# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
互相检查,让小模型也能解决大问题。
众所周知,LLM 很强大,但执行复杂推理的能力还不够强。
举个例子,在 GSM8K 数据集上,Mistral-7B 即使使用思维链(CoT)等技术,也只能达到 36.5% 的准确度。尽管微调确实也能有效地提升推理能力,但大多数 LLM 依靠的微调数据都是经过 GPT-4 等更强大模型蒸馏过的,甚至可能原本就是这些强大模型合成的。
同时,研究者们也在积极开发一种能提供辅助但也更困难的方法:使用一个更优的教师 LLM 来提升推理能力。
为了在没有更优模型的前提下提升推理能力,一种颇有希望的范式是利用 LLM 自身之中的知识。举个例子,一种名为 RAP 的方法采用了一种自我探索式的解决方法,即通过自我奖励的反馈来迭代式地提升 LLM 的推理性能。不幸的是,研究表明这一范式具有两大根本性问题。
第一,在执行推理时,LLM 往往难以有效地探索解答空间。这种自我探索式方法往往会因推理步骤质量不佳而受困于某个解答空间,即使多次尝试也是如此。
第二,即使自我探索找到了高质量的推理步骤,小版本的大型语言模型(SLM)也难以辨别哪些推理步骤的质量更高,也难以确定最终答案是否正确,由此难以有效地引导自我探索。研究表明,基于基本的常规奖励的自我探索引导得到的结果并不比随机猜测更好。
更麻烦的是,小版本的大型语言模型(SLM)更容易出现上述两个问题,因为它们的能力更差一些。举个例子,GPT-4 能通过自我优化来提升输出结果,但 SLM 却很难做到这一点,甚至可能导致输出结果质量下降。这会严重妨碍神经语言模型的推广应用。
针对这些问题,微软亚洲研究院和哈佛大学的一个研究团队提出了 Self-play muTuAl Reasoning,即自博弈相互推理,简称 rStar。简单来说,该方法就类似于让两个学习平平的人互相检查考卷答案,最终提升得分,甚至达到比肩学霸的程度。该团队宣称 rStar 「无需微调或更优模型就能提升 SLM 的推理能力」。

