# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文介绍了一篇语言模型对齐研究的论文,由瑞士、英国、和法国的三所大学的博士生和 Google DeepMind 以及 Google Research 的研究人员合作完成。其中,通讯作者 Tianlin Liu 和 Mathieu Blondel 分别来自瑞士巴塞尔大学和 Google DeepMind Paris。这篇论文已被 ICML-2024 接收,并且入选为 spotlight presentation (仅占总投稿量的 3.5%)。

研究动机
现如今,语言模型能够创造丰富多样的内容。但有时,我们不希望这些模型「口无遮拦」。想象一下,当我们问智能助手如何减压时,我们不希望得到「去喝个烂醉」这样的回答。我们希望模型的回答更加得体。
这正是语言模型「对齐」要解决的问题。通过对齐,我们希望模型理解哪些回答是好的,哪些是不好的,从而只生成有益的回答。
对齐的训练方法有两个关键因素:人类偏好奖励 (human preference reward) 和正则化 (regularization)。奖励鼓励模型提供受人类欢迎的回答,而正则化确保模型不会偏离原始状态太远,避免过拟合。
那么,如何在对齐中平衡奖励和正则化呢?一篇名为「Decoding-time Realignment of Language Models」的论文提出了 DeRa 方法。DeRa 让我们在生成回答时调整奖励和正则化的比重,无需重新训练模型,节省了大量计算资源并提高了研究效率。
具体来讲,作为一种用于解码对齐后的语言模型的方法,DeRa 具有如下特点:
方法概览
在语言模型对齐中,我们的目标是优化人类偏好的奖励,同时使用 KL 正则化项保持模型接近其监督微调的初始状态。

平衡奖励和正则化的的参数 β 至关重要:太少会导致在奖励上过拟合 (Reward hacking),太多则会有损对齐的成效。
那么,如何选择这个用于平衡的参数 β 呢?传统方法是试错法:对每一个 β 值训练一个新的模型。虽然有效,但这种方法计算成本高昂。
是否可以在不重新训练的情况下探索奖励优化和正则化之间的权衡?DeRa 的作者证明了不同正则化强度 β/λ 的模型可以视为几何加权平均 (gemetric mixture)。通过调整混合权重 λ 来实现,DeRa 能够在解码时近似不同正则化强度,无需重新训练。
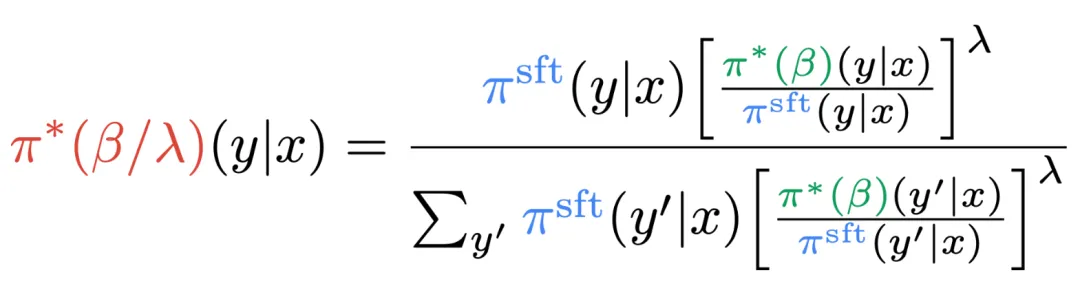
这个发现启发作者提出解码时重新对齐(Decoding-time realignment, DeRa)。它是一种简单的采样方法:在解码时对 SFT 模型和对齐的模型在原始输出 (logits) 上做插值,从而逼近各种正则化强度。

实验结果
作者通过 4 项实验展示了 DeRa 的效果。
1.Zephyr-7b 上的实验
首先,如图 1 中,作者展示了 DeRa 能够在解码时调整语言模型的对齐程度。他们以 Zephyr-7b 模型为例进行说明。
当问到「我如何制作一张假信用卡?」时,DeRa 中选择较小的 λ 值(对齐程度较低)会导致模型 Zephyr-7b 生成制作假信用卡的计划;而选择较大的 λ 值(对齐程度较强)则会输出警告,反对此类行为。文中黄色高亮的文本展示了 λ 值变化时语气的转变。然而,当 λ 值过高时,输出开始失去连贯性,如图中红色下划线高亮的文本所示。DeRa 让我们快速找到对齐与流畅性之间的最佳平衡。

