# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
短短一年后,AI 生成的「吃面条」已经如此自然流畅?这让全球网友都感受到了亿点点震撼。
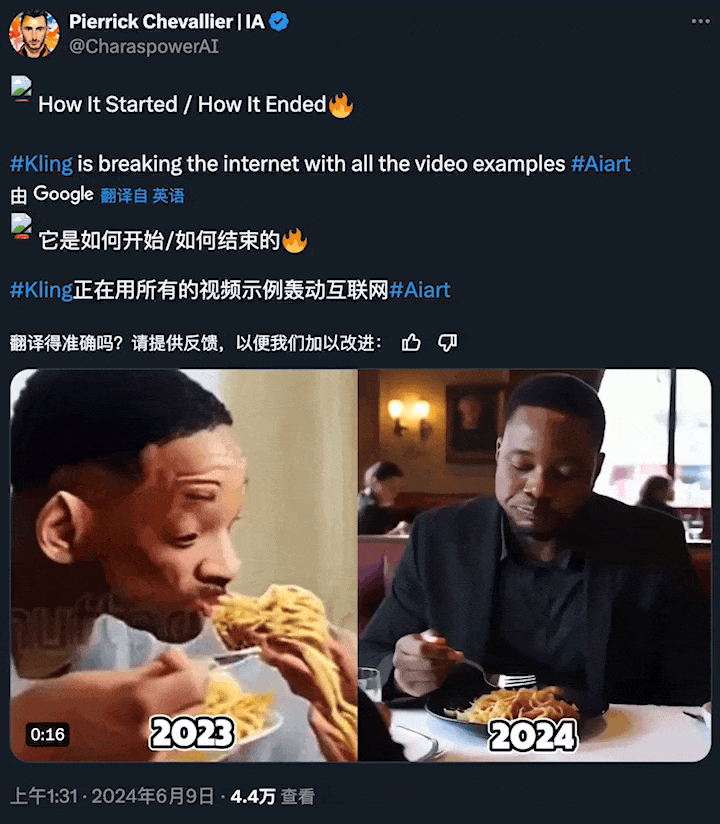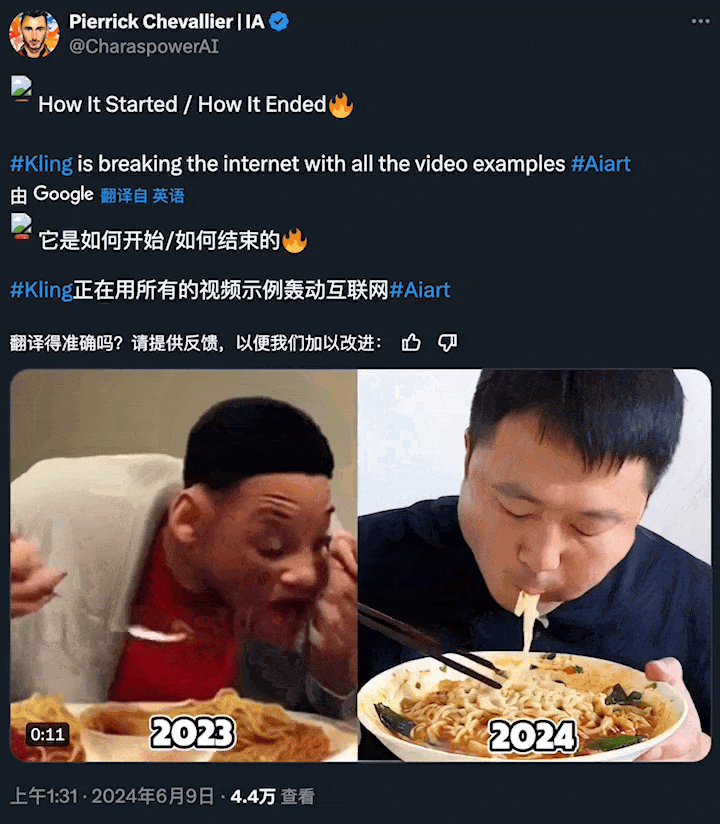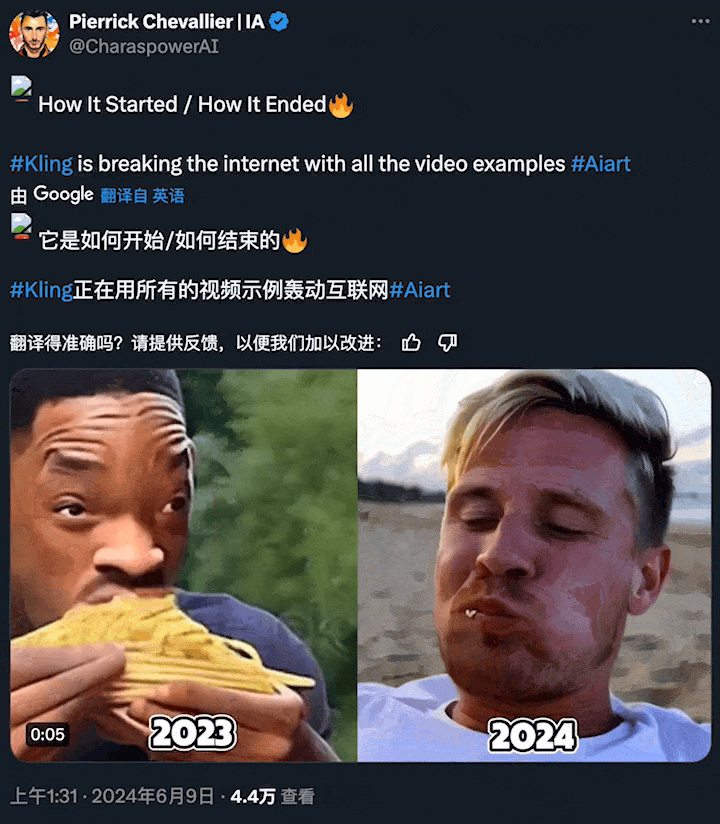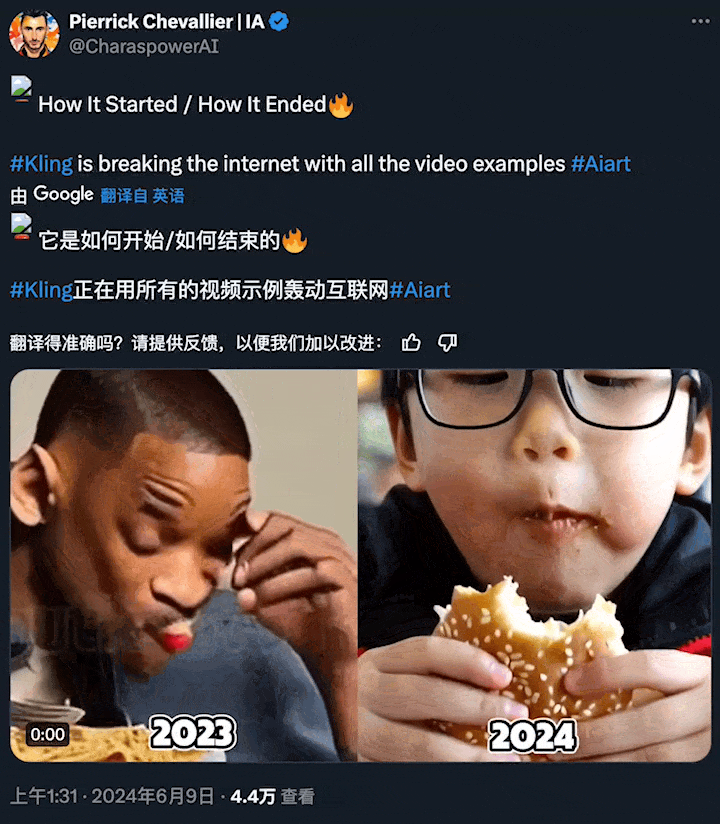
图源:https://x.com/CharaspowerAI/status/1799494388462063632
右侧的这些生成视频,都来自快手刚刚推出的文生视频大模型「可灵」(Kling)。
不是预发布、不是纯 Demo 合集,而是直接开放测试的产品级应用,人人都能申请。而且,可灵支持生成最长 2 分钟、30fps 的 1080P 视频,主打从头脑风暴到可发布作品的「一键转化」。(官网地址:https://kling.kuaishou.com/)
最早一批用上的用户已经「真香」:

图源:https://x.com/op7418/status/1799047146089619589

图源:https://weibo.com/7714861068/Oig1Qm8Or?refer_flag=1001030103_
500 人上限的交流群,很快就满员了,满屏都是 tql:
还没用上的外国友人只能干着急,在社交媒体发「求求了」:

不夸张地说,可灵现在是「一号难求」:
消息传到硅谷创投圈,更是引发了一场热议。
Stability AI 前 CEO Emad Mostaque 表示:「中国的 AI 技术有自己的优势。」
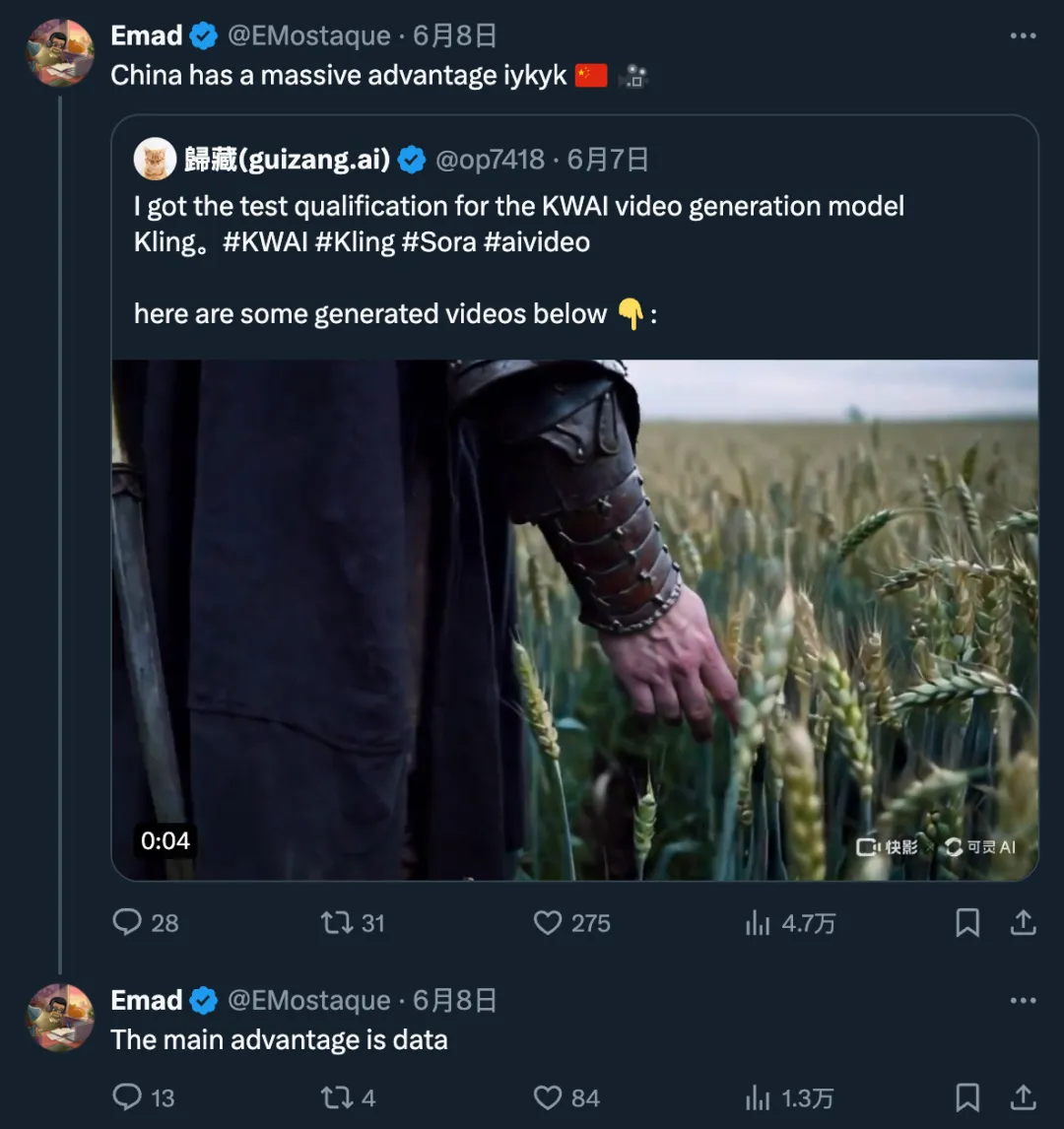
图源:https://x.com/EMostaque/status/1799133463003684918
YC CEO 也在 X 平台转发了可灵生成的 Demo:

就图中这个「吃汉堡」的案例而言,在相同的提示词下,可灵的生成效果确实比 Sora 更生动、真实:
Prompt:Une personne tapant son meilleur croc dans son hamburger

视频地址:https://x.com/AngryTomtweets/status/1799787209651859910
对于关注 AI 的人来说,这几天一定陆陆续续看过很多可灵生成的作品了。机器之心也是第一时间就点进了申请通道,并拿到了试用资格。
接下来,我们不妨一边试用、一边分析可灵爆火的原因。
或许你还记得这个曾经非常火爆的「气球人」视频。三位创作者花费近两周时间,使用 Sora 制作了这条 1 分 21 秒的视频短片,让人感到十分惊艳。不过,负责后期制作的 Patrick Cederberg 坦白了过程中的很多问题,例如气球的颜色在每次生成中都会改变、镜头中会出现一些瑕疵等等。

Sora 生成结果。完整视频地址:https://youtu.be/9oryIMNVtto?si=F6oDzvrhzfVcQGeh
对于此前的视频生成模型来说,「一气呵成」生成 1 分钟以上的内容确实有难度,特别是要求画面中的各种元素保持前后一致。
猎豹移动董事长兼 CEO、猎户星空董事长傅盛公开了自己用可灵制作的「气球人」视频,并表示自己仅用了「几十分钟」,就做出了连续性、真实度、清晰度都很优秀的短片。

在内测的过程中,我们还发现了一个专业创作者社区自发建立的教程与 Demo 文档,包含了上百个可灵生成的作品,还提供了测试维度的指导。
感兴趣的读者请戳:https://waytoagi.feishu.cn/wiki/GevKwyEt1i4SUVk0q2JcqQFtnRd
下面这个 2 分钟的公益短片《一个很远的地方》也是完全由可灵生成的,你能看出来吗?

在创作者 @AIGC 十三的作品《疯狂动物城赛车大赛》中,这 20 秒包含了疾速行驶的赛车(大幅度运动)、动物驾驶车辆(考验想象力的概念组合)等生成难点,但从结果来看,可灵很好地解决了这些问题:
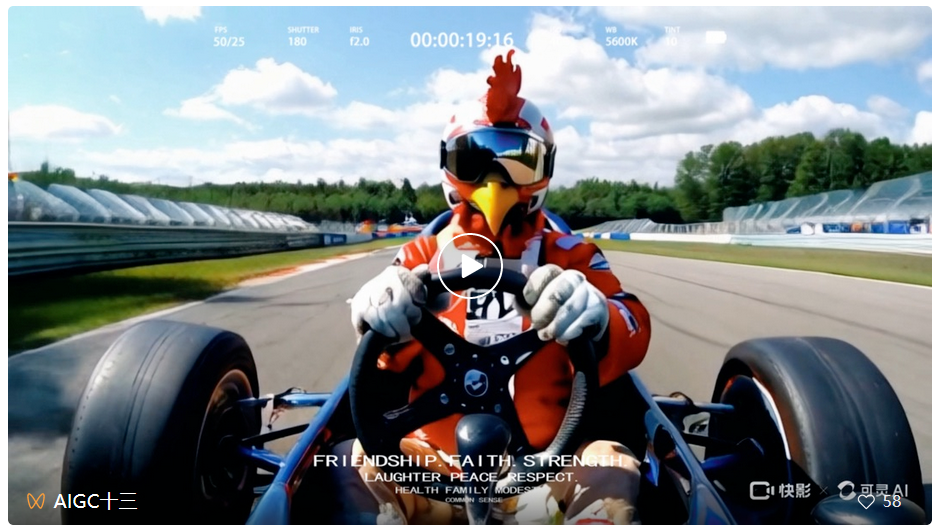
来源:可灵创作者@AIGC 十三
还有一个很有趣的案例是 @八级技工创作的《假期打开方式》,这段 56 秒的短频共花费了 3 小时制作,包含 23 个镜头。然后在可灵的生成结果之上添加配音,诙谐的感觉马上就有了:

来源:可灵创作者@八级技工
看完这些,我们应该已经意识到,可灵所代表的视频生成技术的影响力,远远超出了单纯的创作。在不同的研究领域和行业赛道,这一技术的落地正在加速,为从自动内容生成到复杂决策过程的各种任务提供了变革潜力。
传统的游戏开发通常受到预先渲染的环境和脚本事件的限制。一旦将视频生成模型集成到游戏领域,游戏的开发、玩耍和体验方式都将得到创新,为讲故事、互动和沉浸式体验带来新的可能性。对于游戏开发者来说,最直观的一项玩法是,根据用户叙述生成定制的视觉效果甚至角色动作。
在下方的 demo 中,我们可以看到,用户能够借助可灵创造出无与伦比的身临其境体验:
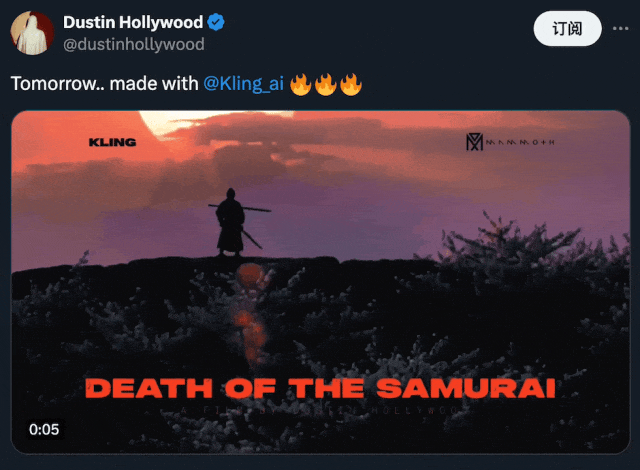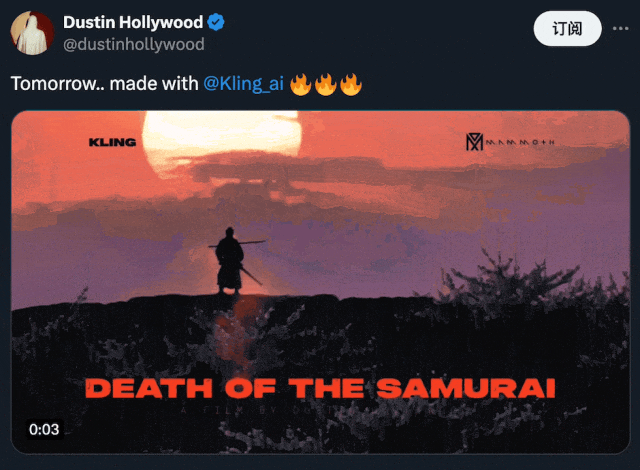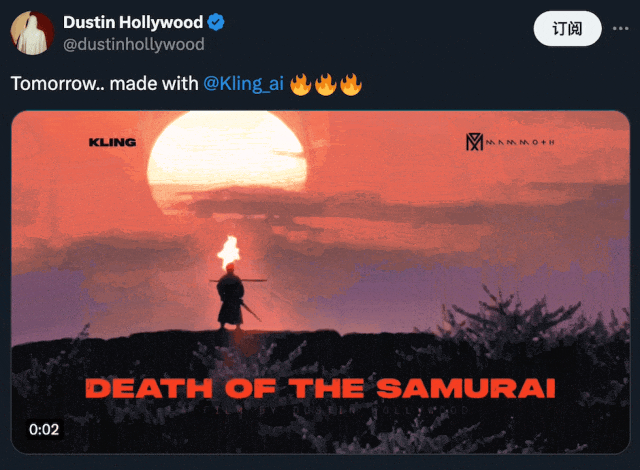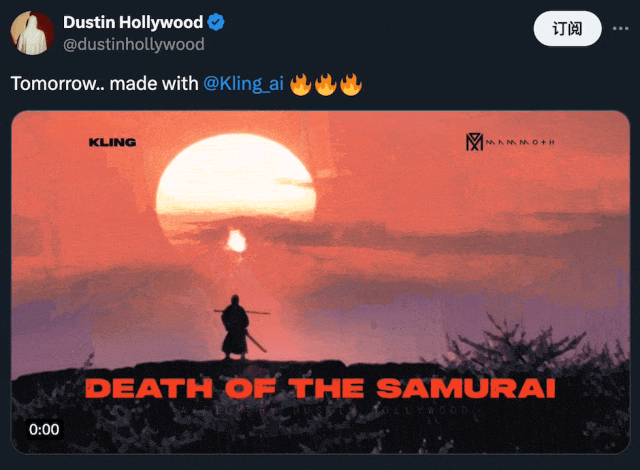
图源:https://x.com/dustinhollywood/status/1800056286215553444
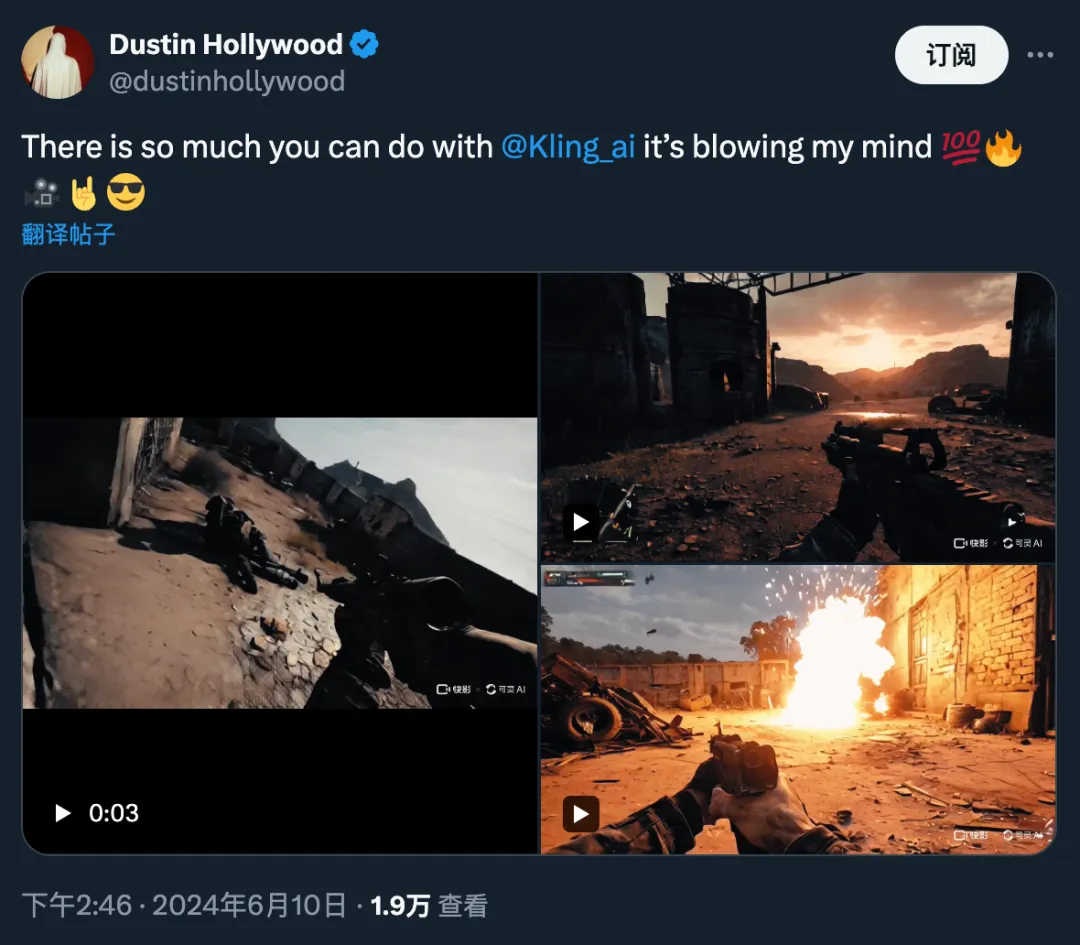



