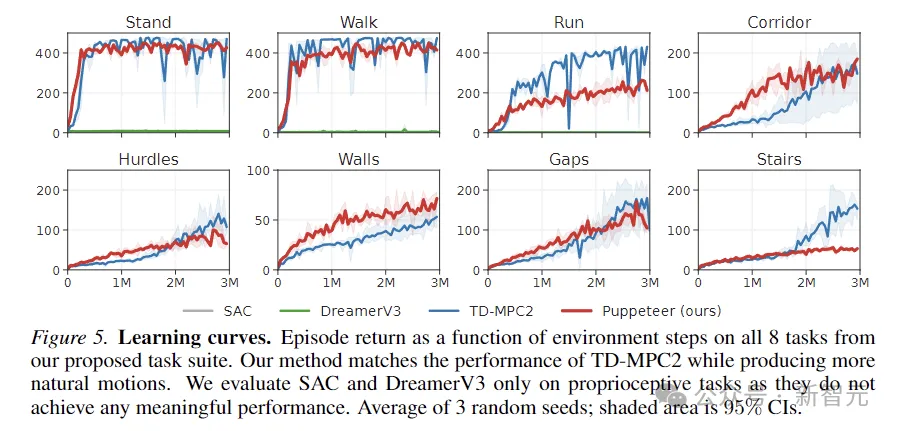
上图绘制了学习曲线。结果表明,SAC和DreamerV3在这些任务上无法实现有意义的性能。
TD-MPC2在奖励方面的性能与本文的方法相当,但会产生不自然的行为(参见下图中的抽象动作)。
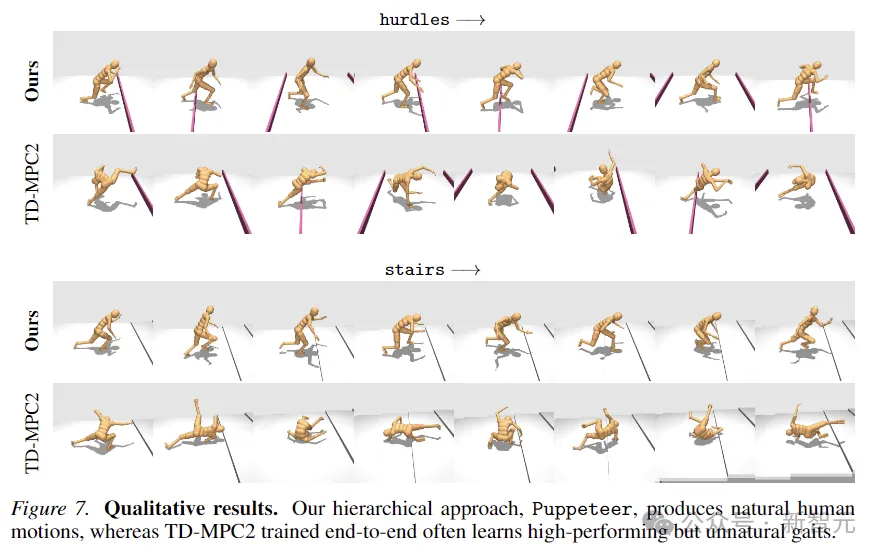
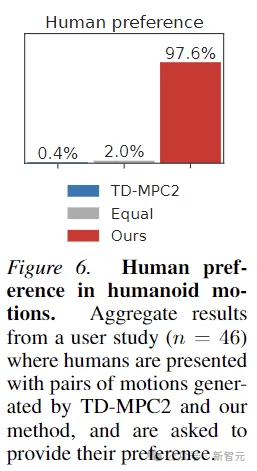
此外,为了证明Puppeteer生成的动作确实更「自然」,本文还进行了人类偏好的实验,对46名参与者的测试表明,人类普遍喜欢本文方法生成的运动。
参考资料:
https://x.com/ncklashansen/status/1795860968875917444
文章来自于微信公众号新智元,作者alan



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