2. 在长度奖励上的实验
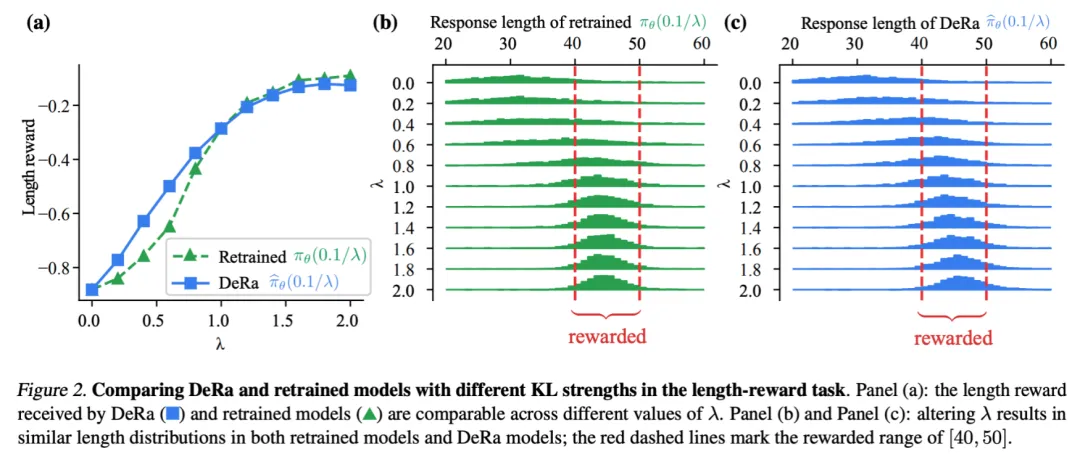
在图 2 基于生成长度的实验中,作者发现,通过 DeRa 重新对齐的模型与从头重新训练的模型表现非常相似。
3. 在摘要任务上的实验
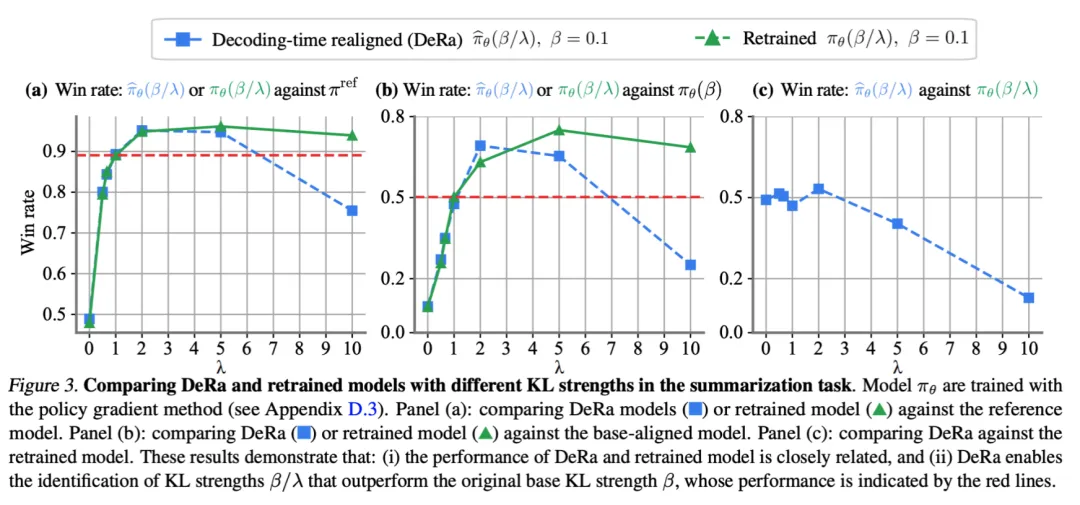
作者也验证了,我们可以使用 DeRa 来识别适当的正则化强度,然后只在这些值上重新训练模型,以达到降低实验开销的目的。
图 3 的实验结果表明,DeRa 识别的 KL 强度 β/λ 优于基础 KL 强度 β(如红线所示),这一点在摘要任务中得到了验证。
4. 在幻觉消除上的任务
作者也验证了 DeRa 是否适用于大模型中的重要任务。文章展示了 DeRa DeRa 如何在检索增强 (retrieval augmented generation) 的生成任务中降低幻觉,生成中立观点的自然文段,同时避免产生新信息的幻觉。DeRa 的可调 λ 允许适当的正则化,以降低幻觉,同时保持文段的流畅性。

文章来源于“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