图源:https://x.com/dustinhollywood/status/1800056886693347624
另外一个将被颠覆的行业就是影视制作。传统的电影制作是一个艰巨而昂贵的过程,往往需要数年的努力、大量的设备和资金投入。视频生成技术的出现预示着电影制作进入了一个新的「民主化时代」,从简单的文本输入中自主生成个人影视作品的梦想正在成为现实。
现在,我们用可灵生成的是 5 秒的单镜头片段,伴随着技术的不断演进,用户单次能够生成的视频时长也会增加。比如说,我们未来或许能够一次性生成更长的视频内容,保持故事场景的连贯性和观赏性。其中的运镜手法也许会更高级,比如连贯的长镜头。
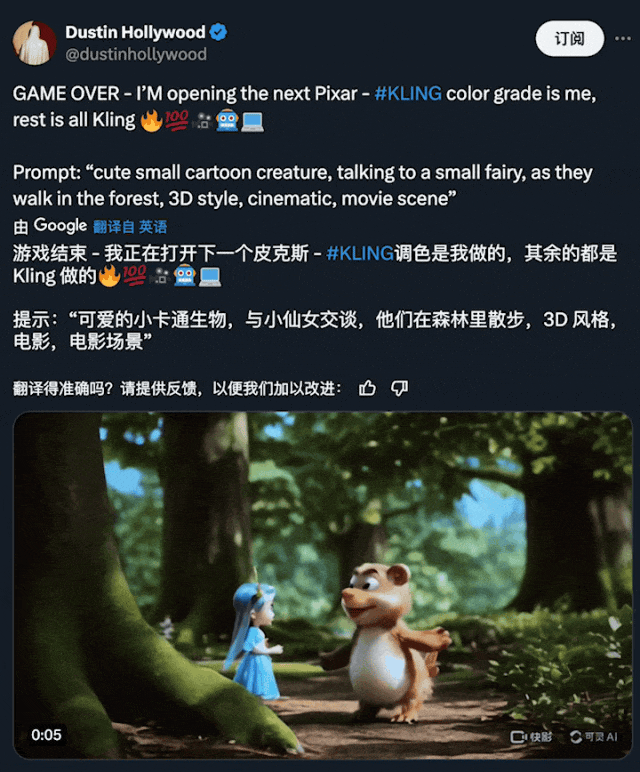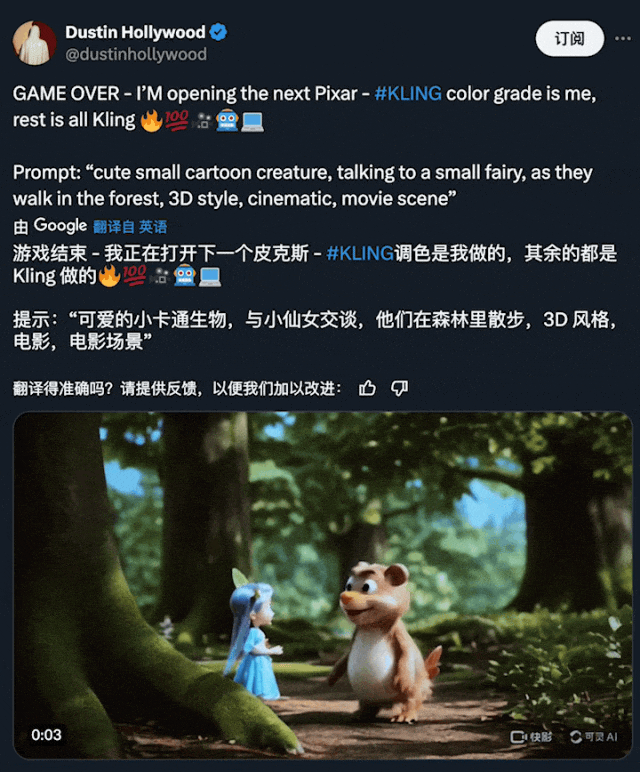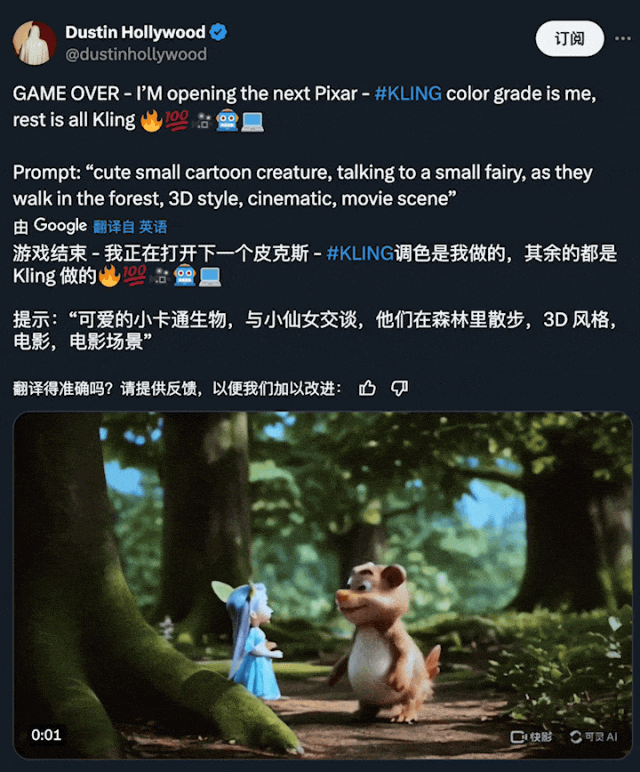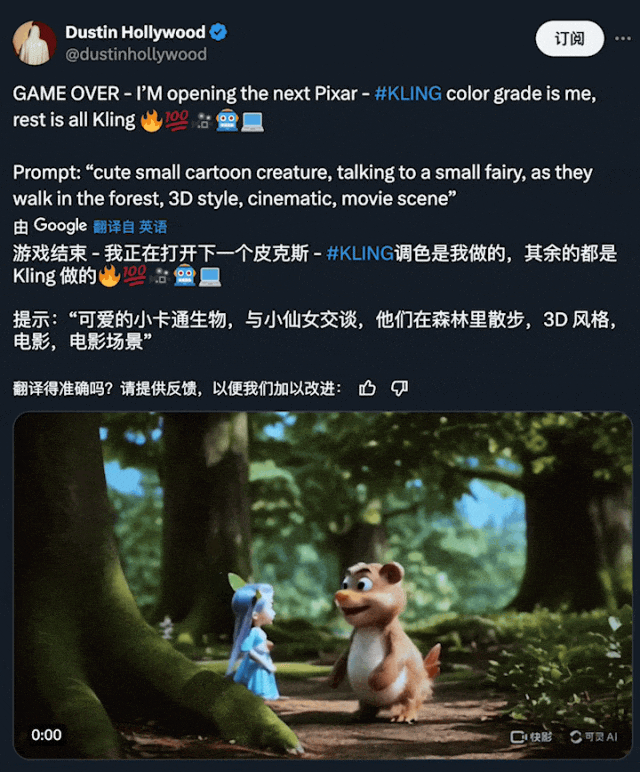
图源:https://x.com/dustinhollywood/status/1800007000849629674
下面这段剪影作品再次印证了一点:AI 对艺术的理解力与审美水准,丝毫不逊于人类。
Prompt:“A dancer’s silhouette transitions seamlessly through different dance styles, from hip-hop to ballet, in one continuous shot”