方法
为了解决上述难题,rStar 的做法是将推理过程分成了解答生成和相互验证两部分,如图 2 所示。
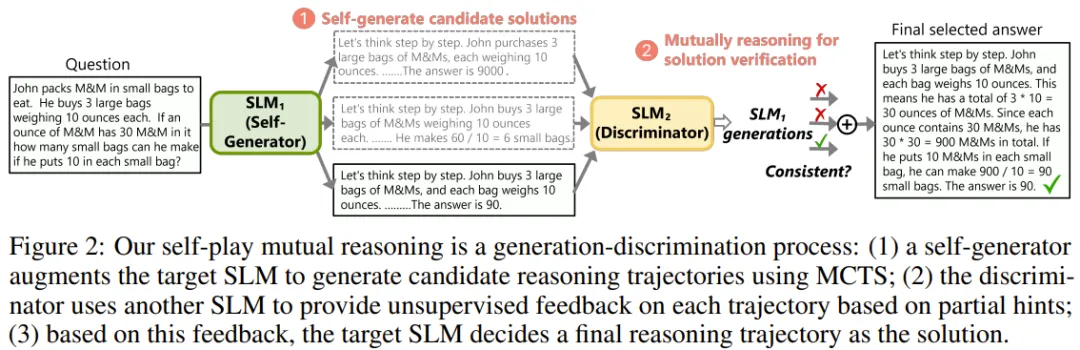
针对第一个难题,该团队引入了一个集合,其中包含丰富的类似人类的推理动作,可透彻地探索多种不同的推理任务空间。
针对第二个难题,他们设计了一个专门针对 SLM 的奖励函数,这能对中间步骤进行评估,从而避免依赖它们那往往并不可靠的自我评估。
此外,该团队还使用了另一个 SLM 作为判别器来增强 MCTS 过程,与判别器 SLM 互相验证每条轨迹的正确性。
使用 MCTS Rollout 自己生成推理轨迹
一个包含丰富的类人推理动作的集合。MCTS 生成的核心在于动作空间,其定义了树探索的范围。大多数基于 MCTS 的方法在构建树时都使用了单一动作类型。比如 RAP 中的动作是提出下一个子问题,而 AlphaMath 和 MindStar 中的动作是生成下一推理步骤。但是,依赖单一动作类型可能容易导致空间探索效果不佳。
为了解决这个问题,该团队回顾了人类执行推理的方法。不同的人解决问题的方法也不同:某些人会将问题分解成子问题,另一些则会直接解决问题,还有些人则会换个视角重新表述问题。此外,人们还会根据当前状态调整自己的方法,按需求选择不同的动作。
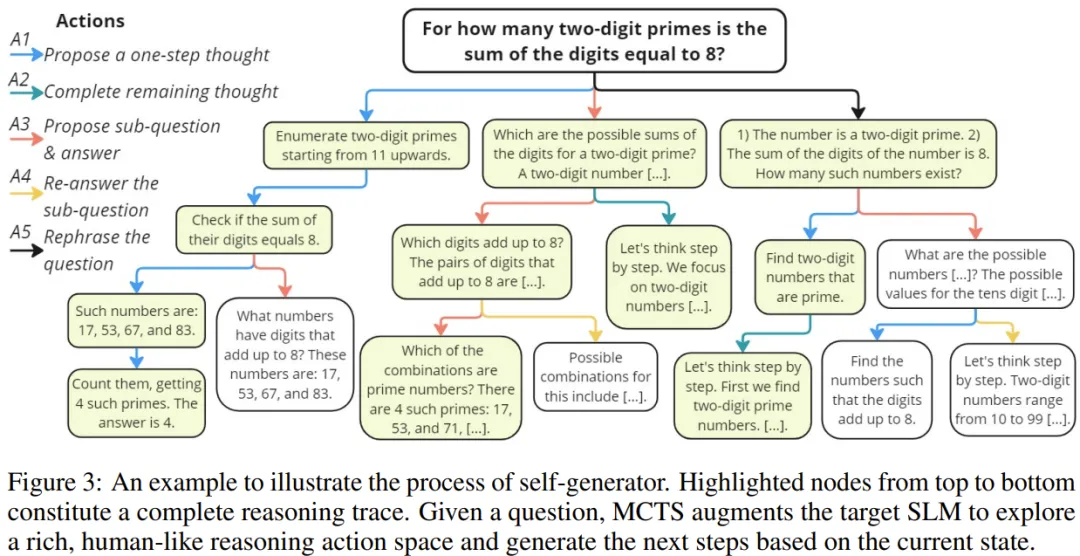
受人类推理过程的启发,该团队构建了一个更为丰富的数据集,其中包含 5 类动作,以尽可能地提升 SLM 正确解决复杂推理问题的潜力。
动作 1:提议一步思路。针对给定问题,该动作会让 LLM 基于已有的推理步骤生成接下来的一步思路。
动作 2:提议余下的思路步骤。该动作与标准 CoT 一样,能实现「快速思考」,从而解决只需少量步骤的简单问题。给定已经生成的推理步骤,它会让 LLM 直接生成剩余步骤,直到得到最终答案。
动作 3:提议下一个子问题及其答案。
动作 4:再次回答这个子问题。考虑到动作 3 有可能无法正确回答对应的子问题,因此这个动作的作用是再次回答它。
动作 5:重新表述问题 / 子问题。这个新动作是以更简单的方式重新表述该问题。具体来说,这里是让 LLM 清晰列出问题陈述中的所有条件。
以上五个动作定义了一个高度多样化的动作空间 {A1, A2, A3, A4, A5}。
在每个步骤 i,MCTS 从该空间选取一个动作 a_i。然后基于当前状态(即之前生成的轨迹 x ⊕ s_1 ⊕ s_2 ⊕ ... ⊕ s_{i−1}),使用该动作 a_i 让 LLM 生成下一推理步骤 s_i。请注意某些动作需要按顺序执行。图 3 给出了一个示例。
如表 1 所示,在提升最终推理准确度方面,每个动作都具有重要作用。

MCTS 的另一个关键组件是奖励函数,其作用是评估每个动作的价值并为树的扩展提供指示。针对 SLM,该团队设计了一个简单却有效的奖励函数。他们的方法灵感来自 AlphaGo,即基于每个中间节点对最终正确答案的贡献对它们进行评分。这样一来,经常得到正确答案的动作就能获得更高奖励,它们也就更可能在未来的 MCTS 树扩展中被选取。
这里将执行动作 a 后生成的节点 s 的奖励值定义为 Q (s, a)。一开始,所有未被探索过的节点都被分配了 Q (s_i, a_i) = 0,从而实现随机的树扩展。在抵达首个端节点 n_d 时,根据其是否得到正确答案而计算一个奖励分数 Q (s_d, a_d)。
然后,沿轨迹 t = x ⊕ s_1 ⊕ s_2 ⊕ ... ⊕ s_d 将该分数反向传播给每个中间节点。具体来说,对于每个 s_i,都以如下方式更新其 Q 值:Q (s_i, a_i) = Q (s_i, a_i) + Q (s_d, a_d)。为了计算端节点的 Q (s_d, a_d),这里使用的奖励值是自洽多数投票的似然(置信度)。
下面描述 MCTS 生成候选推理轨迹的方式。从初始的根节点 s_0 开始,执行包括选取、扩展、模拟和反向传播在内的多种搜索。具体来说,模拟使用的是默认的 Rollout 策略。为了得到更准确的奖励估计,该团队会执行多次 Rollout。为了平衡探索与利用,他们使用了著名的 UCT(树的置信度上界)来选取每个节点。这个选取过程的数学形式为:
其中 N (s, a) 是之前的迭代中节点 s 被访问的次数,N_parent (s) 表示对 s 的父节点的访问次数。Q (s, a) 是估计的奖励值,会在反向传播过程中得到更新。c 是平衡探索与利用的常量。
一旦搜索到达某个端节点(可能是一个终端状态,也可能到达了预定义的最大树深度 d),便能得到一条从根到端节点的轨迹。将 Rollout 迭代得到的所有轨迹收集起来作为候选解答。接下来就需要对它们进行验证。
使用互恰性选择推理轨迹
基于收集到的所有轨迹,该团队提出使用推理互恰性来选择答案。
如图 2 所示,除了目标 SLM 外,该团队还引入了一个判别器 SLM,其作用是为每个候选轨迹提供外部无监督反馈。
具体来说,对于 t = x ⊕ s_1 ⊕ s_2 ⊕ ... ⊕ s_d,遮掩从某个随机采样的步骤 i 处开始的推理步骤。然后将之前的推理轨迹 t = x ⊕ s_1 ⊕ s_2 ⊕ ... ⊕ s_{i-1} 作为 prompt 提供给判别器 SLM,让其补全剩余步骤。由于将之前的 i-1 个推理步骤作为了提示,因此难度降低了,判别器 SLM 便更有可能给出正确答案。
图 4 中比较了判别器 SLM 补全的答案是否与原始轨迹 t 匹配。如果两者一致,则认为 t 是可以最终选择的已验证轨迹。

由目标 SLM 选取最终轨迹。在对所有候选轨迹使用了推理互恰性之后,再回到目标 SLM,让其从已验证轨迹中选出最终轨迹。为了计算每条轨迹的最终分数,该团队的做法是用其奖励乘以通过 Rollout 得到的其端节点的置信度分数。最终分数最高的轨迹被选作解答。
实验
实验设置
rStar 适用于多种 LLM 和推理任务。该团队评估了 5 个 SLM:Phi3-mini、LLaMA2-7B、Mistral-7B、LLaMA3-8B、LLaMA3-8B-Instruct。
测试的推理任务有 5 个,其中包括 4 个数学任务(GSM8K、GSM-Hard、MATH、SVAMP)和 1 个常识任务(StrategyQA)。