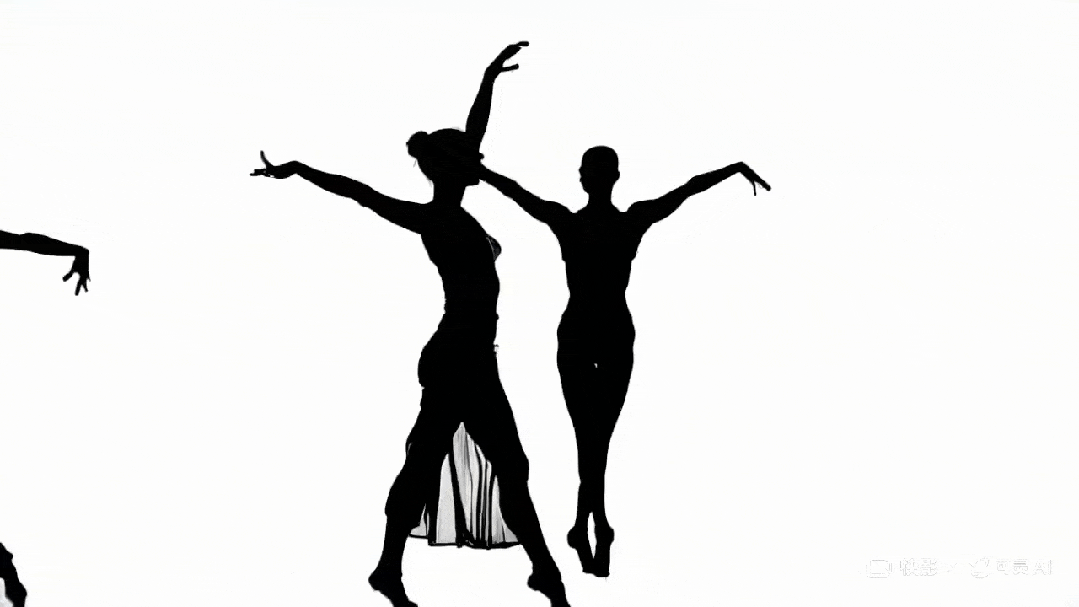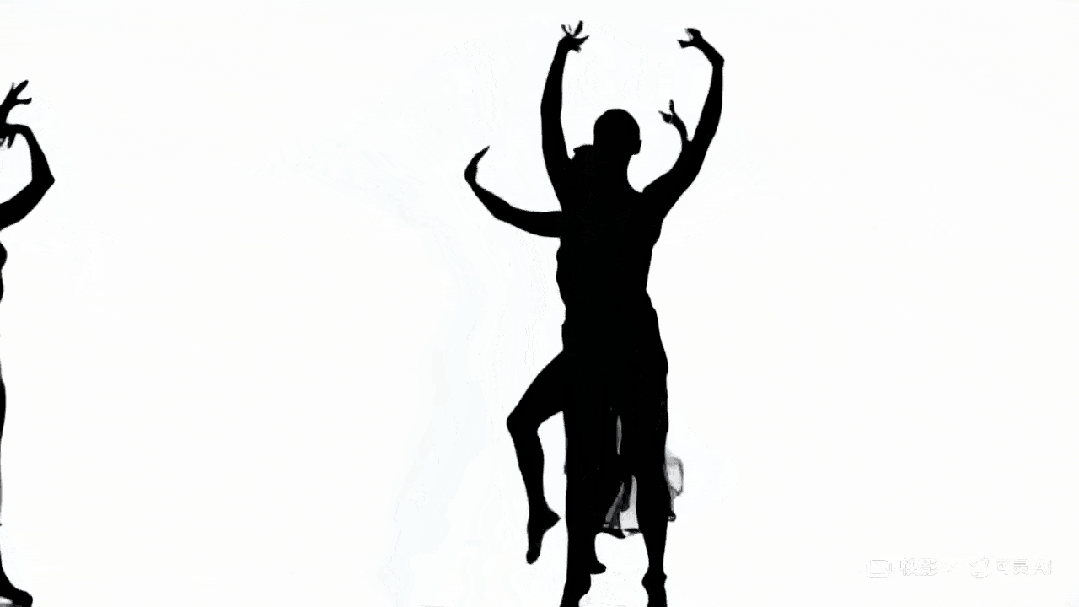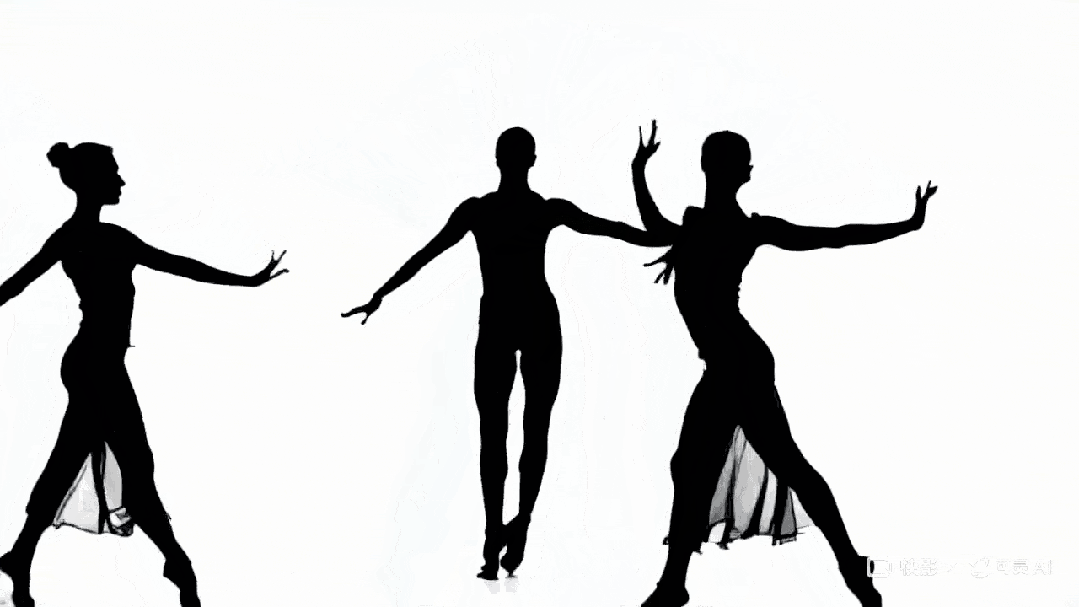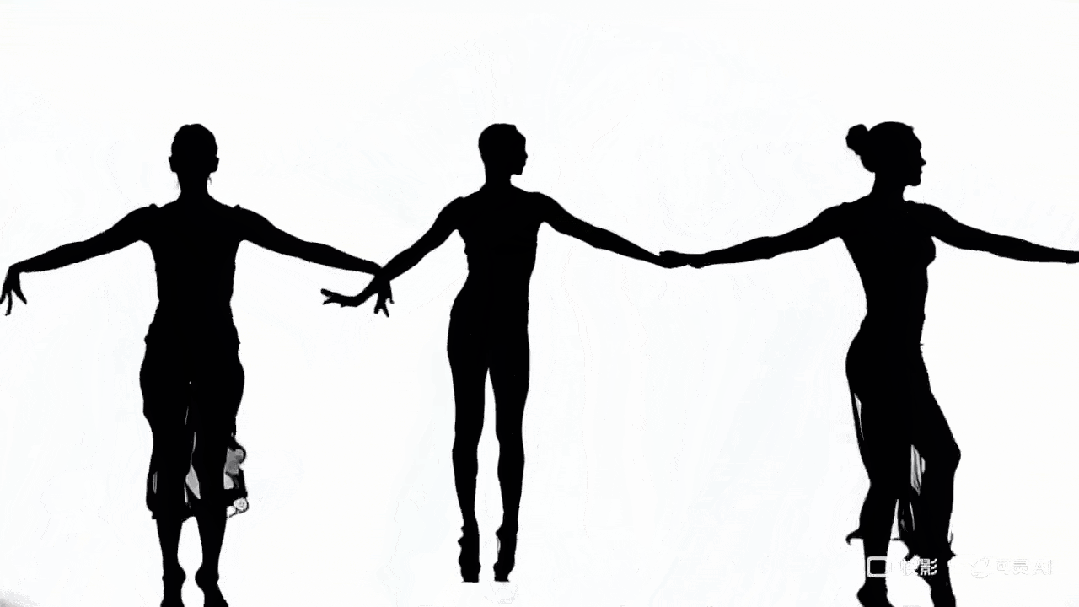
可灵生成作品。图源:https://x.com/dustinhollywood/status/1799970059957555210
科幻电影的风格完全拿捏:

来源:可灵创作者 @狗儿李
AI 同样能为奢侈品大片的制作注入灵感:

来源:可灵创作者 @AI 的小罗
我们可以看一下可灵生成的这段「蜂蜜」广告片,AI 在模拟倾倒蜂蜜特写镜头中的表现丝毫不输专业摄像团队:

可灵背后有哪些技术?
我们无法从 OpenAI 简略的技术报告中获得足够的 Sora 研发细节,但可灵大模型官网却披露了更具参考意义的信息,主要包括从数据准备、模型架构、训练方案及优化策略几个方面。
依托快手在视频技术领域的多年积累,可灵大模型团队已经构建了完备的标签体系,包括从视频基础质量、美学、自然度等多个维度对视频数据质量进行刻画,并针对每一个维度设计多种定制化的标签特征,以此来精细化筛选训练数据或调整训练数据的分布。
为了满足训练文生视频模型过程中成对的视频和文本描述需求,可灵大模型团队自研了视频描述模型,可以生成精确、详尽、结构化的视频描述,显著提升视频生成模型的文本指令响应能力。
高质量的标注数据准备完毕后,可灵大模型又是如何获得模拟物理世界特性与概念组合的能力呢?
在整体架构设计上,可灵采用了目前火热的 Diffusion Transformer (DiT) 。传统的扩散模型主要利用包含下采样和上采样块的卷积 U-Net 作为去噪网络骨干。但一些研究表明,U-Net 架构对扩散模型的良好性能并非至关重要。通过采用更灵活的 Transformer 架构,扩散模型可以使用更多的训练数据和更大的模型参数。DiT 就是这个研究思路下的代表作之一。
这几个月来,业内形成一个共识,视频生成模型的成功,归根结底是 Scaling Law 的作用。这一共识正是基于 DiT 论文的发现,使用 Transformer 能稳定地扩大模型规模:随着训练计算量的增加(训练模型的时间延长或模型增大,或两者兼而有之),性能也会随之提高。
这意味着,对于视频生成模型,只要用更多的算力、更多的数据去 Scale up,生成质量还会持续提升。
可灵之所以能够将用户的文本提示转化为具体的画面,包括那些真实世界中不会出现的虚构场景,就是基于对文本 - 视频语义的深刻理解和 Diffusion Transformer 架构的强大能力。在自研架构和 Scaling Law 激发出的强大建模能力推动下,可灵能够很好地模拟真实世界的物理特性,生成符合物理规律的视频。
与此同时,基于团队自研的 3D VAE 网络,可灵大模型能够生成 1080p 分辨率的电影级视频,无论是浩瀚壮阔的宏大场景,还是细腻入微的特写镜头,都能够生动呈现。