实验细节请访问原论文。
主要结果
该团队首先评估了 rStar 在一般推理基准上的有效性。表 2 比较了 rStar 和其它当前最佳方法在不同 SLM 和推理数据集上的准确度。为了演示新生成器的效果,该团队还提供了 rStar (generator @maj) 的准确度,即不使用判别器,仅使用多数投票来验证答案而得到的准确度。
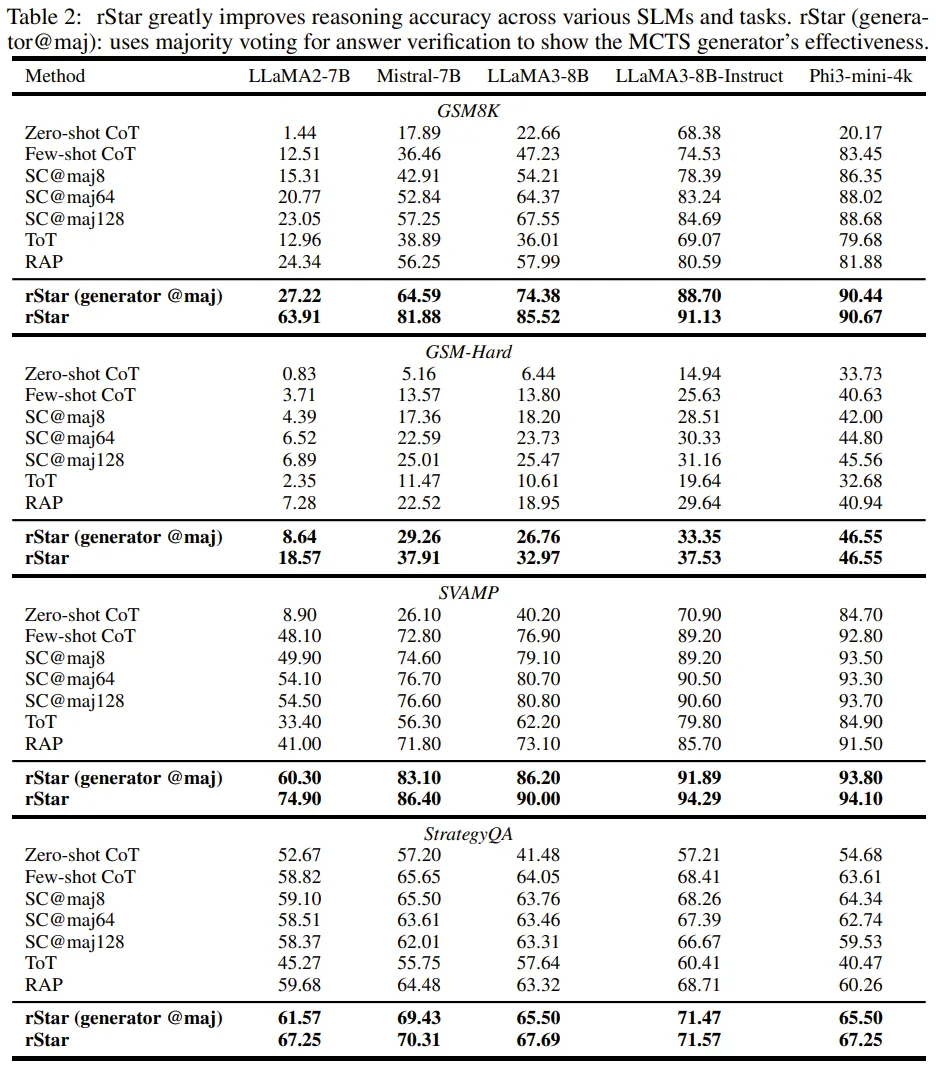
该团队指出了其中的三项关键结果:
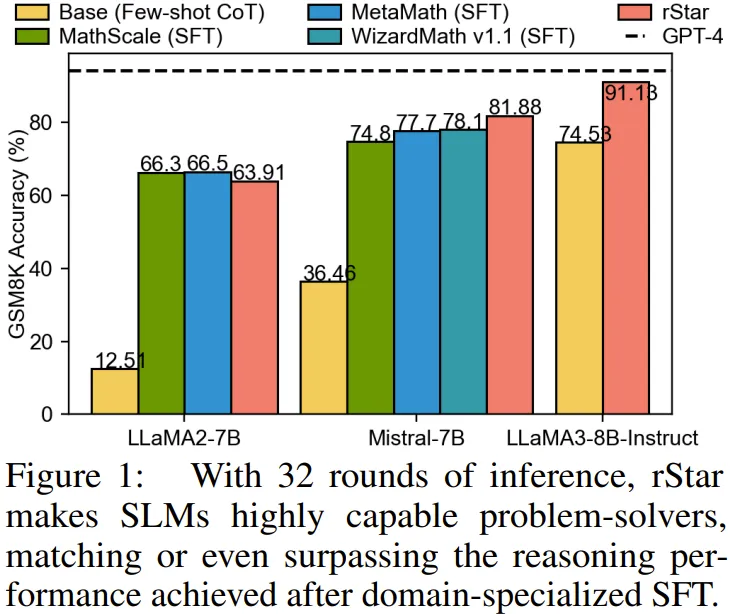
1. 得到 rStar 助力的 SLM 解决问题的能力更强。比如,在 GSM8K 数据集上,使用少样本 CoT 的 LLaMA2-7B 的准确度只有 12.51%。但有了 rStar 的帮助,其准确度提升到了 63.91%,这一成绩接近使用微调得到的准确度,如图 1 所示。类似地,使用 rStar 的 Mistral 的性能甚至比微调版的 MetaMath 还高 4.18%。这样的提升表明,SLM 本身已经具备很强的推理能力,但需要引导才能生成和选出正确解答。
2.rStar 可以稳定地将被评估的多种 SLM 在不同任务上的推理准确度提升至当前最佳水平。相较之下,其它对比方法都无法稳定地在所有四个基准上取得优良表现。举个例子,尽管 SC(自我一致性)擅长三个数学任务,但却无法有效解决 StrategyQA 的逻辑推理任务。
3. 即使没有新提出的用于验证推理轨迹的判别器,新提出的 MCTS 生成器在提升 SLM 的推理准确度方面依然效果很好。比如,在 GSM8K 数据集上,rStar (generator @maj) 的准确度比 RAP 高 2.88%-16.39%、比 ToT 高 10.60%- 38.37%、比 SC 高 1.69% - 7.34%。
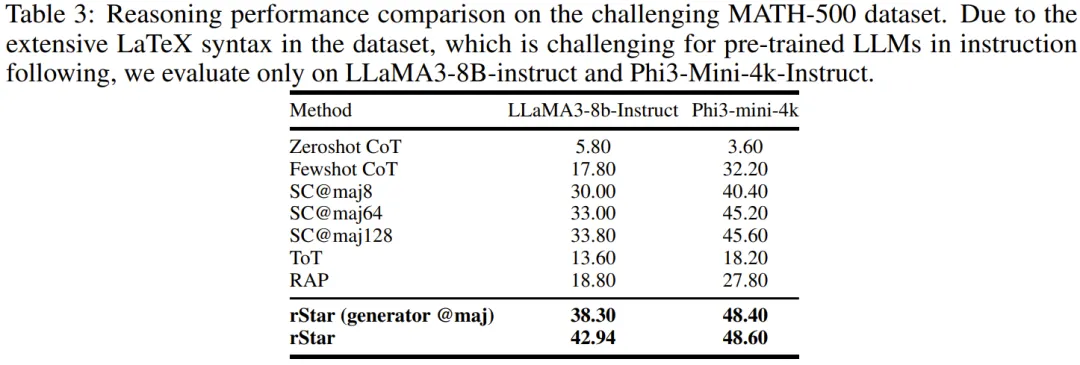
该团队还在一个更高难度的数学数据集上评估了 rStar。为此他们选择了 GSM-Hard 和 MATH 数据集。遵照同类研究的惯例,他们使用了 MATH-500,这是来自 MATH 数据集的一个包含代表性问题的子集。这样做是为了提升评估速度。如表 2 和 3 所示,rStar 能够显著提高 SLM 在这些高难度数学数据集上的推理准确度。
消融研究
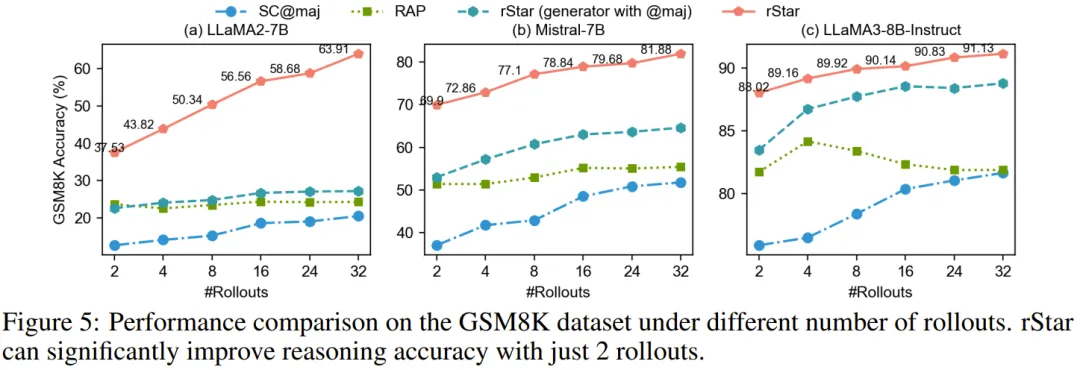
rStar 使用了 Rollout 策略来执行 MCTS 树扩展。更多 Rollout 会生成更多候选解答轨迹,但也会抬高推理成本。图 5 比较了在 GSM8K 上,SC、RAP 和 rStar 使用不同 Rollout 时的准确度。
这里得到两个关键观察结果:
1. 即使仅 2 次 Rollout,rStar 也能大幅提升 SLM 的推理准确度,这表明了其有效性;
2.Rollout 更多时对 rStar 和 SC 都有利,而 RAP 在 4 次 Rollout 之后往往会饱和甚至下降。一个原因是 RAP 的单类型动作空间会限制 MCTS 探索的效果。
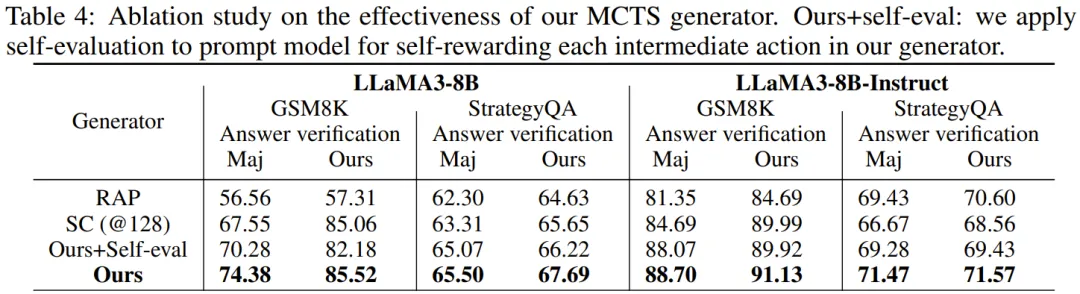
该团队比较了 MCTS 生成器与其它三种生成器的效果。如表 4 所示,新提出的 MCTS 生成器全面胜过其它生成器。此外,针对 SLM 调整过的奖励函数的有效性也得到了证明,因为自我评估会降低新生成器的准确度。
该团队设置了两个评估实验。
第一个实验是将判别方法与多数投票和自我验证方法进行比较。结果见表 5(左),可以看到判别方法的优势非常显著。

第二个实验则是研究不同的判别器模型的影响。结果见表 5(右),可以看到选择不同的判别器模型通常不会影响推理互恰性方法验证答案的效果。值得注意的是,即使使用强大的 GPT-4 作为判别器,性能也只有略微提升(从 91.13% 提升到 92.57%)。这表明推理互恰性方法可以有效地使用 SLM 来验证答案。
文章来源于“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