自然场景下,光线的变化很流畅。测试者:@杉杉
当然,对于视频生成模型来说,另一个必须考虑的因素是:视频是一种具有时间维度的视觉内容,不连贯的内容会让用户的观看体验大打折扣。
为了保证画面中运动的呈现更加合理,可灵大模型采用 3D 时空联合注意力机制,更好地建模复杂时空运动,即可生成较大幅度运动的视频内容,同时能够符合运动规律。

训练及优化策略
如果你已经亲自测试过,就会发现可灵支持推理过程中同样的内容输出多种视频宽高比。这是因为可灵采用了可变分辨率的训练策略,目的是满足更丰富场景中的视频素材使用需求。
与此同时,得益于高效的训练基础设施、极致的推理优化和可扩展的基础架构,可灵大模型能够生成长达 2 分钟的视频,且帧率达到 30fps。
视频生成,不再是一场「追赶 OpenAI」的游戏
2024 年被称为视频生成技术的爆发之年,但在可灵之前,我们始终没见到 Sora 级的可用产品,而 Sora 何时开放也是未知数。
某种意义上说,可灵是第一个真正的「中国版 Sora」,并让这项技术真正进入了可用、好用、实用的阶段。
正如傅盛所说:「这可能是今天在全世界范围内,你能够使用到的最好的文生视频产品。」任何亲自试用过可灵的人,都会明白这绝不是过誉。
傅盛的视频还给到了另外一个观点:「反过来也说明,Sora 并不是一个技术性的突破,而是一个产品型的突破。」
还记得几个月前,Sora 以长达 60 秒的连贯视频、高清画面质感、连贯的镜头移动、运动方式等优点,拉高了整个视频生成赛道的技术水平,掀起了文生视频赛道的竞争浪潮。
我们本以为,视频生成领域会像去年的文本大模型一样,演化为国内对海外的技术赶超。但可灵的发布,意味着国产文生视频大模型技术的探索已经达到了一个全新的高度,而且在产品落地层面做到了实质领先。我们可能不需要再重新经历一次「追赶 OpenAI」的游戏了。
有人给出判断:中国正在人工智能领域超越美国。
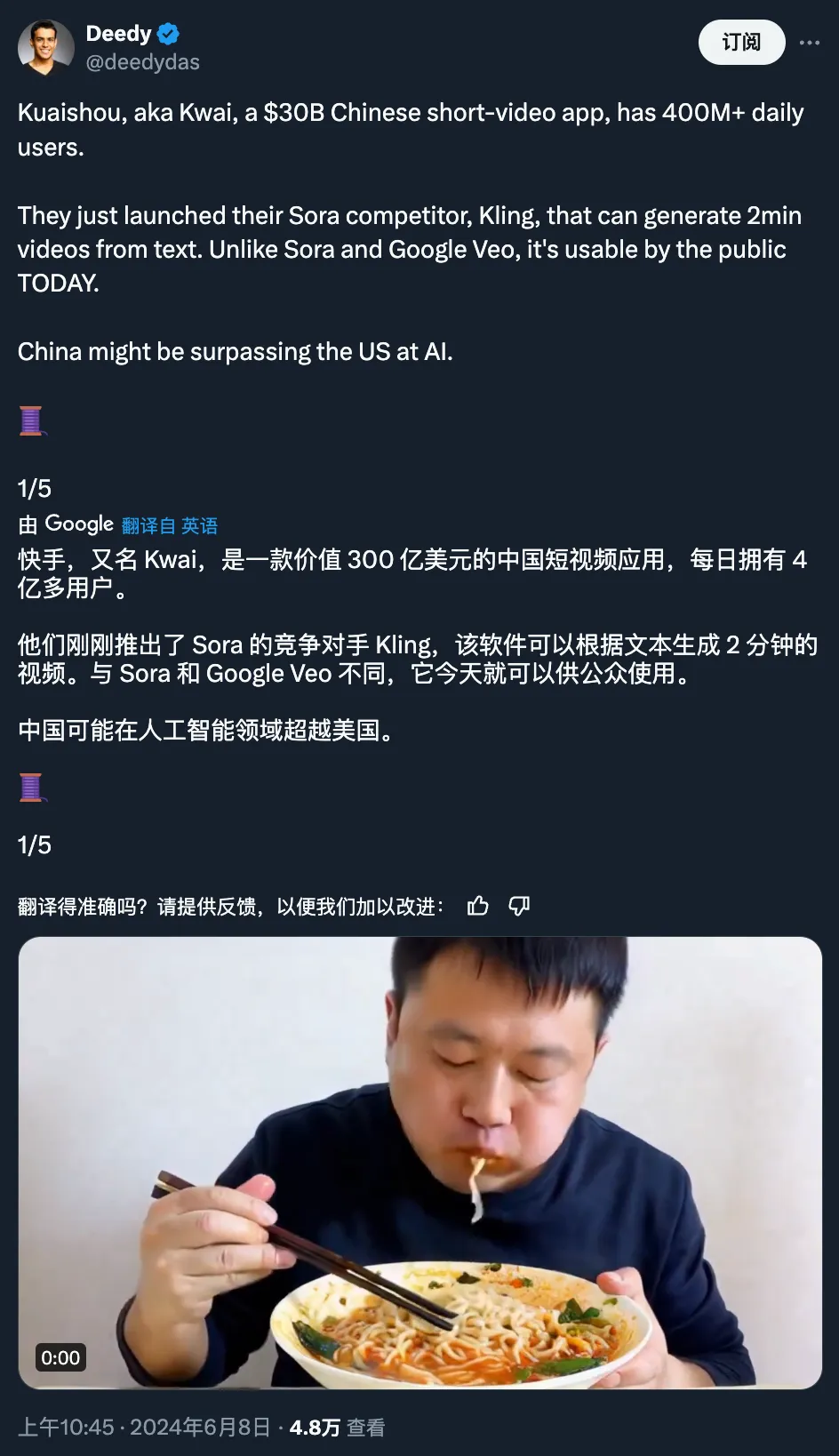
可灵的诞生,或许意味着一个新时代开启了。在生成式 AI 时代,生成和编辑视频或许会像今天我们用手机 P 图一样简单,想象力与现实之间的阻隔将被彻底打破。
由于太过火爆,目前在排队测试可灵的人数已经超过了 5 万人。如果你对 AI 生成视频的玩法感兴趣,不妨先关注「可灵 AI 视频号」,收获更多优质案例。

文章来自于微信公众号 “机器之心”,作者 “蛋酱”



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
